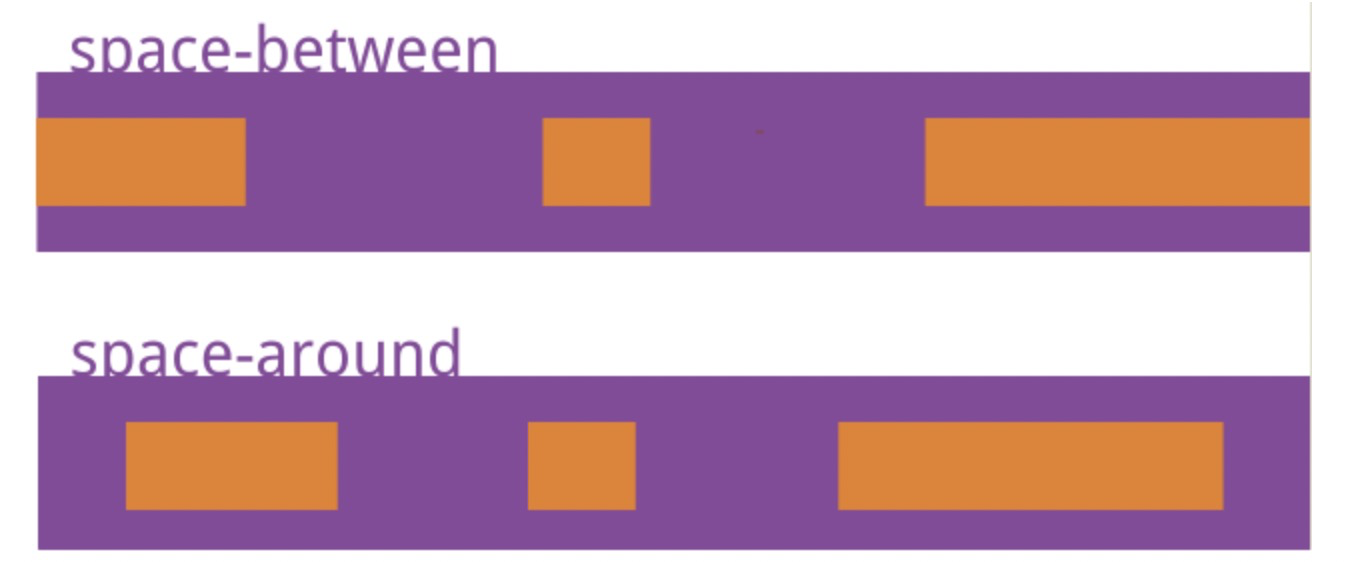
自动驾驶-如何进行多传感器的融合

附赠自动驾驶学习资料和量产经验:链接
引言
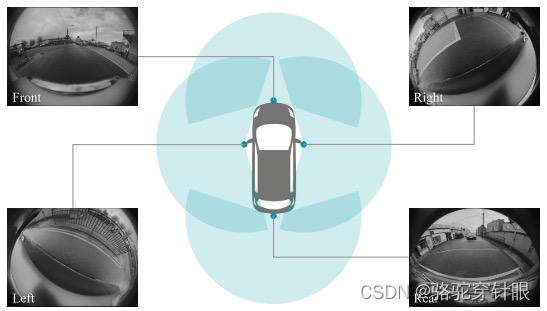
自动驾驶中主要使用的感知传感器是摄像头和激光雷达,这两种模态的数据都可以进行目标检测和语义分割并用于自动驾驶中,但是如果只使用单一的传感器进行上述工作的话,很难应付极端或复杂路况。因此,多传感器融合被认为是实现L3级别以上自动驾驶的优秀方案。

1.多传感器开源数据

多传感器开源数据汇总
2.融合策略概述
传统划分传感器融合的分类主要是前融合,深度特征融合和后融合。但是这种划分方法不够细致,最近很多论文的多传感器融合也突破了上述三个划分的边界。因此,提出一种新的方案.

策略概述
主要分为强融合和弱融合两个方面,强融合包括前融合,深度特征融合,不对称融合和后融合。下面继续引用论文的图表进行表述。
3.融合策略详细分类
**前融合:**如下图所示,前融合是一种数据层面上的融合策略,并且这种融合策略以激光雷达的数据为主,摄像头的数据为辅。利用摄像头的数据获取不带距离信息的语义分割结果来融合点云的原始数据,简单粗暴。

前融合
深度特征融合:原始文章用的deep-fusion来进行表述,我的理解是深度特征,也就是两种不同传感器经过计算后的feature map或者tensor,对于点云来说可以使用voxel-base的算法进行处理得出特征空间和图像的feature map进行融合。这种方法使整个自动驾驶的感知更加紧凑,也是目前很多学者在尝试的方案之一!

深度特征融合
**后融合:**就是两种传感器分别进行计算得出检测或分割的结果,然后在根据多传感器标定的情况进行结果的融合。目前百度pollo等很多大厂开源或者路测的方案多基于此,比较直观也最能快速工程化实现的方案。但是我在工作中发现这种方案会放大不同传感器的固有缺陷(比如毫米波虚检对,激光在异常天气不够鲁棒,摄像头缺少深度信息等)。融合策略过于生硬!

后融合
**不对称融合:**我的理解是不同阶段进行进行的融合,比如利用激光雷达计算后物体的proposal与图像在feature map阶段进行融合,不同点是feature map阶段比proposal阶段更抽象,然后进行tensor融合,最后进行解码得出结果。这种方案更多是在实际应用中尝试发现,好与不好要更多的去尝试!

弱融合:弱融合和上述不同,既不是数据也不是特征层面不同阶段的融合,而是一种学习策略上的融合,用一个信号监督另外一个模态数据的模型学习结果,以这种方式弱化有监督学习对大规模标签的依赖,毕竟都得花钱标注不是。现有研究领域中有些深度估计方面的论文用的就是类似的方法,很有研究价值的一个方案!
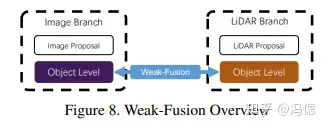
弱融合
**结论:**融合策略千万条,安全第一条,融合不规范,亲人两行泪!
上述论文的理解包含部分自己的观点,请谨慎食用!
论文地址:
Multi-modal Sensor Fusion for Auto Driving Perception: A Surveyarxiv.org/pdf/2202.02703.pdf

































![[leetcode]118.杨辉三角](https://img-blog.csdnimg.cn/img_convert/968c63e11a472f70579cf6ff3dab671d.png)