基于深度学习的OCR技术在处理图像像素差的问题时确实面临一定的挑战。图像像素差可能导致OCR系统无法准确识别文本,从而影响其精度和可靠性。尽管已经有一些方法如SRN-Deblur、超分SR和GAN系列被尝试用于解决这个问题,但效果并不理想。然而,这并不意味着这个问题无解。
以下是一些可能有助于解决或缓解图像像素差问题的方法:
1. 数据预处理:在进行OCR之前,对图像进行预处理是提高识别精度的关键步骤。这包括图像去噪、对比度增强、二值化等操作。通过预处理,可以改善图像的视觉质量,使其更适合OCR处理。此外,还可以使用图像增强的方法,如直方图均衡化、Gamma校正等,来提高图像的对比度和亮度。
2. 图像超分辨率技术:超分辨率技术是一种通过软件方法提高图像分辨率的技术。它可以通过对低分辨率图像进行插值和重建,生成高分辨率图像。这种方法可以在一定程度上改善图像像素差的问题。目前,基于深度学习的超分辨率技术已经取得了很大的进展,如SRCNN、EDSR等模型,可以尝试将这些技术应用于OCR前的图像预处理阶段。
3. 文本区域定位和分割:在OCR过程中,准确地定位和分割文本区域对于提高识别精度非常重要。可以使用深度学习的方法,如卷积神经网络(CNN)或循环神经网络(RNN),对图像进行文本区域定位和分割。这些方法可以帮助系统更好地识别图像中的文本,从而提高OCR的精度。
4. 深度学习模型优化:针对图像像素差的问题,可以尝试对深度学习模型进行优化。例如,可以使用更深的网络结构、更复杂的特征提取方法或更先进的训练策略来提高模型的识别能力。此外,还可以使用迁移学习的方法,利用在其他数据集上预训练的模型来初始化OCR模型的参数,从而加快训练速度和提高识别精度。
5. 后处理技术:在OCR结果出来后,还可以使用后处理技术来提高识别精度。例如,可以使用语言模型对识别结果进行纠正和修正,或使用字典等技术来提高识别的准确性。此外,还可以使用投票、融合等方法将多个OCR模型的结果进行集成,从而得到更准确的识别结果。
综上所述,虽然图像像素差对OCR精度的影响是一个具有挑战性的问题,但通过采用合适的方法和技术,仍然可以在一定程度上解决或缓解这个问题。在实际应用中,可以根据具体情况选择适合的方法来提高OCR的精度和可靠性。
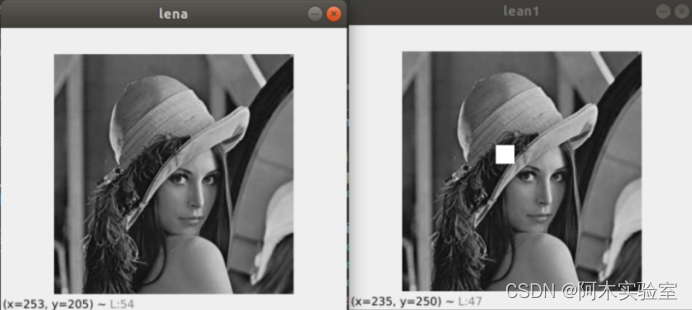

![[OpenCV<span style='color:red;'>学习</span>笔记]获取鼠标处<span style='color:red;'>图像</span><span style='color:red;'>的</span>坐标和<span style='color:red;'>像</span><span style='color:red;'>素</span>值](https://img-blog.csdnimg.cn/img_convert/538512804500b8edfd1edc71f301e12e.webp?x-oss-process=image/format,png)
![[Qt<span style='color:red;'>学习</span>笔记]Qt鼠标事件mouseMoveEvent实时获取<span style='color:red;'>图像</span><span style='color:red;'>的</span>坐标和<span style='color:red;'>像</span><span style='color:red;'>素</span>值](https://img-blog.csdnimg.cn/img_convert/46d409e97a8ea4ad68ad7cb738ba0f0a.gif)




















![[HGAME 2023 week2]Designer](https://img-blog.csdnimg.cn/direct/a4506526d4f3489fb39b2a3947571c10.png)




![[STM32] 使用 STM32CubeMX 创建 STM32 工程模板](https://img-blog.csdnimg.cn/img_convert/65c9d26b8b5300e5510a513fe7251634.png#pic_center)