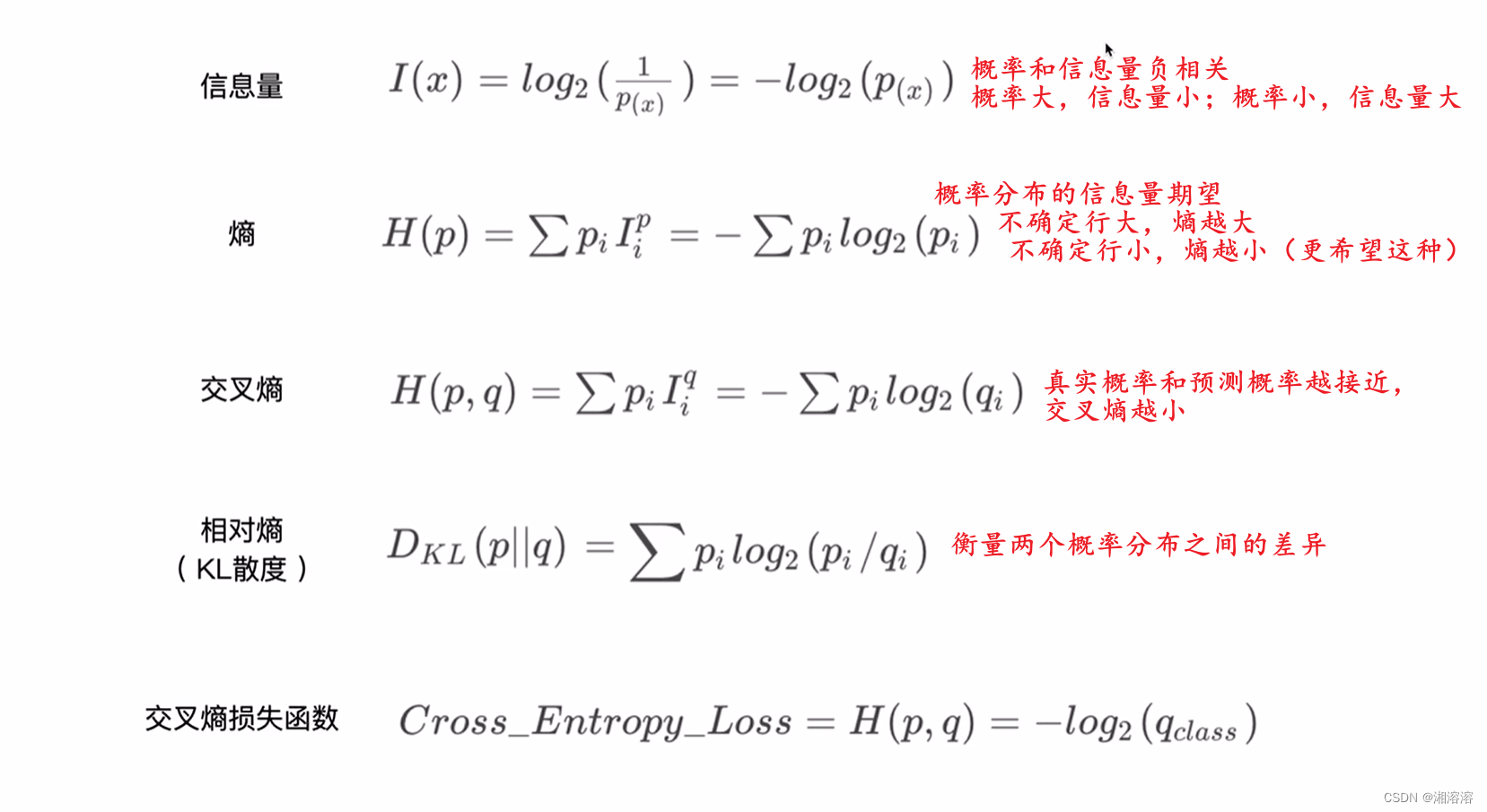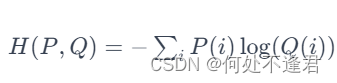在PyTorch中,计算交叉熵损失主要有以下几种方式,它们针对不同的场景和需求有不同的实现方式和适用范围:
1. nn.CrossEntropyLoss 类
这是最常用且方便的方法,特别适用于多分类任务。nn.CrossEntropyLoss 实际上是同时完成了 softmax 函数和交叉熵损失的计算。它假设最后一层的输出没有经过归一化处理(不是概率形式),而是直接给出了各个类别的得分。该函数会自动计算每一样本对各类别的得分,应用softmax函数,然后计算交叉熵损失。
import torch
import torch.nn as nn
# 假设 outputs 是模型的最后一层输出,shape 为 (batch_size, num_classes),targets 是 ground truth labels
outputs = torch.randn(100, 10) # 对于10分类问题的100个样本的不归一化的预测值
targets = torch.randint(0, 10, (100,)) # 对应的真实类别
loss_fn = nn.CrossEntropyLoss()
loss = loss_fn(outputs, targets)
print(loss.item())
2. F.cross_entropy 函数
torch.nn.functional.cross_entropy 函数也是为了多分类问题设计的,但它接受的是 logits 或者已经经过 softmax 的概率。如果你的输出已经是经过 softmax 的概率,可以直接使用;否则,它会默认内部先执行 log_softmax。
import torch.nn.functional as F
# 假设 outputs 是未经 softmax 的 logits
outputs = torch.randn(100, 10)
# 使用 F.cross_entropy 直接计算损失,无需单独进行 softmax
loss = F.cross_entropy(outputs, targets)
print(loss.item())
3. nn.BCEWithLogitsLoss 类(二分类问题)
对于二分类问题,尤其是sigmoid激活函数之后的结果,可以使用带Sigmoid的二元交叉熵损失函数,它同时完成 sigmoid 和 二元交叉熵损失的计算。
# 二分类问题,输出维度为 (batch_size, 1)
outputs = torch.randn(100, 1)
# targets 是介于 [0, 1] 或 {-1, 1} 的值,表示正负样本
targets = torch.rand(100, 1) > 0.5 # 或者其他的二进制标签
bce_loss = nn.BCEWithLogitsLoss()
loss = bce_loss(outputs, targets.float())
print(loss.item())
4. 手动计算交叉熵损失
当然,也可以手动组合 log_softmax 和 nll_loss 函数来计算交叉熵损失,这在特殊情况下可能会有用,比如需要对损失函数进行修改或者自定义的时候:
# 多分类问题,手动组合 log_softmax 和 nll_loss
output_logits = torch.randn(100, 10)
softmax_outputs = F.log_softmax(output_logits, dim=1) # 计算 log_softmax
loss_manual = -torch.mean(torch.gather(softmax_outputs, 1, targets.unsqueeze(1)).squeeze()) # 使用 gather 和 mean 计算 NLL
assert torch.allclose(loss_manual, F.nll_loss(softmax_outputs, targets, reduction='mean')) # 应该与 nll_loss 结果一致
在上述代码中,gather 函数用于从预测概率矩阵中按照目标标签索引出相应的对数概率,然后求平均得到最终的交叉熵损失。在多分类任务中,直接使用 F.nll_loss(log_softmax_outputs, targets) 是更加简洁的做法,等价于手动计算。而在二分类问题中,对应的手动计算方式则会涉及 sigmoid 和 binary_cross_entropy_with_logits 函数。
5. 补充说明
在交叉熵损失计算函数中:
L = − ∑ i = 1 n y i l o g ( S ( f θ ( x i ) ) ) L = -\sum_{i=1}^{n}{y_i}log(S(f_\theta(x_i))) L=−i=1∑nyilog(S(fθ(xi)))
真实值 y i y_i yi可以是热编码后的结果,也可以不进行热编码。
虽然在Pytorch架构中,神经网络内流动的数据类型必须是float类型,但是Pytorch也提供了自动处理整数(int类型)标签的交叉熵损失函数(这里的“整数标签”指的是每个样本所属的真实类别,通常是一个从0开始的整数索引,对应着类别数量中的一个),这些函数会自动将整数标签转换为内部使用的one-hot编码格式,并计算交叉熵损失。
以nn.CrossEntropyLoss为例,当输入给定的output是未经归一化的类别得分(logits),而target是整数标签时,这个损失函数会自动将整数标签转换为one-hot格式,然后再进行交叉熵损失的计算。这意味着用户不需要预先将目标标签转换为one-hot编码,损失函数内部会处理这样的转换过程。
import torch
import torch.nn as nn
# 假设我们有一个批次的输出和对应的类别标签
outputs = torch.randn(64, 10) # 这是一个批次的输出,共64个样本,10个类别
labels = torch.tensor([2, 7, 0, ..., 4], dtype=torch.long) # 这是对应的整数类别标签
loss_fn = nn.CrossEntropyLoss()
loss = loss_fn(outputs, labels)
print(f'Cross-entropy loss: {loss.item()}')