机器学习可以根据学习的方式、使用的数据类型以及预测任务的性质等多个维度进行分类。以下是几种主要的机器学习分类的详细论述:
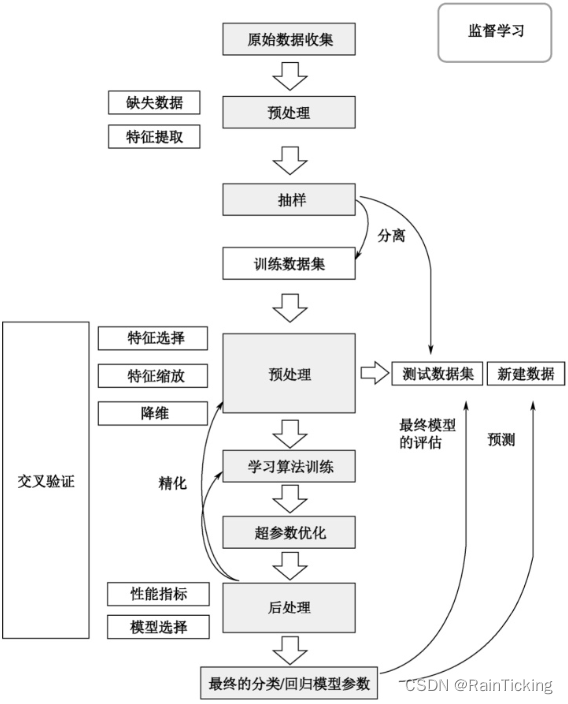
1. 监督学习(Supervised Learning)
- 定义:在监督学习中,模型通过一组带有标签的训练数据进行学习。每个训练样本都包含一个输入对象(通常是一个特征向量)和一个期望的输出值(标签)。模型的目的是学会预测未见过数据的标签。
- 应用:分类(Classification)、回归(Regression)等任务。例如,邮件的垃圾邮件分类、房价的预测。
- 优点:由于提供了明确的指导,监督学习模型通常能够达到较高的准确率。
- 缺点:需要大量的标注数据,数据标注往往成本高昂。
2. 无监督学习(Unsupervised Learning)
- 定义:无监督学习不使用带标签的数据。模型试图自己找出数据的结构,通常用于发现数据中的隐藏模式或进行数据压缩。
- 应用:聚类(Clustering)、降维(Dimensionality Reduction)、关联规则学习(Association Rule Learning)等。例如,客户细分、特征压缩。
- 优点:不需要标注数据,可以处理未标注的数据集。
- 缺点:模型的性能难以评估,因为没有明确的正确答案作为参照。
3. 半监督学习(Semi-supervised Learning)
- 定义:半监督学习介于监督学习和无监督学习之间,使用少量的标注数据和大量的未标注数据进行模型训练。
- 应用:通常用于标签获取成本高但未标注数据又充足的情况。例如,文本分类、图像识别。
- 优点:减少了标注数据的需求,同时可以提高模型的性能。
- 缺点:需要合适的策略来结合标注数据和未标注数据。
4. 强化学习(Reinforcement Learning)
- 定义:强化学习是一种让机器通过试错来学习特定任务的算法,目标是找到在给定环境下达成目标的最佳策略。
- 应用:游戏(如AlphaGo)、自动驾驶、推荐系统等。在这些应用中,算法通过与环境的交互来学习最优行为。
- 优点:能够在复杂的、未知的或不确定的环境中学习策略。
- 缺点:需要大量的交互数据,且训练过程可能非常耗时和资源密集。
5. 自监督学习(Self-supervised Learning)
- 定义:自监督学习是一种特殊类型的无监督学习,其中模型通过自动生成的伪标签进行训练。这种方法试图通过数据本身来学习表示,而不需要显式的外部标注。
- 应用:自然语言处理(NLP)、计算机视觉等领域,用于预训练大型模型,如BERT、GPT等。
- 优点:可以利用大量未标注数据,学习到数据的深层次表示。
- 缺点:模型可能需要大量计算资源进行预训练。