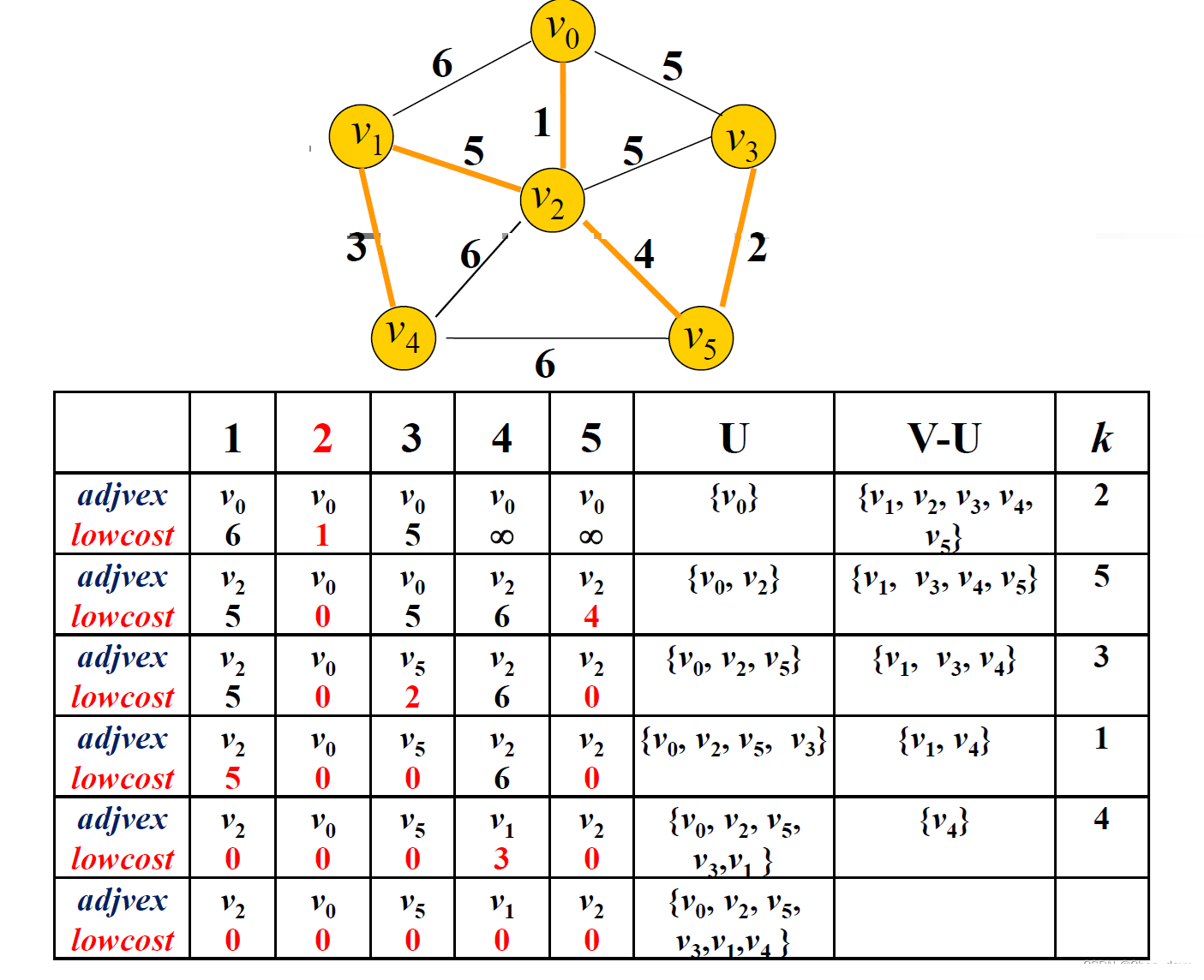
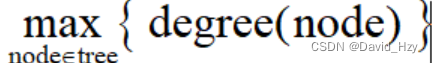图
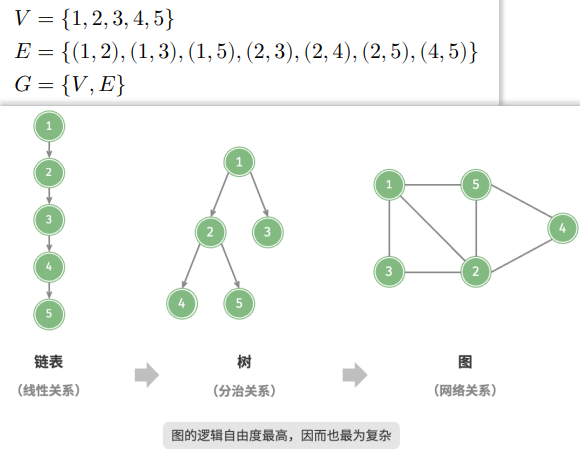
图(graph)是一种非线性数据结构,由顶点(vertex)和边(edge)组成。可以将图 𝐺 抽象地表示为一组顶点 𝑉 和一组边 𝐸 的集合。
如果将顶点看作节点,将边看作连接各个节点的引用(指针),就可以将图看作一种从链表拓展而来的数据结构。
相较于线性关系(链表)和分治关系(树),网络关系(图)的自由度更高,因而更为复杂。
图的常见类型与术语
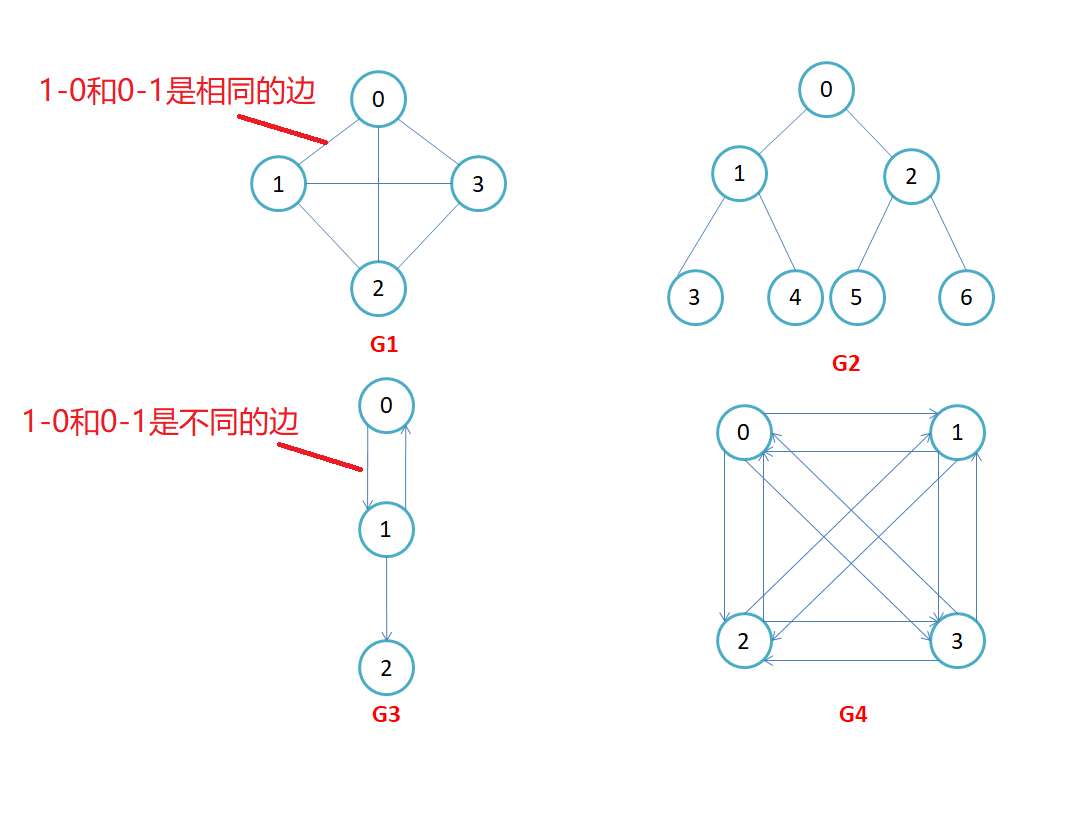
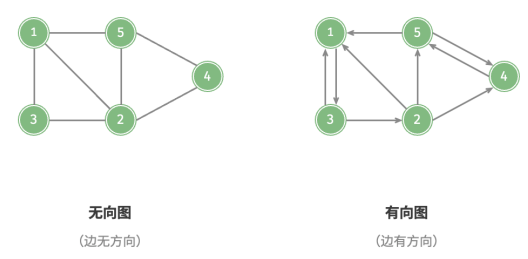
根据边是否具有方向,可分为无向图和有向图。
在无向图中,边表示两顶点之间的“双向”连接关系;
在有向图中,边具有方向性,即 𝐴 → 𝐵 和 𝐴 ← 𝐵 两个方向的边是相互独立的。
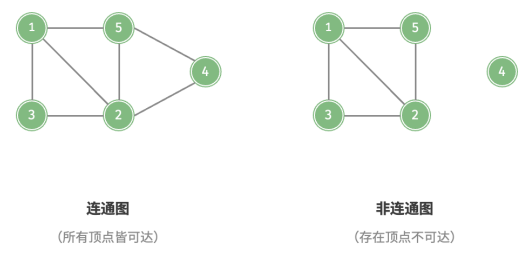
根据所有顶点是否连通,可分为连通图和非连通图
还可以为边添加“权重”变量,从而得到有权图。

图数据结构包含以下常用术语:
邻接(adjacency):当两顶点之间存在边相连时,称这两顶点“邻接”。
路径(path):从顶点 A 到顶点 B 经过的边构成的序列被称为从 A 到 B 的“路径”。
度(degree):一个顶点拥有的边数。
图的表示
邻接矩阵
设图的顶点数量为 𝑛 ,邻接矩阵 使用一个 𝑛 × 𝑛 大小的矩阵来表示图,每一行(列)代表一个顶点,矩阵元素代表边,用 1 或 0 表示两个顶点之间是否存在边。
设邻接矩阵为 𝑀、顶点列表为 𝑉 ,那么矩阵元素 𝑀[𝑖, 𝑗] = 1 表示顶点 𝑉 [𝑖] 到顶点 𝑉 [𝑗] 之间存在边,反之 𝑀[𝑖, 𝑗] = 0 表示两顶点之间无边。
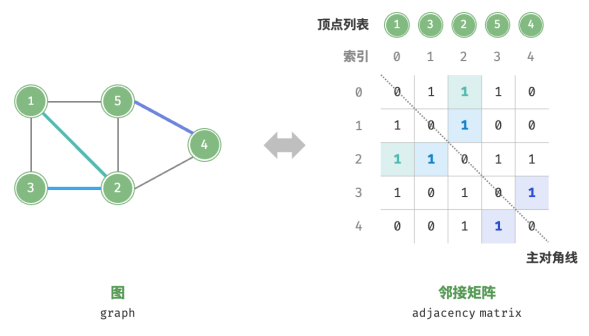
邻接矩阵具有以下特性:
1.顶点不能与自身相连,因此邻接矩阵主对角线元素没有意义;
2.对于无向图,两个方向的边等价,此时邻接矩阵关于主对角线对称;
3.将邻接矩阵的元素从 1 和 0 替换为权重,则可表示有权图。
使用邻接矩阵表示图时,可以直接访问矩阵元素以获取边,因此增删查改操作的效率很高,时间复杂度均为 𝑂(1) 。然而,矩阵的空间复杂度为 𝑂(𝑛^2) ,内存占用较多。
邻接表
邻接表使用 𝑛 个链表来表示图,链表节点表示顶点。第 𝑖 个链表对应顶点 𝑖 ,其中存储了该顶点的所有邻接顶点(与该顶点相连的顶点)。

邻接表仅存储实际存在的边,而边的总数通常远小于 𝑛^2 ,因此它更加节省空间。然而,在邻接表中需要通过遍历链表来查找边,因此其时间效率不如邻接矩阵。
邻接表结构与哈希表中的“链式地址”非常相似,因此也可以采用类似的方法来优化效率。比如当链表较长时,可以将链表转化为 AVL 树或红黑树,从而将时间效率从 𝑂(𝑛) 优化至 𝑂(log 𝑛) ;还可以把链表转换为哈希表,从而将时间复杂度降至 𝑂(1) 。
图的常见应用

图的基础操作
图的基础操作可分为对“边”的操作和对“顶点”的操作。
在“邻接矩阵”和“邻接表”两种表示方法下,实现方式有所不同。
基于邻接矩阵的实现
给定一个顶点数量为 𝑛 的无向图:
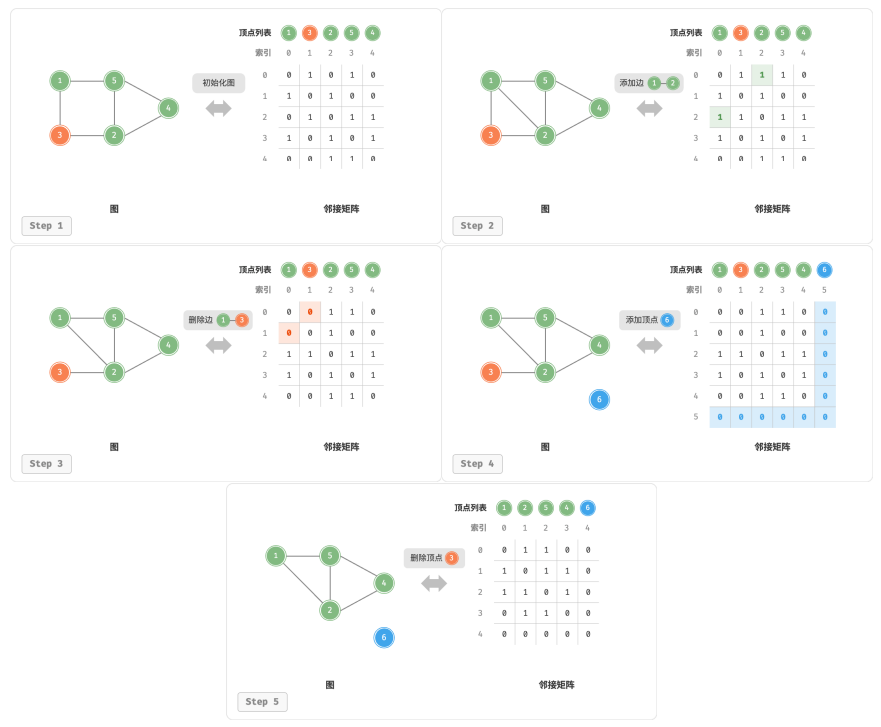
添加或删除边: 直接在邻接矩阵中修改指定的边即可,使用 𝑂(1) 时间。而由于是无向图,因此需要同时更新两个方向的边。
添加顶点: 在邻接矩阵的尾部添加一行一列,并全部填 0 即可,使用 𝑂(𝑛) 时间。
删除顶点: 在邻接矩阵中删除一行一列。当删除首行首列时达到最差情况,需要将 (𝑛 − 1)^ 2 个元素“向左上移动”,从而使用 𝑂(𝑛^2) 时间。
初始化: 传入 𝑛 个顶点,初始化长度为 𝑛 的顶点列表 vertices ,使用 𝑂(𝑛) 时间;初始化 𝑛 × 𝑛 大小的邻接矩阵 adjMat ,使用 𝑂(𝑛^2) 时间。
/**
* File: graph_adjacency_matrix.cpp
* Created Time: 2023-02-09
* Author: what-is-me (whatisme@outlook.jp)
*/
#include "../utils/common.hpp"
/* 基于邻接矩阵实现的无向图类 */
class GraphAdjMat {
vector<int> vertices; // 顶点列表,元素代表“顶点值”,索引代表“顶点索引”
vector<vector<int>> adjMat; // 邻接矩阵,行列索引对应“顶点索引”
public:
/* 构造方法 */
GraphAdjMat(const vector<int> &vertices, const vector<vector<int>> &edges) {
// 添加顶点
for (int val : vertices) {
addVertex(val);
}
// 添加边
// 请注意,edges 元素代表顶点索引,即对应 vertices 元素索引
for (const vector<int> &edge : edges) {
addEdge(edge[0], edge[1]);
}
}
/* 获取顶点数量 */
int size() const {
return vertices.size();
}
/* 添加顶点 */
void addVertex(int val) {
int n = size();
// 向顶点列表中添加新顶点的值
vertices.push_back(val);
// 在邻接矩阵中添加一行
adjMat.emplace_back(vector<int>(n, 0));
// 在邻接矩阵中添加一列
for (vector<int> &row : adjMat) {
row.push_back(0);
}
}
/* 删除顶点 */
void removeVertex(int index) {
if (index >= size()) {
throw out_of_range("顶点不存在");
}
// 在顶点列表中移除索引 index 的顶点
vertices.erase(vertices.begin() + index);
// 在邻接矩阵中删除索引 index 的行
adjMat.erase(adjMat.begin() + index);
// 在邻接矩阵中删除索引 index 的列
for (vector<int> &row : adjMat) {
row.erase(row.begin() + index);
}
}
/* 添加边 */
// 参数 i, j 对应 vertices 元素索引
void addEdge(int i, int j) {
// 索引越界与相等处理
if (i < 0 || j < 0 || i >= size() || j >= size() || i == j) {
throw out_of_range("顶点不存在");
}
// 在无向图中,邻接矩阵关于主对角线对称,即满足 (i, j) == (j, i)
adjMat[i][j] = 1;
adjMat[j][i] = 1;
}
/* 删除边 */
// 参数 i, j 对应 vertices 元素索引
void removeEdge(int i, int j) {
// 索引越界与相等处理
if (i < 0 || j < 0 || i >= size() || j >= size() || i == j) {
throw out_of_range("顶点不存在");
}
adjMat[i][j] = 0;
adjMat[j][i] = 0;
}
/* 打印邻接矩阵 */
void print() {
cout << "顶点列表 = ";
printVector(vertices);
cout << "邻接矩阵 =" << endl;
printVectorMatrix(adjMat);
}
};
/* Driver Code */
int main() {
/* 初始化无向图 */
// 请注意,edges 元素代表顶点索引,即对应 vertices 元素索引
vector<int> vertices = {1, 3, 2, 5, 4};
vector<vector<int>> edges = {{0, 1}, {0, 3}, {1, 2}, {2, 3}, {2, 4}, {3, 4}};
GraphAdjMat graph(vertices, edges);
cout << "\n初始化后,图为" << endl;
graph.print();
/* 添加边 */
// 顶点 1, 2 的索引分别为 0, 2
graph.addEdge(0, 2);
cout << "\n添加边 1-2 后,图为" << endl;
graph.print();
/* 删除边 */
// 顶点 1, 3 的索引分别为 0, 1
graph.removeEdge(0, 1);
cout << "\n删除边 1-3 后,图为" << endl;
graph.print();
/* 添加顶点 */
graph.addVertex(6);
cout << "\n添加顶点 6 后,图为" << endl;
graph.print();
/* 删除顶点 */
// 顶点 3 的索引为 1
graph.removeVertex(1);
cout << "\n删除顶点 3 后,图为" << endl;
graph.print();
return 0;
}
基于邻接表的实现
设无向图的顶点总数为 𝑛、边总数为 m
添加边: 在顶点对应链表的末尾添加边即可,使用 𝑂(1) 时间。因为是无向图,所以需要同时添加两个方向的边。
删除边: 在顶点对应链表中查找并删除指定边,使用 𝑂(𝑚) 时间。在无向图中,需要同时删除两个方向的边。
添加顶点: 在邻接表中添加一个链表,并将新增顶点作为链表头节点,使用 𝑂(1) 时间。
删除顶点: 需遍历整个邻接表,删除包含指定顶点的所有边,使用 𝑂(𝑛 + 𝑚) 时间。
初始化: 在邻接表中创建 𝑛 个顶点和 2𝑚 条边,使用 𝑂(𝑛 + 𝑚) 时间。
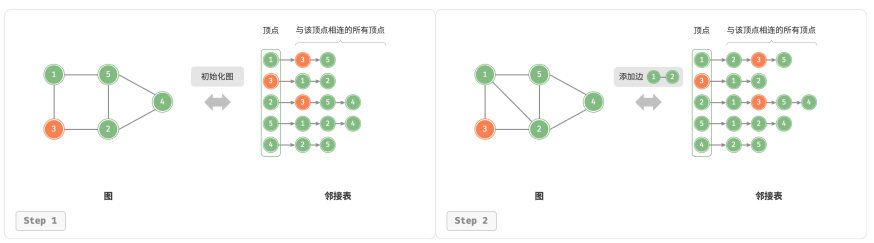
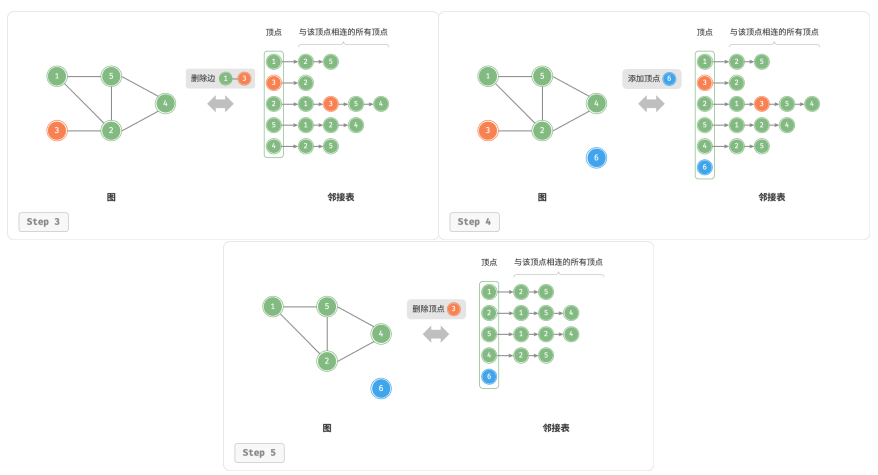
以下是邻接表的代码实现。实际代码有以下不同:
1.为了方便添加与删除顶点,以及简化代码,使用列表(动态数组)来代替链表。
2.使用哈希表来存储邻接表,key 为顶点实例,value 为该顶点的邻接顶点列表(链表)。
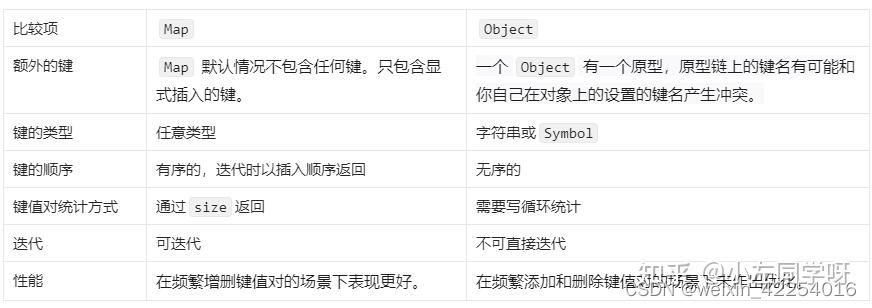
另外,在邻接表中使用 Vertex 类来表示顶点,这样做的原因是:如果与邻接矩阵一样,用列表索引来区分不同顶点,那么假设要删除索引为 𝑖 的顶点,则需遍历整个邻接表,将所有大于 𝑖 的索引全部减 1 ,效率很低。而如果每个顶点都是唯一的 Vertex 实例,删除某一顶点之后就无须改动其他顶点了。
/**
* File: graph_adjacency_list.cpp
* Created Time: 2023-02-09
* Author: what-is-me (whatisme@outlook.jp), Krahets (krahets@163.com)
*/
#include "../utils/common.hpp"
/* 基于邻接表实现的无向图类 */
class GraphAdjList {
public:
// 邻接表,key:顶点,value:该顶点的所有邻接顶点
unordered_map<Vertex *, vector<Vertex *>> adjList;
/* 在 vector 中删除指定节点 */
void remove(vector<Vertex *> &vec, Vertex *vet) {
for (int i = 0; i < vec.size(); i++) {
if (vec[i] == vet) {
vec.erase(vec.begin() + i);
break;
}
}
}
/* 构造方法 */
GraphAdjList(const vector<vector<Vertex *>> &edges) {
// 添加所有顶点和边
for (const vector<Vertex *> &edge : edges) {
addVertex(edge[0]);
addVertex(edge[1]);
addEdge(edge[0], edge[1]);
}
}
/* 获取顶点数量 */
int size() {
return adjList.size();
}
/* 添加边 */
void addEdge(Vertex *vet1, Vertex *vet2) {
if (!adjList.count(vet1) || !adjList.count(vet2) || vet1 == vet2)
throw invalid_argument("不存在顶点");
// 添加边 vet1 - vet2
adjList[vet1].push_back(vet2);
adjList[vet2].push_back(vet1);
}
/* 删除边 */
void removeEdge(Vertex *vet1, Vertex *vet2) {
if (!adjList.count(vet1) || !adjList.count(vet2) || vet1 == vet2)
throw invalid_argument("不存在顶点");
// 删除边 vet1 - vet2
remove(adjList[vet1], vet2);
remove(adjList[vet2], vet1);
}
/* 添加顶点 */
void addVertex(Vertex *vet) {
if (adjList.count(vet))
return;
// 在邻接表中添加一个新链表
adjList[vet] = vector<Vertex *>();
}
/* 删除顶点 */
void removeVertex(Vertex *vet) {
if (!adjList.count(vet))
throw invalid_argument("不存在顶点");
// 在邻接表中删除顶点 vet 对应的链表
adjList.erase(vet);
// 遍历其他顶点的链表,删除所有包含 vet 的边
for (auto &adj : adjList) {
remove(adj.second, vet);
}
}
/* 打印邻接表 */
void print() {
cout << "邻接表 =" << endl;
for (auto &adj : adjList) {
const auto &key = adj.first;
const auto &vec = adj.second;
cout << key->val << ": ";
printVector(vetsToVals(vec));
}
}
};
效率对比
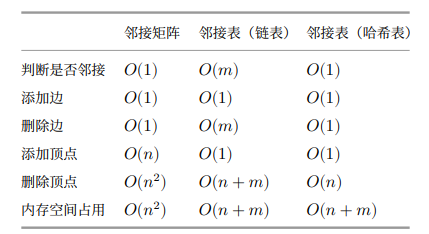
从表上看似乎邻接表(哈希表)的时间效率与空间效率最优。但实际上,在邻接矩阵中操作边的效率更高,只需一次数组访问或赋值操作即可。综合来看,邻接矩阵体现了“以空间换时间”的原则,而邻接表体现了“以时间换空间”的原则。
图的遍历
树代表的是“一对多”的关系,而图则具有更高的自由度,可以表示任意的“多对多”关系。因此,可以把树看作图的一种特例。显然,树的遍历操作也是图的遍历操作的一种特例。
图的遍历方式也可分为两种:广度优先遍历和深度优先遍历。
广度优先遍历
广度优先遍历是一种由近及远的遍历方式,从某个节点出发,始终优先访问距离最近的顶点,并一层层向外扩张。

从左上角顶点出发,首先遍历该顶点的所有邻接顶点,然后遍历下一个顶点的所有邻接顶点,以此类推,直至所有顶点访问完毕。
算法实现
BFS 通常借助队列来实现,代码如下所示。队列具有“先入先出”的性质,这与 BFS 的“由近及远”的思想异曲同工。
1.将遍历起始顶点 startVet 加入队列,并开启循环;
2.在循环的每轮迭代中,弹出队首顶点并记录访问,然后将该顶点的所有邻接顶点加入到队列尾部;
3.循环步骤 2. ,直到所有顶点被访问完毕后结束。
为了防止重复遍历顶点,需要借助一个哈希表 visited 来记录哪些节点已被访问。
/**
* File: graph_bfs.cpp
* Created Time: 2023-03-02
* Author: Krahets (krahets@163.com)
*/
#include "../utils/common.hpp"
#include "./graph_adjacency_list.cpp"
/* 广度优先遍历 */
// 使用邻接表来表示图,以便获取指定顶点的所有邻接顶点
vector<Vertex *> graphBFS(GraphAdjList &graph, Vertex *startVet) {
// 顶点遍历序列
vector<Vertex *> res;
// 哈希表,用于记录已被访问过的顶点
unordered_set<Vertex *> visited = {startVet};
// 队列用于实现 BFS
queue<Vertex *> que;
que.push(startVet);
// 以顶点 vet 为起点,循环直至访问完所有顶点
while (!que.empty()) {
Vertex *vet = que.front();
que.pop(); // 队首顶点出队
res.push_back(vet); // 记录访问顶点
// 遍历该顶点的所有邻接顶点
for (auto adjVet : graph.adjList[vet]) {
if (visited.count(adjVet))
continue; // 跳过已被访问的顶点
que.push(adjVet); // 只入队未访问的顶点
visited.emplace(adjVet); // 标记该顶点已被访问
}
}
// 返回顶点遍历序列
return res;
}
/* Driver Code */
int main() {
/* 初始化无向图 */
vector<Vertex *> v = valsToVets({0, 1, 2, 3, 4, 5, 6, 7, 8, 9});
vector<vector<Vertex *>> edges = {{v[0], v[1]}, {v[0], v[3]}, {v[1], v[2]}, {v[1], v[4]},
{v[2], v[5]}, {v[3], v[4]}, {v[3], v[6]}, {v[4], v[5]},
{v[4], v[7]}, {v[5], v[8]}, {v[6], v[7]}, {v[7], v[8]}};
GraphAdjList graph(edges);
cout << "\n初始化后,图为\\n";
graph.print();
/* 广度优先遍历 */
vector<Vertex *> res = graphBFS(graph, v[0]);
cout << "\n广度优先遍历(BFS)顶点序列为" << endl;
printVector(vetsToVals(res));
// 释放内存
for (Vertex *vet : v) {
delete vet;
}
return 0;
}

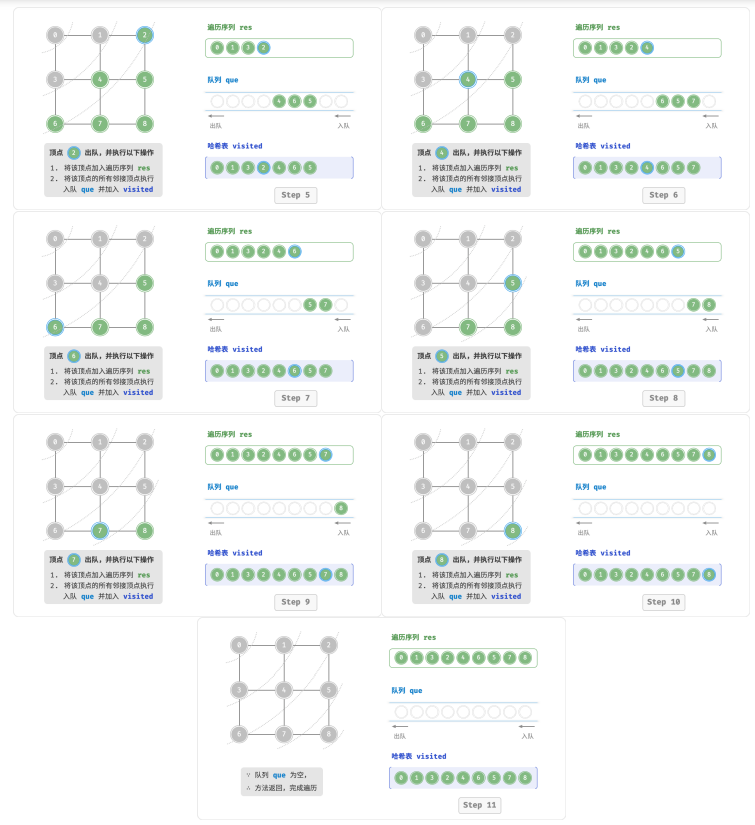
广度优先遍历的序列并不唯一。广度优先遍历只要求按“由近及远”的顺序遍历,而多个相同距离的顶点的遍历顺序允许被任意打乱。
复杂度分析
时间复杂度:所有顶点都会入队并出队一次,使用 𝑂(|𝑉 |) 时间;在遍历邻接顶点的过程中,由于是无向图,因此所有边都会被访问 2 次,使用 𝑂(2|𝐸|) 时间;总体使用 𝑂(|𝑉 | + |𝐸|) 时间。
空间复杂度:列表 res ,哈希表 visited ,队列 que 中的顶点数量最多为 |𝑉 | ,使用 𝑂(|𝑉 |) 空间。
深度优先遍历
深度优先遍历是一种优先走到底、无路可走再回头的遍历方式。从左上角顶点出发,访问当前顶点的某个邻接顶点,直到走到尽头时返回,再继续走到尽头并返回,以此类推,直至所有顶点遍完成。
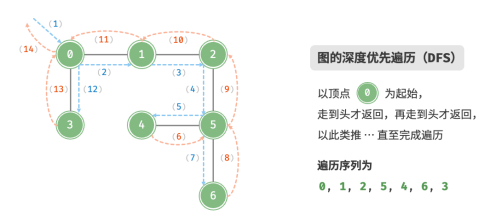
算法实现
这种“走到尽头再返回”的算法范式通常基于递归来实现。与广度优先遍历类似,在深度优先遍历中,也需要借助一个哈希表 visited 来记录已被访问的顶点,以避免重复访问顶点。
/**
* File: graph_dfs.cpp
* Created Time: 2023-03-02
* Author: Krahets (krahets@163.com)
*/
#include "../utils/common.hpp"
#include "./graph_adjacency_list.cpp"
/* 深度优先遍历辅助函数 */
void dfs(GraphAdjList &graph, unordered_set<Vertex *> &visited, vector<Vertex *> &res, Vertex *vet) {
res.push_back(vet); // 记录访问顶点
visited.emplace(vet); // 标记该顶点已被访问
// 遍历该顶点的所有邻接顶点
for (Vertex *adjVet : graph.adjList[vet]) {
if (visited.count(adjVet))
continue; // 跳过已被访问的顶点
// 递归访问邻接顶点
dfs(graph, visited, res, adjVet);
}
}
/* 深度优先遍历 */
// 使用邻接表来表示图,以便获取指定顶点的所有邻接顶点
vector<Vertex *> graphDFS(GraphAdjList &graph, Vertex *startVet) {
// 顶点遍历序列
vector<Vertex *> res;
// 哈希表,用于记录已被访问过的顶点
unordered_set<Vertex *> visited;
dfs(graph, visited, res, startVet);
return res;
}
/* Driver Code */
int main() {
/* 初始化无向图 */
vector<Vertex *> v = valsToVets(vector<int>{0, 1, 2, 3, 4, 5, 6});
vector<vector<Vertex *>> edges = {{v[0], v[1]}, {v[0], v[3]}, {v[1], v[2]},
{v[2], v[5]}, {v[4], v[5]}, {v[5], v[6]}};
GraphAdjList graph(edges);
cout << "\n初始化后,图为" << endl;
graph.print();
/* 深度优先遍历 */
vector<Vertex *> res = graphDFS(graph, v[0]);
cout << "\n深度优先遍历(DFS)顶点序列为" << endl;
printVector(vetsToVals(res));
// 释放内存
for (Vertex *vet : v) {
delete vet;
}
return 0;
}
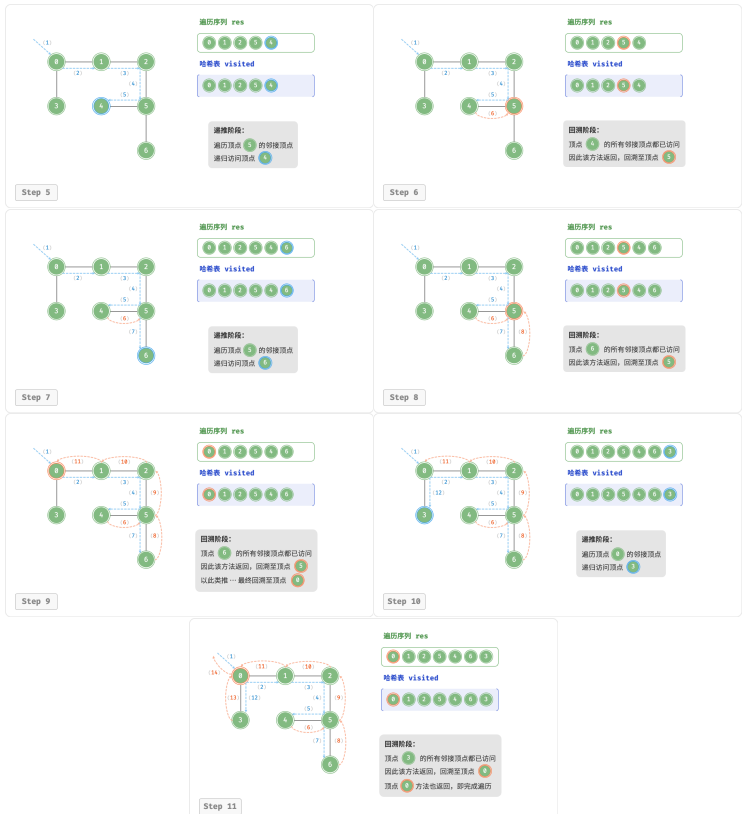
直虚线代表向下递推,表示开启了一个新的递归方法来访问新顶点;
曲虚线代表向上回溯,表示此递归方法已经返回,回溯到了开启此方法的位置。
深度优先遍历序列的顺序也不是唯一的。给定某顶点,先往哪个方向探索都可以,即邻接顶点的顺序可以任意打乱,都是深度优先遍历。
以树的遍历为例,“根 → 左 → 右”“左 → 根 → 右”“左 → 右 → 根”分别对应前序、中序、后序遍历,它们展示了三种遍历优先级,然而这三者都属于深度优先遍历。
复杂度分析
时间复杂度:所有顶点都会被访问 1 次,使用 𝑂(|𝑉 |) 时间;所有边都会被访问 2 次,使用 𝑂(2|𝐸|) 时间;总体使用 𝑂(|𝑉 | + |𝐸|) 时间。
空间复杂度:列表 res ,哈希表 visited 顶点数量最多为 |𝑉 | ,递归深度最大为 |𝑉 | ,因此使用 𝑂(|𝑉 |) 空间。
学习地址
学习地址:https://github.com/krahets/hello-algo
重新复习数据结构,所有的内容都来自这里。