Transformer的前世今生 day07(Masked Self-Attention、Multi-Head Self-Attention)
2024-03-26 23:56:01 开发 33
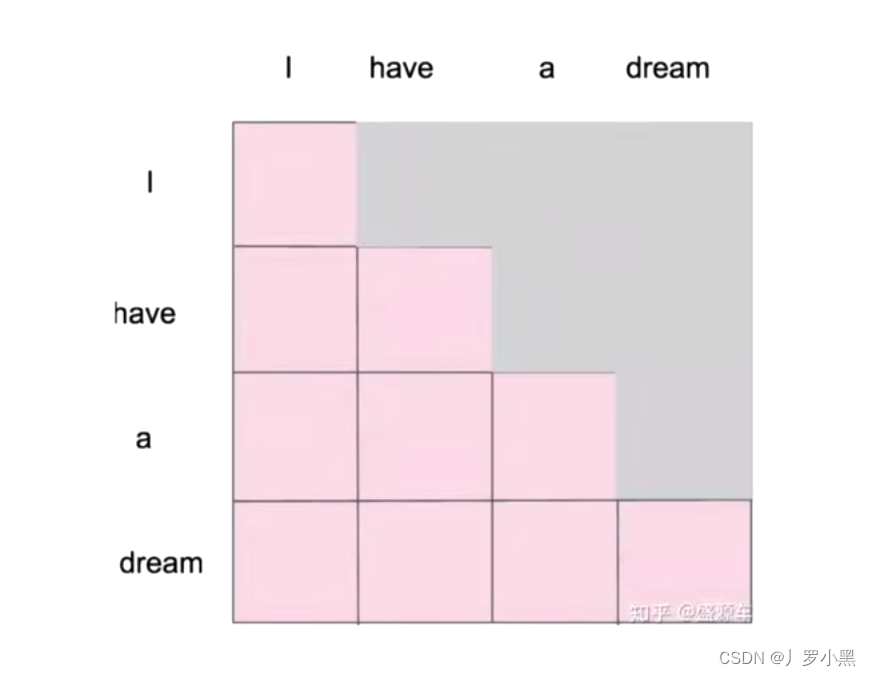
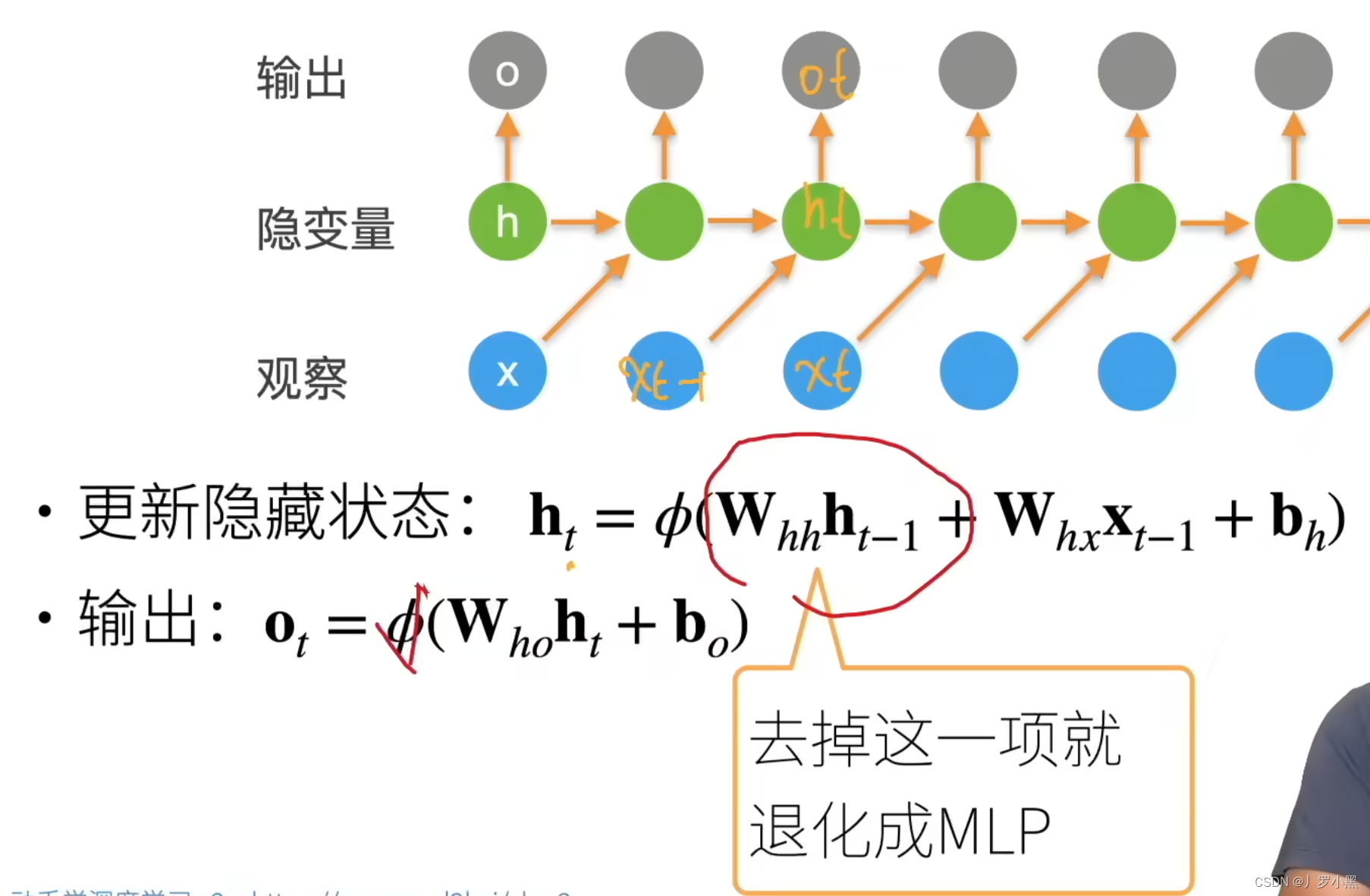
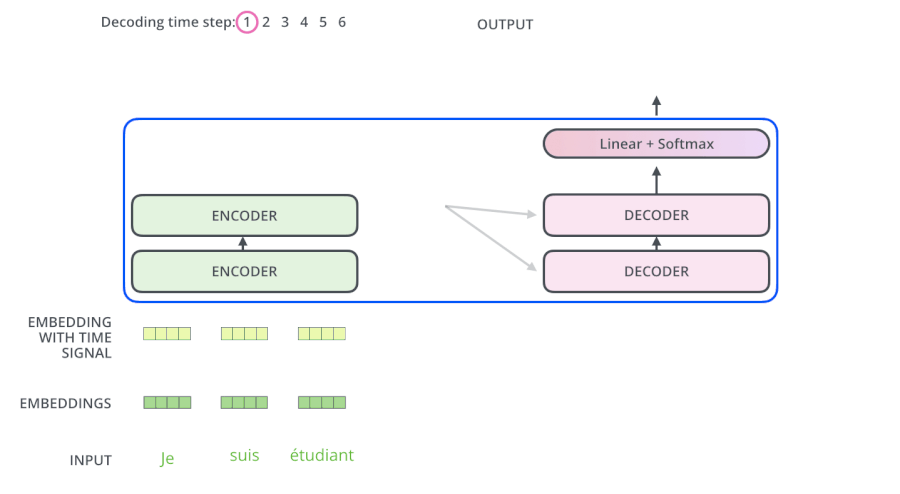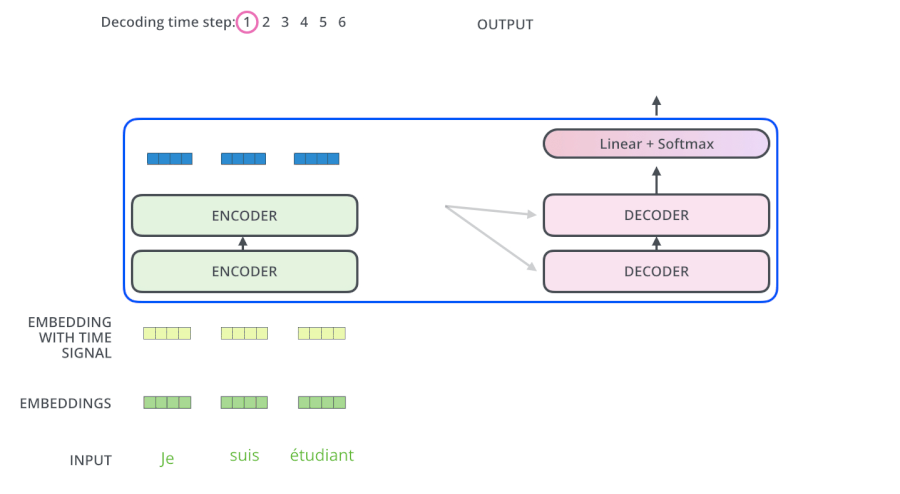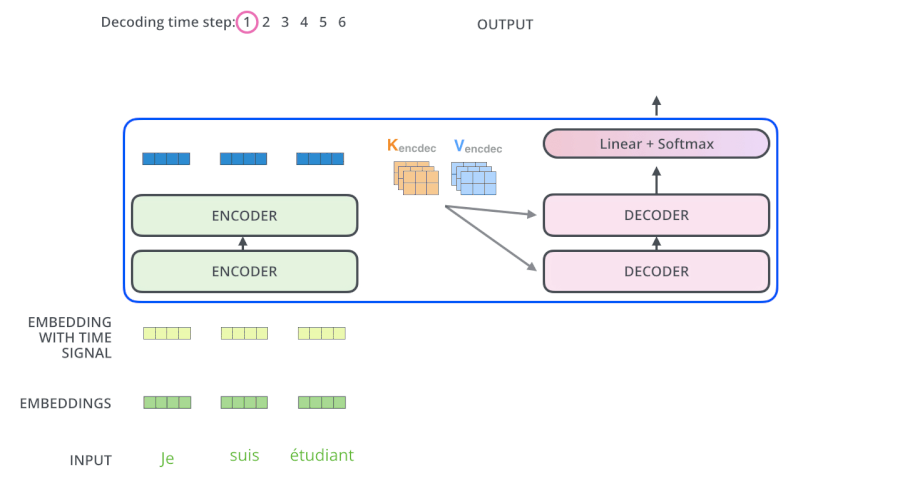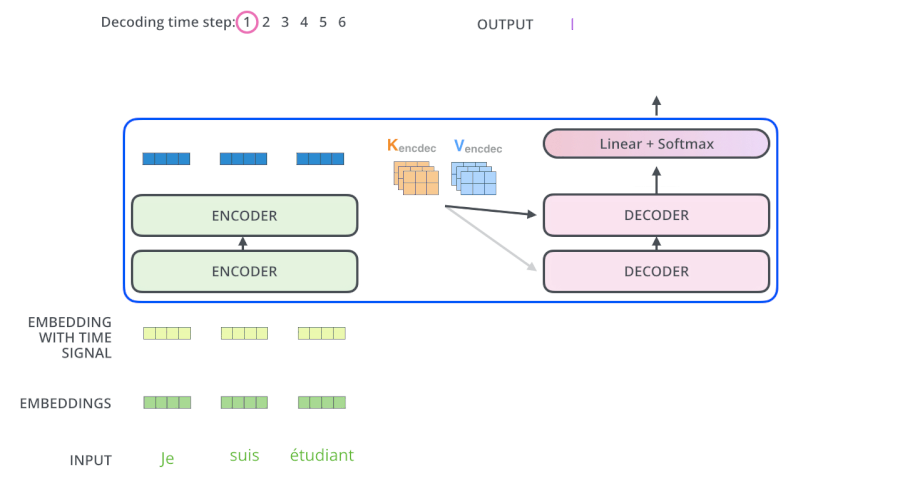
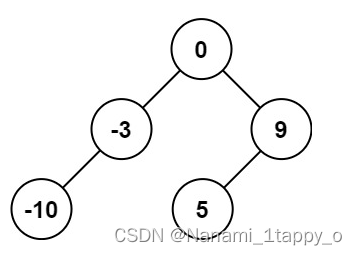
由于NLP中的生成模型,是一个一个的生成单词, 所以为了让自注意力也实现这个过程,就设计了掩码自注意力
掩码:在自注意力机制中,每个输入位置都会与其他位置进行注意力计算,并计算出一个加权和。而掩码的作用是将不相关或无效的位置的注意力权重设置为0,从而将模型的关注点限定在有效的位置上。如:将未来位置的注意力权重被设置为0,以防止模型在生成当前位置时依赖未来的信息,从而达到生成模型,一个一个生成单词的效果
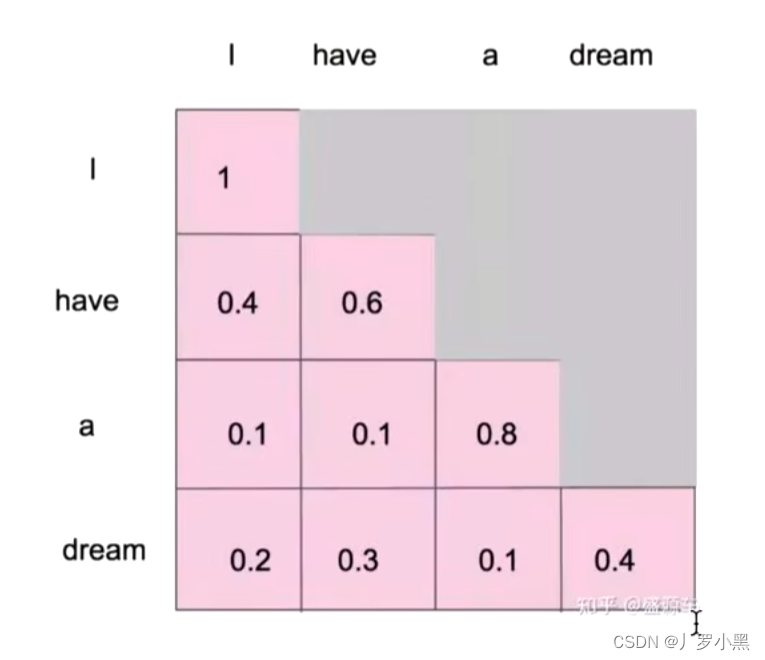
如果只是自注意力机制,那么模型会知道这句话完整的样子,但是掩码自注意力,模型是分批次得到这句话,最后一次才得到完整的一句话,概率分布如下:·
Self-Attention是Attention的一个具体做法,即规定Q、K、V同源。注意力机制的目的是为了得到一个比初始的词向量拥有更多信息的新词向量Z
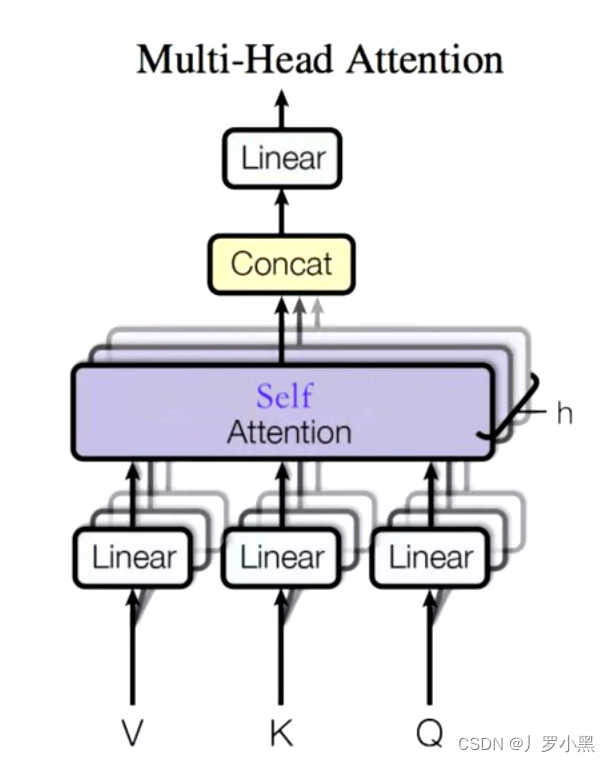
Multi-Head Self-Attention的目的是为了得到一个比Z拥有更多信息的新Z’
多头指多层、多个。多头的个数用h表示,一般h=8,通常我们使用的是8头自注意力,在此,我们将输入X分割为8块,经过一系列变换后,得到 Z 0 Z_0 Z 0 Z 7 Z_7 Z 7 Z 0 Z_0 Z 0 Z 7 Z_7 Z 7
机器学习的本质:y = σ \sigma σ
非线性变换的本质:改变空间上的位置坐标。由于任何一个点都可以在维度空间上找到,所以我们可以通过某个手段,让一个位置不合理的点,变得合理。
词向量的本质:将独热编码(不合理),通过Word2Vec、ELMO、Attention、Multi-Head Attention来得到合理的点,如(11,222,33)
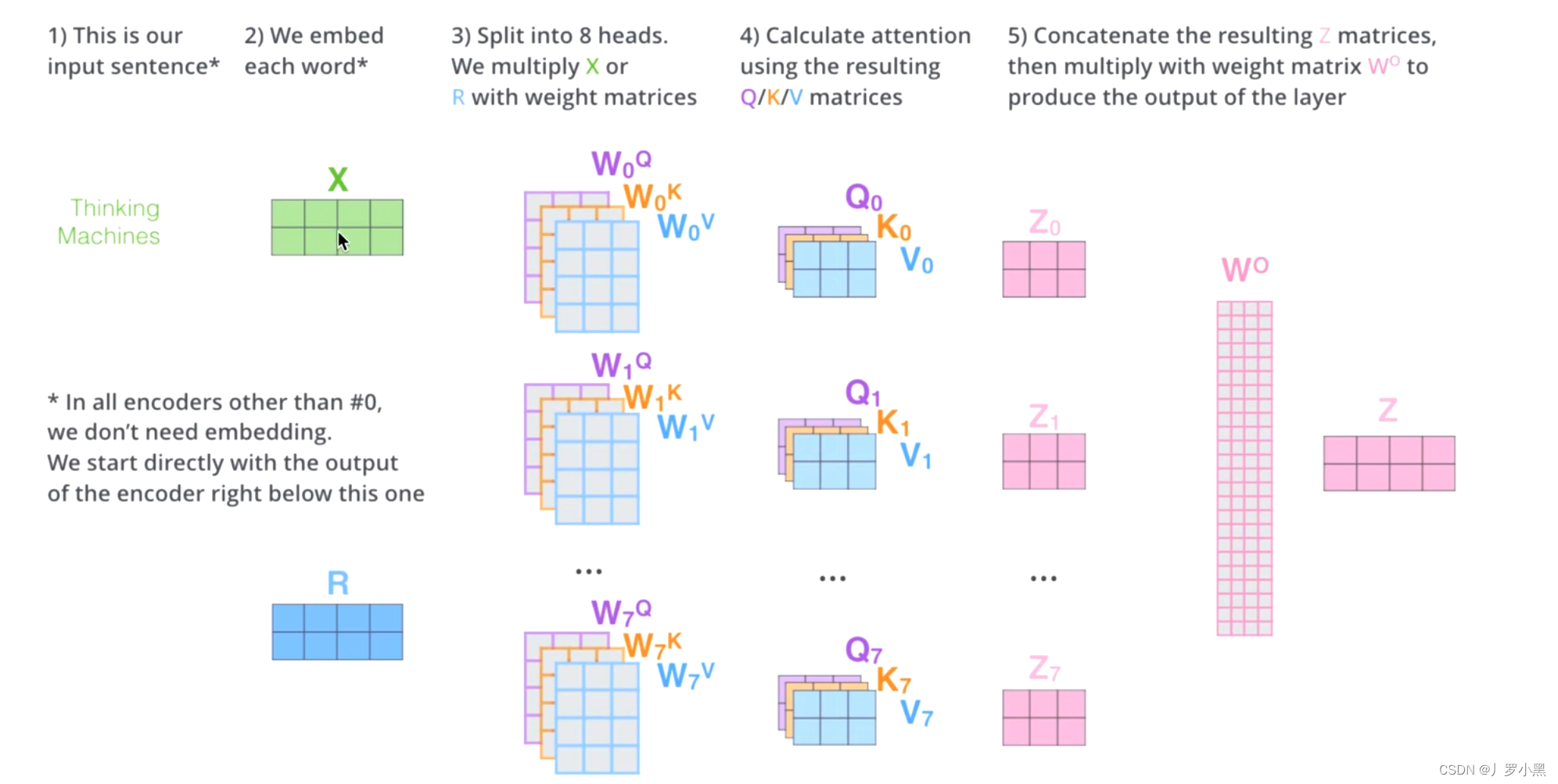
Multi-Head Attention:将输入X分成8块,这样原先在一个位置上的不合理的X,去了空间上的8个位置,通过对8个点进行寻找合适的位置,从而可以找到更合适的位置。
但是对于词向量来说,h的个数不是越大越好,如果h为100,那么可能其中有80多个是没用的,经过实验,8是比较好的个数
以下为流程图:
给一句话,通过ELMO、Word2Vec、Attention等来获得输入词向量x,之后乘以8套 W Q W^Q W Q W K W^K W K W V W^V W V Q Q Q K K K V V V Q Q Q K K K V V V Z Z Z Z Z Z
通过8个位置来寻找合适的位置点,从而可以找到能表示更多信息,更合理的词向量
PS:交叉注意力:K和V近似相等,但是Q不和K、V同源
12 Masked Self-Attention(掩码自注意力机制) 13 Multi-Head Self-Attention(从空间角度解释为什么做多头)
原文地址:https://blog.csdn.net/u011453680/article/details/137017325
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。
本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:https://www.suanlizi.com/kf/1772653742513065984.html
如若内容造成侵权/违法违规/事实不符,请联系《酸梨子》网邮箱:1419361763@qq.com进行投诉反馈,一经查实,立即删除!