Kafka是由Apache软件基金会管理的一个开源数据流处理平台。Kafka最初由LinkedIn公司开发,用来作为一个分布式的基于发布/订阅模式的消息队列,主要应用于大数据实时处理领域,之后被捐赠并成为Apache项目的一部分。随着Kafka的不断发展,Kafka现在被更广泛地看作是一个分布式事件流平台,被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用。Kafka官网对其描述如下:
Apache Kafka is an open-source distributed event streaming platform used by
thousands of companies for high-performance data pipelines, streaming analytics,
data integration, and mission-critical applications.
Kafka的主要特点
Kafka作为一个开源的分布式流处理平台,具备一系列显著特点,这些特点使得它在大数据和实时处理领域具有广泛的应用。以下是Kafka的主要特点:
(1) 高吞吐量与低延迟。Kafka可以处理大量的数据,提供高吞吐量的数据写入和读取能力。具体来说,它每秒可以生产或消费处理几十万条消息,且消息的生产不需要等待消费者的确认(也就是说,消息的生产和消费是解耦的)。同时,Kafka能够保持较低的延迟,能够保证最低可以达到毫秒级的消息延迟。
(2) 持久化能力。Kafka通过将消息持久化到磁盘,保证了数据的可靠性和持久性。即使发生系统故障,Kafka也能保证数据的不丢失,并且可以恢复并继续处理数据。
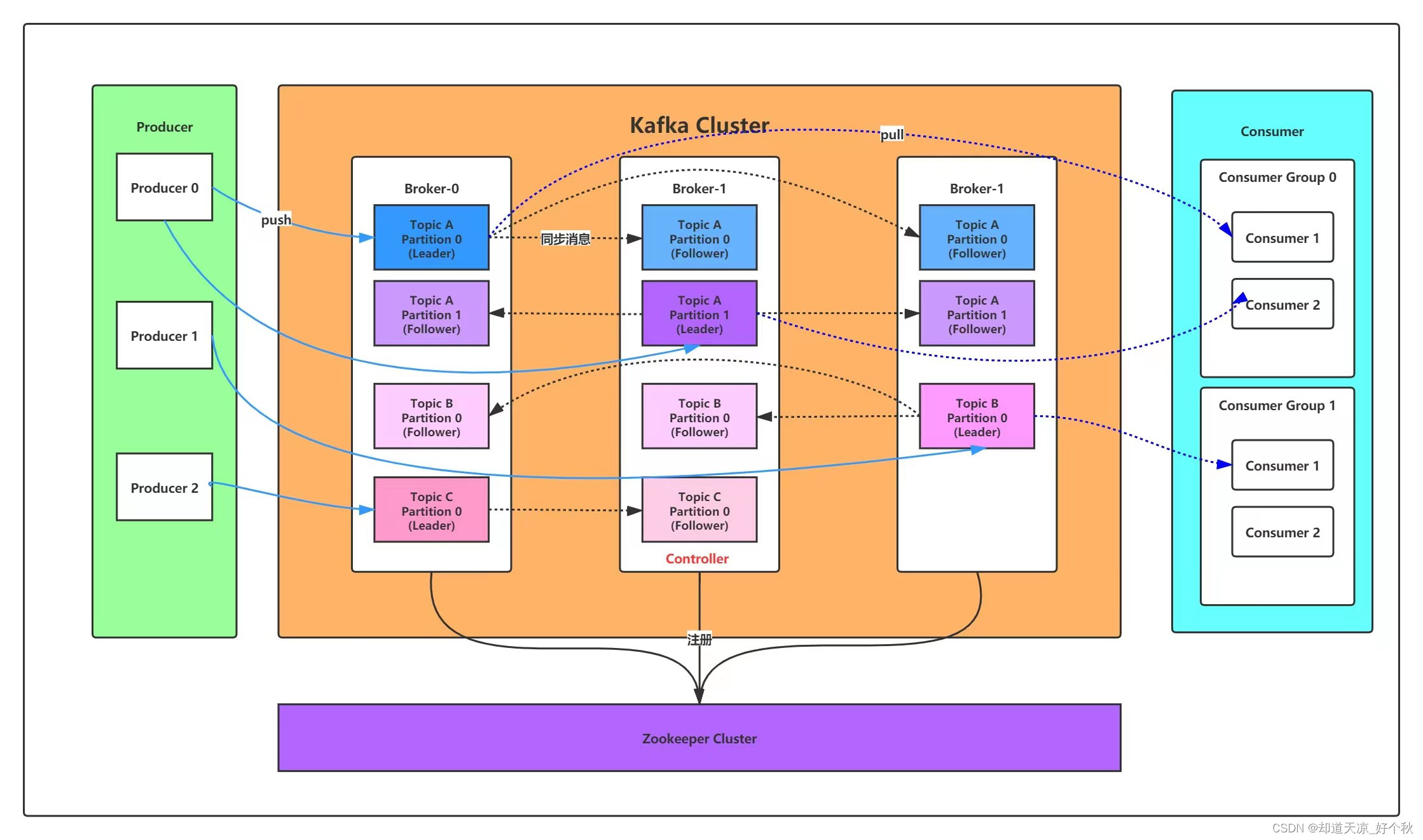
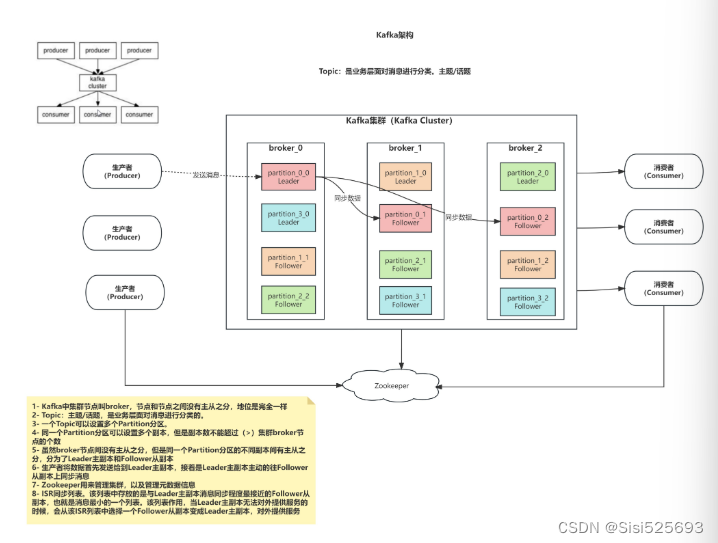
(3) 水平扩展能力。Kafka采用分布式架构,可以将数据分布在多个Broker上,提高系统的存储和计算能力。这使得Kafka能够处理大量的数据,并且具有良好的水平扩展能力。这种架构允许Kafka通过增加Broker节点来扩展系统的处理能力和吞吐量,而无需对现有的系统进行停机或重大改动。此外,Kafka中的每个主题(topic)都可以分为多个分区(partition),分区是Kafka中的基本单位。通过将数据分散到不同的分区,Kafka可以实现数据的水平扩展。这种分区机制不仅可以将数据分布在多个节点上,提高系统的吞吐量和容量,还可以通过分区的创建和删除,根据业务需求灵活调整分区数量。
(4) 分布式系统。Kafka将消息数据存储在多个Broker节点上,每个Broker都维护一部分数据。这种数据分片的方式使得Kafka能够处理大规模的数据集,并提供了高可靠性和容错性。即使部分Broker出现故障,其他Broker仍然可以继续提供服务,保证数据的可用性和系统的稳定性。Kafka通过引入分区和复制机制来实现数据的水平扩展和高可用性。每个主题可以划分为多个分区,每个分区可以存储在不同的Broker上。同时,Kafka还支持分区的复制,即每个分区的数据可以在多个Broker上进行备份,以防止单点故障和数据丢失。这种分区和复制机制使得Kafka能够在多个节点之间实现负载均衡和容错处理。此外,Kafka允许生产者(Producer)和消费者(Consumer)并发地访问不同的Broker,从而实现分布式的数据处理。生产者可以将消息发送到不同的分区,而消费者可以并行地从多个分区读取消息。这种分布式处理方式大大提高了系统的吞吐量和处理速度,使得Kafka能够应对高并发的数据写入和读取需求。
Kafka的使用场景
Kafka是一个分布式数据流处理平台,它支持实时数据流处理、日志收集与分析、消息队列、以数据流为中心的应用等场景。接下来详细介绍Kafka的常见应用场景:
(1) 实时数据流处理:Kafka可以作为一个高效的数据流平台,用于收集、处理和分发实时数据流。它能够帮助企业实时监控业务数据、分析数据。如,在金融行业,Kafka可以实时处理交易数据,为风险控制和决策提供实时反馈。通过流处理,Kafka可以对实时数据进行实时处理,虽然数据处理的响应时间并没有“请求-响应”模式的那么短,但是相对于一般的批处理模式还是要快很多。对于一般的客户服务、物联网系统的状态预测、异常检测等来说是非常高效的、实用的方法。流处理介于"请求与响应"和"批处理"两种编程范式之间,大部分业务流程都是持续进行的,只要业务数据保持更新,那么业务流程就可以进行下去,而无需等待特定的响应,也不要求在亚毫秒内得到响应。业务事件时刻在发生,Kafka能够及时对这些事件作出响应,基于Kafka构建的服务直接为业务运营提供支撑,提升用户体验。
(2) 日志收集与分析:Kafka在日志收集与分析方面表现出色。许多应用都会产生大量的日志数据,使用Kafka可以将这些日志数据集中存储,并提供给日志分析工具进行实时或离线的分析。
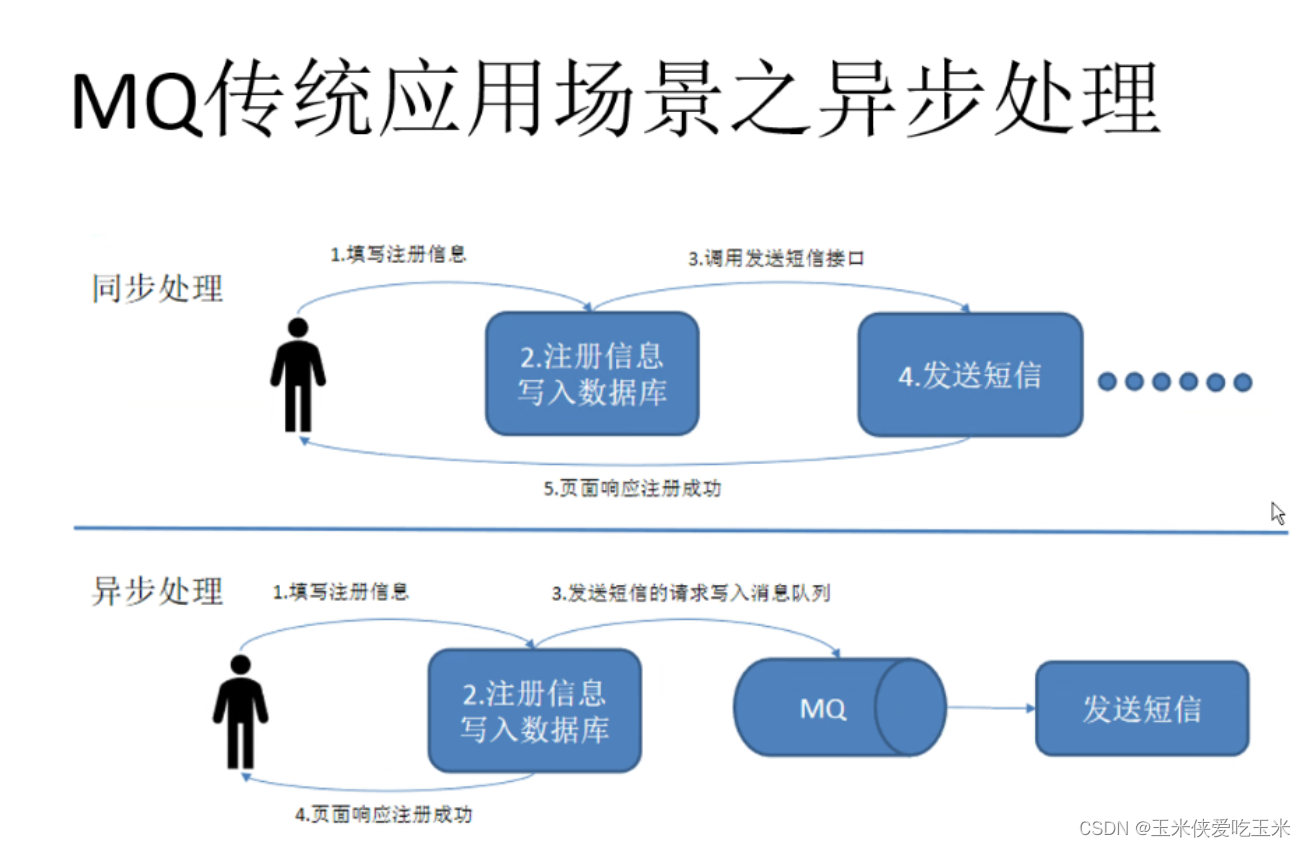
(3) 消息队列:Kafka最常见的应用场景之一就是作为消息队列使用。作为消息队列,Kafka主要应用于软件解耦、缓冲和削峰、冗余、异步通信等业务场景。生产者将消息发送到Kafka的主题中,消费者从主题中订阅消息并进行处理。这种解耦的方式使得系统的各个部分可以独立地扩展和升级。当系统中出现"生产"和"消费"的速度或稳定性等因素不一致的时候,消息队列将作为中间层,弥合双方的差异。上游数据有突发流量,下游可能扛不住,或者下游没有足够多的机器来保证冗余,消息队列在中间可以起到一个缓冲的作用,把消息暂存在消息队列中,下游服务就可以按照自己的节奏进行慢慢处理。
与传统的消息队列对比,Kafka仍然存在很多重要的不同点,这些差异使它完全不同于传统的消息队列。首先,作为一个现代的分布式系统,Kafka以集群的方式运行,可以自由伸缩。Kafka集群并不是一组独立运行的broker,而是一个可以灵活伸缩的中心平台。其次,Kafka可以按照使用者的要求存储数据,保存多久都可以。作为数据连接层,Kafka提供了数据传递保证可复制、持久化,保留多长时间完全可以由使用者来决定。最后,流式处理能力将数据处理的层次提升到了新高度。传统的消息队列只会传递消息,而Kafka的流处理能力让使用者只用很少的代码就能够动态地处理派生流和数据集。Kafka的这些独到之处让其在超越传统的消息队列。
(4) 以数据流为中心的。Kafka颠覆了传统的思维。Kafka并非只是把数据从一个系统拆解出来再塞进另一个系统,它其实是一个面向实时数据流的平台。也就是说,它不仅可以将现有的应用程序和数据系统连接起来,它还能用于加强这些触发相同数据流的应用。这种以数据流为中心的架构是非常重要的。在某种程度上说,这些数据流是现代数字科技公司的核心。以事件驱动架构为例,Kafka可以作为事件驱动架构的核心组件,帮助企业构建可伸缩、可靠、高性能的事件驱动应用程序。通过监听Kafka中的事件,应用程序可以实时响应并处理各种业务场景。
此外,Kafka还可以应用于网站用户行为追踪、大数据流式计算处理等多个场景。Kafka的分布式特性和高吞吐量使其能够处理大规模的数据流和日志数据,为各种业务场景提供强大的支持。
需要说明的是,虽然Kafka具有广泛的应用场景,但在具体使用时需要根据业务需求和技术栈进行选择和配置。同时,随着技术的不断发展,Kafka也在不断更新和优化其功能,以适应更多新的应用场景和需求。
Kafka的不足
Kafka虽然是一个强大的分布式流处理平台,但在某些方面也存在一些不足之处。
如作为消息队列,Kafka会带来以下问题:
(1) 系统可用性降低。系统引入的外部依赖越多,系统的可用性越难维护。引入Kafka作为消息队列后,系统将强依赖Kafka,当Kafka不可用时,系统也会受到影响。这时,还需保证Kafka的高可用性。
(2) 系统复杂度提高。引入Kafka作为消息队列后,还需处理消息带来的一系列问题。如消息丢失问题、消息重复消费问题、消息顺序性问题等。
(3) 系统一致性问题。引入Kafka作为消息队列后,会带来分布式系统的一致性问题。使用消息队列后,无法保证强一致性,需要保证最终一致性。主要通过以下两个方面来实现:消息发送方执行本地事务与发送消息的原子性问题。也就是说如何保证本地事务执行成功,消息一定发送成功;消息接收方必须实现幂等性。由于消息可能会重复发送,这就要求消息接收方必须能够正确处理这种情况,保证接收到的消息只被处理一次。
作为流处理组件,Kafka会带来以下问题:
(1) 数据批量发送,并未实现真正的实时。虽然Kafka可以轻松处理巨大的消息流,但是在处理大量数据的同时,不能保证亚秒级的消息延迟。
(2) 支持统一分区内消息的有序性,无法保证全局消息有序。如果需要保证全局消息的有序性,则需要引入额外的排序服务,比如Apache Samza、Apache Flink等。
参考
https://kafka.apache.org/documentation/ KAFKA DOCUMENTATION
https://kafka.apachecn.org/ kafka 3.5.x 中文文档
https://blog.csdn.net/lizhitao/article/details/39499283 apache kafka技术分享系列
https://www.orchome.com/kafka/index kafka中文教程
https://yiyan.baidu.com/ 百度文心一言
https://www.confluent.io/de-de/blog/event-streaming-platform-1/ Putting Apache Kafka To Use: A Practical Guide to Building an Event Streaming Platform (Part 1)