目录
本节主要讲zone和page的数据结构,zone是重点难点。
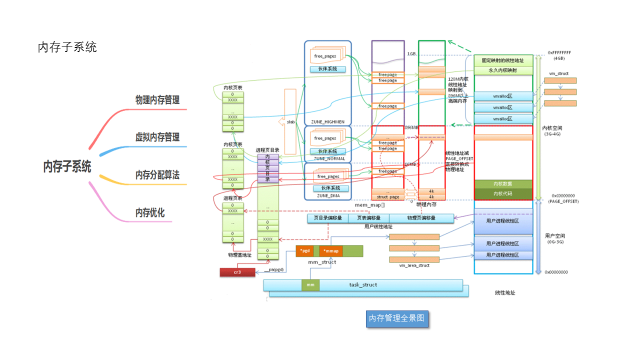
3.2 NUMA模型的内存组织
3.2.1 概述
上节已讲
3.2.2 数据结构
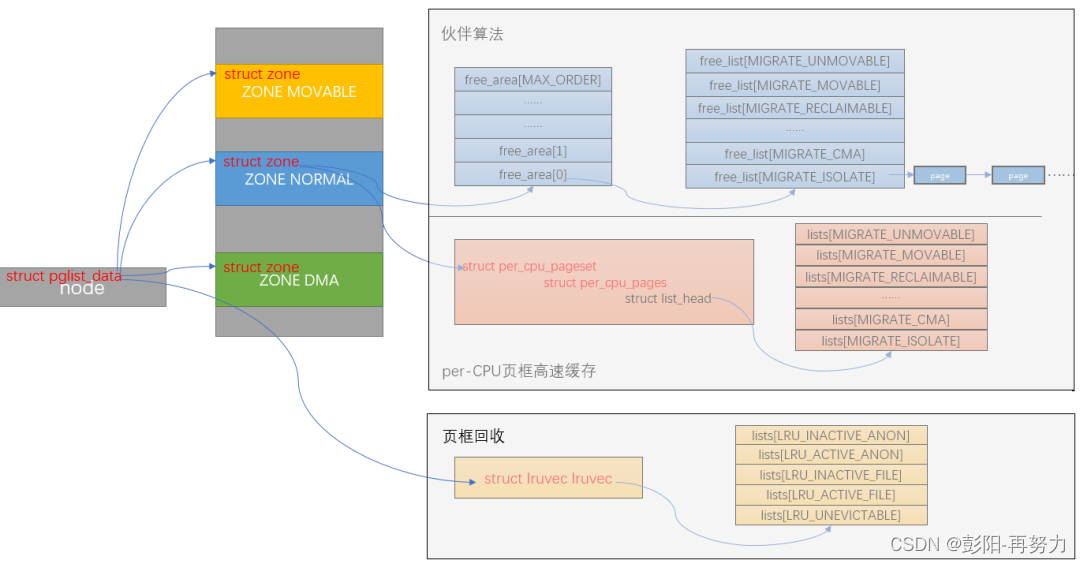
3.2.2.1 node
上节已讲
3.2.2.2 zone
每个节点有多个zone。
//会频繁访问该结构,保存在CPU缓存中
struct zone {
unsigned long watermark[NR_WMARK];
多个水位值,内存回收时使用。
long lowmem_reserve[MAX_NR_ZONES];
每个zone预留的内存大小量,留给重要分配。
int node;
所属的内存节点。
unsigned long zone_start_pfn;
该zone起始页帧号。
struct per_cpu_pageset __percpu *pageset;
每个CPU本地的缓存页,可加速页面分配和释放。
atomic_long_t managed_pages;
//被伙伴系统管理的页数。
类型atomic_long_t:原子变量,防止多处理器同时修改导致数据不一致。
unsigned long spanned_pages;
该zone物理页数,包含空洞。
unsigned long present_pages;
该zone实际可用物理页数。
managed_pages = present_pages - reserved_pages
struct free_area free_area[MAX_ORDER];
//不同大小的空闲页,被伙伴系统使用。
spinlock_t lock;
多CPU访问该结构保护
int pages_scanned;
页面回收时,该zone已扫描的页数量
bool contiguous;
该zone包含的物理页是否连续
ZONE_PADDING()
填充,确保后面成员按CPU缓存行对齐。
struct lruvec lruvec;
LRU链表,可跟踪页的使用频率。
场景:页回收时,回收使用少的页。
注意:LRU链表不用于页分配,而用于页回收。
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
统计信息,如:
NR_FREE_PAGES:该zone中空闲的页数。
NR_DIRTIED:该zone中已修改(dirty)页数。
NR_DIRTY:该区域中已写回的页数。
}
成员详细解释:
unsigned long watermark[NR_WMARK]; 包含三个水位:
1. 最低水位WMARK_MIN:
空闲页数低于该值时,内核强制执行内存回收。
2. 低水位WMARK_LOW:
空闲页数低于该值时,kswapd唤醒开始页回收。
默认值为WMARK_MIN的125%
3. 高水位WMARK_HIGH:
空闲页数高于该值时,为理想状态,不唤醒kswapd
默认值为WMARK_MIN的150%
注意:比较的单位是页数,不是字节。
struct per_cpu_pageset __percpu *pageset;
每个CPU本地的缓存页,用于加速页面分配和释放。
缓存页按迁移类型进行分组。后面专门讲。
struct free_area free_area[MAX_ORDER];
被伙伴系统使用,数组每个元素代表一种特定大小的空闲页链表
如2K,4K大小页
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
该order大小页,按迁移类型分为多个链表
unsigned long nr_free;
该order大小的空闲页的数量
};
页按迁移类型分类有:有:
MIGRATE_UNMOVABLE, 不可迁移
MIGRATE_RECLAIMABLE, 可回收
MIGRATE_MOVABLE, 可迁移
MIGRATE_PCPTYPES, 缓存页
所以伙伴系统可分配:
一个2K大小的可迁移页
一个4K大小的PCP缓存页
一个8K大小的不可迁移页
flags:
ZONE_RECLAIM_LOCKED,
该zone正在内存回收,防止多处理器并发回收内存。
ZONE_OOM_LOCKED,
防止并发(Out-of-Memory, OOM)时回收内存。
ZONE_CONGESTED,
该zone有大量的脏页面待写回
页回收方法:
直接回收:即Direct Reclaim,分配内存时,内存不足,内核直接回收。
kswapd:内核守护线程,定期唤醒并检查水位,决定是否回收。
如何遍历所有node的所有zone?
for_each_zone(zone) {
}
水位计算
zone水位单位:页数
全局变量min_free_kbytes:
表示系统保留的最小空闲物理内存。
对应参数:/proc/sys/vm/min_free_kbytes
修改该值,会触发修改所有非高端内存的zone的水位。
min_free_kbytes如何决定非高端内存的zone的水位?
1. 把字节min_free_kbytes转换成页数pages_min。
2. 所有node的所有非高端内存zone,一起按各自zone大小比例来分配页数pages_min,分配值就是各自zone的WMARK_MIN水位。
3. 计算highmem zone的WMARK_MIN:
固定公式:zone->watermark[WMARK_MIN] = zone->managed_pages / 1024;
更简单。
4. 不论是否是非高端内存zone,LOW和HIGH水位计算都一样:
WMARK_LOW=WMARK_MIN*125%
WMARK_HIGH=WMARK_MIN*150%
小结:
min_free_kbytes被所有非高端内存zone分配,得到MIN水位。
而高端内存的MIN水位和min_free_kbytes无关。
通过MIN水位得到LOW和HIGH水位。
在系统初始化时,init_per_zone_wmark_min函数会计算出min_free_kbytes。
计算方法:
1. 计算所有node 中非高端内存总和得到lowmem_kbytes。
2. min_free_kbytes = int_sqrt(lowmem_kbytes * 16); sqrt=平方根
小结:
高端内存zone的水位计算,和min_free_kbytes无关。
min_free_kbytes值的计算,也和高端内存zone无关。
总结图:
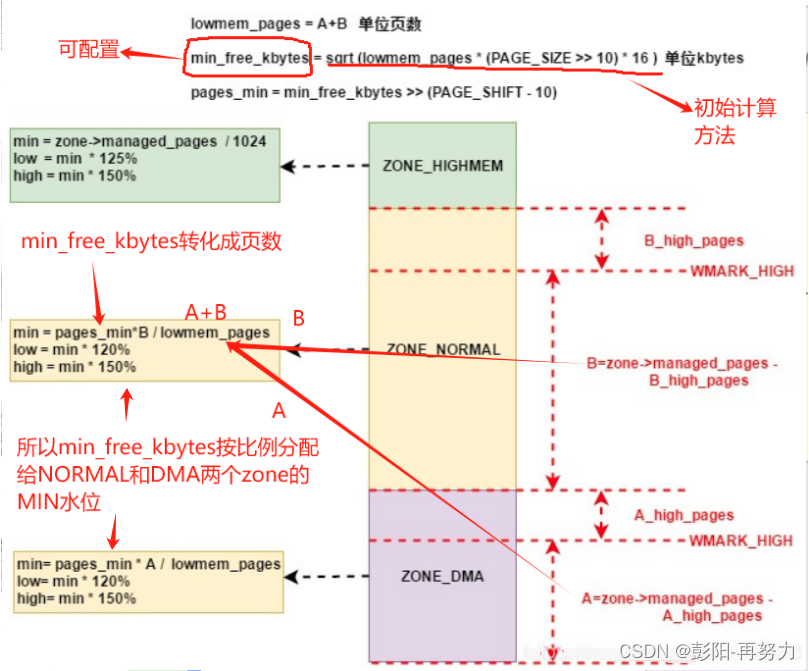
zone预留页lowmem_reserve = sysctl_lowmem_reserve_ratio[zone] * 该zone页总数
对应参数:/proc/sys/vm/lowmem_reserve_ratio
冷热页
热页:该空闲页在CPU缓存中。
冷页:该空闲页不在CPU缓存中。
冷热页机制:只缓存单页,即分配阶order为0。
优点:
提高Cache命中率。
减小锁竞争。
单页分配需求很多,若每次用伙伴系统申请,zone->lock锁住整个zone。
若多CPU分配同一zone的内存,造成锁竞争。而从自己CPU缓存中分配热页,没有锁竞争。
使用场景:
不需要给DMA设备分配热页。因为DMA设备不使用CPU及其缓存。
CPU使用的页,尽量分配热页。
冷热页的数据结构:
struct per_cpu_pageset
struct zone {
struct per_cpu_pageset __percpu; *pageset;
}
__percpu:每个CPU都有一个该变量,减少多CPU中锁争用。
struct per_cpu_pageset pageset {
struct per_cpu_pages pcp;
}
struct per_cpu_pages { 每个CPU都有一个该结构实例
int count; 该CPU为该zone缓存的空闲页数
int high; CPU缓存页超出该值的部分,将归还给系统
int batch; CPU缓存页不足时,一次可从zone中分配的页数。
struct list_head lists[MIGRATE_PCPTYPES];
指向不同迁移类型的链表。
包括:可回收页,可移动页,不可移动页。
};
只申请一个页(order=0)时,可从CPU缓存中per_cpu_pageset中分配。
冷页和热页在同一个链表中:
分配冷页,从lists链表尾开始分配。
分配热页,从lists链表头开始分配。
从zone一次性取batch个页,放到各自CPU缓存中。
页释放也先放回CPU缓存,凑够batch个页后再一起还给zone。
LRU链表
struct lruvec {
struct list_head lists[NR_LRU_LISTS]; 五个链表
struct zone_reclaim_stat reclaim_stat; 统计
};
五个链表,包括:
活跃匿名页,活跃文件页,不活跃匿名页,不活跃文件页,不可回收页。
LRU链表:管理页的活跃程度。
作用:页回收时,选择回收哪些页。
注:不用于页分配。
小结:一个页可能被挂在三个链表。
1. LRU链表:用于页回收时选择页。
2. 伙伴系统链表:按迁移类型组织不同页。
3. PCP链表:CPU缓存页,按迁移类型组织不同页。
分配页时会指定分配哪种迁移类型的页。
分配内存时,会区别是否0阶内存分配:
1. 如果是,先从PCP中分配。若PCP为空,从伙伴系统申请batch个page到PCP。
即rmqueue_bulk()
2. 如果不是分配0阶,使用伙伴系统分配。
即__rmqueue:从伙伴系统删除一个待分配page,需持有zone->lock。
3.2.2.3 page
struct page:
表示一个4K物理页。一个4G大小的内存需要4G/4K个该结构。
因为太多实例,内部使用联合体使结构体应尽量小。
struct page { //简化版
unsigned long flags 页标志
struct address_space *mapping; 文件映射信息(后续章节讲解)
pgoff_t index; mapping中偏移
atomic_t _mapcount;
有多少虚拟地址都指向该页,影响该页能否被回收
struct list_head lru;
将该页加入到LRU链表中,便于页回收。
struct kmem_cache *slab_cache;
用于slab分配器
void *virtual;
该页对应的内核虚拟地址
}
成员介绍
flag:
PG_locked:页面被锁定,防止被换出或回收。
PG_referenced:页面刚被访问过。用于页面回收时中追踪页面访问频率。
PG_uptodate:页面内容已和磁盘同步。
PG_dirty:页面内容已被修改,需写回磁盘。
PG_swapcache:页面已被换出到交换区。
PG_slab:页面属于SLAB分配器管理(后续讲解)。
PG_reserved: 页面被保留,用于特定目的使用。
PG_error:该页IO操作错误。
PG_lru:该页是否位于LRU链表上。
PG_active:该页处于活跃状态,如正在使用的页。
PG_unevictable:该页被锁住,不可回收。
PG_highmem:该页属于高端内存zone。
PG_writeback:该页正写回磁盘。
PG_reclaim:该页可被回收。
PG_compound:该页属于一个更大复合页,复合页用于管理大页面huge page。
PG_head:该页是一个复合页的head页。
PG_mlocked:该页mlock锁住,不被换出。
等待页面解锁:
wait_on_page_locked(struct page *page)
等待回写完毕:
wait_on_page_writeback(struct page *page)
struct file,struct inode,struct address_space关系总结(后续章节详解):
struct inode:打开文件时创建,代表一个打开文件。
struct inode:文件系统初始时创建,代表一个磁盘文件。
struct address_space:文件映射到内存的信息。
1. struct file和struct inode结构体中都有struct address_space指针。
struct inode->struct address_space *i_mapping->a_ops由文件系统生成inode时赋予。
如inode->i_mapping->a_ops = &jffs2_file_address_operations;
2. struct file-> struct address_space *f_mapping由struct inode的struct address_space i_mapping赋值
总结图: