当然,以下是学习二分算法的相关目录,以 Markdown 格式呈现:
二分算法学习目录
1. 二分算法简介
1.1 二分算法的定义
好的,小朋友,让我们通过一个寻宝游戏来理解二分算法。
假设你有一个魔法盒子,里面装了从 1 到 100 的数字卡片,这些卡片按照从小到大的顺序排列。现在,你的任务是找到写着数字 23 的卡片。
如果你一张一张地查看每个卡片,就像是从盒子的一端到另一端依次查看,这就类似于在数组中进行线性搜索。但是,如果你使用二分算法,你可以更快地找到数字 23。
二分算法就像是一个聪明的寻宝策略:
你先从盒子的中间拿出一张卡片,看看上面的数字。
- 如果这个数字正好是 23,太棒了,你找到宝藏了!
- 如果这个数字比 23 小,比如 15,那么 23 一定在盒子的后半部分。
- 如果这个数字比 23 大,比如 50,那么 23 一定在盒子的前半部分。
根据上一步的线索,你可以将查找范围缩小一半。如果 23 在后半部分,你就只需要在后半部分的卡片中继续寻找;如果 23 在前半部分,你就只需要在前半部分的卡片中继续寻找。
你重复步骤 1 和步骤 2,每次都可以将可能藏有宝藏的范围缩小一半,直到找到数字 23 或者确定 23 不在盒子里。
这就是二分算法的奥秘。它就像是一位聪明的探险家,通过不断缩小搜索范围,快速锁定宝藏的位置。
在计算机的世界里,这个魔法盒子就是一个有序的数组,数字卡片就是数组中的元素。二分算法帮助计算机在大量数据中快速找到所需的信息,就像你在寻宝游戏中快速找到目标卡片一样。
这就是二分算法的基本思想。它通过不断将问题的规模缩小一半,使得搜索的效率大大提高,特别是在处理大规模数据时,二分算法的优势就更加明显了。
1.2 二分算法的适用场景
假设你有一个很长的数字数组,里面的数字从小到大排列,就像这样:
[2, 5, 8, 12, 16, 23, 38, 56, 72, 91, 105, 120, 134, 150, 167, 182, 195]
你的任务是在这个数组里找到数字 72。
如果你从头到尾一个个检查每个数字,就像是线性搜索,这可能会花费很长时间,特别是当数组非常大的时候。但是,如果你使用二分算法,你可以快速地找到数字 72,因为数组里的数字是有序的。
现在,让我们看看一些二分算法不太适用的情况:
- 数组无序:
[38, 12, 91, 23, 72, 8, 105, 56, 150, 134, 167, 2, 182, 5, 195, 16, 120]
在这种情况下,二分算法无法工作,因为它依赖于数组的有序性。你可能需要先对数组进行排序,然后才能使用二分算法。
- 数组很小:
[2, 5, 8]
当数组很小的时候,使用二分算法的优势并不明显。在这种情况下,线性搜索可能更简单直观。
- 查找重复元素:
[2, 5, 8, 12, 12, 12, 23, 38, 56, 72, 91]
如果你需要找到所有的 12,标准的二分算法只能找到其中一个 12。你可能需要对二分算法进行一些修改,以找到重复元素的起始和结束位置。
所以,记住,二分算法最适用于大型有序数组的搜索。当你面对无序数组,很小的数组,或者需要查找重复元素的所有位置时,二分算法可能需要一些调整,或者可能不是最佳选择。
在实际的编程问题中,你经常会遇到需要在有序数组中查找特定元素的情况。这时,二分算法就可以大显身手,帮你快速找到目标元素,节省宝贵的时间和计算资源。
1.3 二分算法的时间复杂度
我们知道,二分算法每次都会将查找范围缩小一半,直到找到目标元素或确定目标元素不存在。这个过程有点像你在猜一个从1到100的数字,每次猜测后,我都会告诉你猜的数字是太大了还是太小了,然后你可以根据这个信息缩小猜测的范围,直到猜中为止。
现在,让我们想象一下,如果你要猜的数字范围是从1到16,最多需要猜几次就能确定答案呢?
- 第一次猜测:1到16的中间数是8,将范围缩小一半,现在范围是1到8或9到16。
- 第二次猜测:如果是1到8,中间数是4;如果是9到16,中间数是12。现在范围是1到4,5到8,9到12或13到16。
- 第三次猜测:无论之前的范围是哪一个,现在的范围都缩小到只有两个数或三个数。
- 第四次猜测:最多再猜一次,就可以确定答案。
所以,对于范围为16的数字,最多需要猜4次。如果我们将范围增加到32,最多需要5次;如果范围是64,最多需要6次。你会发现,每当范围增加一倍,所需的猜测次数就增加1。
这就是二分算法的奥秘所在。对于一个长度为n的有序数组,二分算法最多需要log₂(n)次比较就可以找到目标元素,这里log₂是以2为底的对数。这就是我们说二分算法的时间复杂度是O(log n)的原因。
让我们看一些具体的例子:
- 如果数组的长度是1024,二分算法最多需要比较10次,因为log₂(1024) = 10。
- 如果数组的长度是1,048,576,二分算法最多需要比较20次,因为log₂(1,048,576) = 20。
相比之下,线性搜索的时间复杂度是O(n),这意味着在最坏情况下,它需要比较n次才能找到目标元素。对于长度为1,048,576的数组,线性搜索最多需要比较1,048,576次,远远多于二分算法的20次。
所以,当数组的长度增加时,二分算法的优势就变得越来越明显。它的时间复杂度O(log n)保证了即使在处理大规模数据时,它的性能也能保持在一个很好的水平。
这就是二分算法的时间复杂度。它通过每次将问题规模减半,使得算法的运行时间与数据规模的关系变为对数级别,这在处理大规模数据时非常有效。
2. 二分查找
2.1 有序数组中的二分查找
题目链接:T438063 天秀的有序宝藏
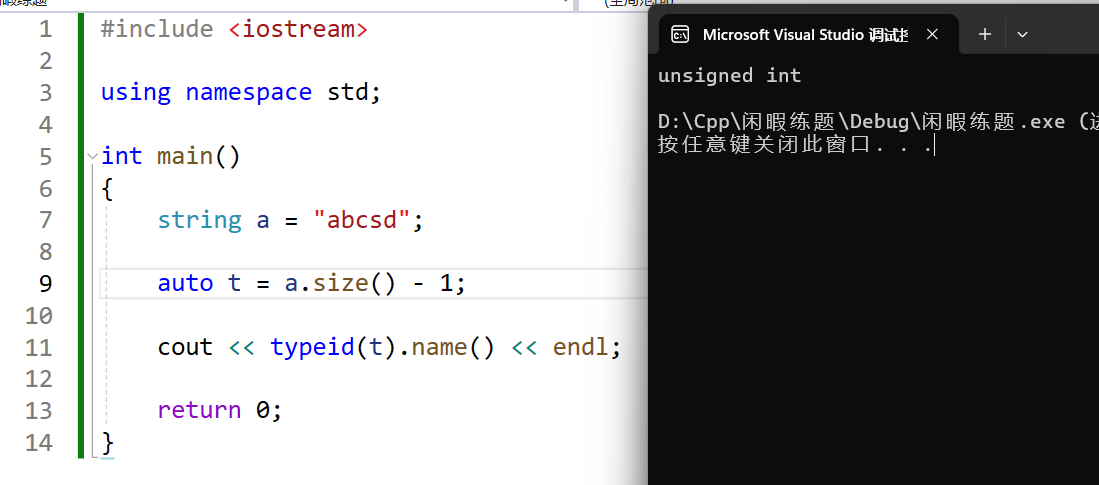
为了解决这个问题,我们可以使用C++来实现二分查找算法。下面是一个解决方案的示例代码:
#include <iostream>
#include <vector>
using namespace std;
// 二分查找函数
int binarySearch(const vector<int>& treasure, int target) {
int left = 0, right = treasure.size() - 1;
while (left <= right) {
int mid = left + (right - left) / 2; // 防止溢出
if (treasure[mid] == target) {
return mid; // 找到目标值,返回下标
} else if (treasure[mid] < target) {
left = mid + 1; // 在右侧子数组中查找
} else {
right = mid - 1; // 在左侧子数组中查找
}
}
return -1; // 未找到目标值,返回-1
}
int main() {
int n, target;
cin >> n >> target;
vector<int> treasure(n);
for (int i = 0; i < n; ++i) {
cin >> treasure[i];
}
int result = binarySearch(treasure, target);
cout << result << endl; // 输出结果
return 0;
}
这段代码首先定义了一个binarySearch函数,接受一个整数数组treasure和一个整数target作为参数,然后使用二分查找算法在数组中查找target。如果找到了target,函数返回它的下标;如果没有找到,则返回-1。
在main函数中,我们从标准输入读取数组的长度n和目标值target,以及数组treasure的所有元素。然后,调用binarySearch函数进行查找,并将结果输出到标准输出。
2.2 二分查找的变体
2.2.1 查找第一个等于目标值的元素
-T438065 天秀的重复宝藏
对于包含重复元素且需要找到目标元素第一次出现位置的问题,可以使用二分查找算法的变体。以下是一个C++解决方案的示例:
#include <iostream>
#include <vector>
using namespace std;
int findFirstOccurrence(const vector<int>& nums, int target) {
int left = 0, right = nums.size() - 1;
int result = -1; // 默认为-1,表示未找到
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target) {
result = mid; // 更新找到的位置
right = mid - 1; // 继续在左半部分查找是否有更早的出现位置
} else if (nums[mid] < target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return result;
}
int main() {
int n, target;
cin >> n >> target;
vector<int> treasure(n);
for (int i = 0; i < n; ++i) {
cin >> treasure[i];
}
cout << findFirstOccurrence(treasure, target) << endl;
return 0;
}
这段代码首先定义了一个findFirstOccurrence函数,使用二分查找的变体来寻找目标值target第一次出现的位置。主函数main从标准输入读取数组长度n、目标值target和数组元素,然后调用findFirstOccurrence函数,并打印出目标值第一次出现的下标。如果目标值不存在于数组中,函数将返回-1。
此解决方案假设输入的数组是按升序排列的,且可能包含重复元素。当找到一个与目标值相等的元素时,算法尝试向左移动,以找到可能存在的更早的出现位置。这是因为即使找到了目标值,前面仍然有可能有相同的值。
内置函数的方法
在C++中,可以使用标准库中的lower_bound函数来解决这个问题。lower_bound在一个有序范围内查找第一个不小于给定值的元素,正好适合寻找目标值第一次出现的位置。如果找到了目标值,它会返回一个指向该值的迭代器;如果没有找到,则返回一个指向第一个比目标值大的元素的迭代器,或者如果所有元素都比目标值小,则返回一个指向末尾的迭代器。
下面是使用lower_bound来解决“天秀的重复宝藏”问题的C++代码示例:
#include <iostream>
#include <vector>
#include <algorithm> // 包含 lower_bound
using namespace std;
int main() {
int n, target;
cin >> n >> target;
vector<int> treasure(n);
for (int i = 0; i < n; ++i) {
cin >> treasure[i];
}
// 使用 lower_bound 查找 target 第一次出现的位置
auto it = lower_bound(treasure.begin(), treasure.end(), target);
// 检查是否找到 target
if (it != treasure.end() && *it == target) {
// 输出下标,需要注意的是,C++中的迭代器和下标之间的转换
cout << (it - treasure.begin()) << endl;
} else {
cout << -1 << endl;
}
return 0;
}
这段代码首先读取数组的大小和目标值,然后读取数组元素。接着,它使用lower_bound在数组中查找目标值第一次出现的位置。最后,如果找到了目标值,则输出其下标;如果没有找到,则输出-1。需要注意的是,因为lower_bound返回的是一个迭代器,所以如果需要输出下标,需要将迭代器转换为下标。这可以通过计算迭代器和容器开始迭代器之间的距离来实现。
2.2.2 查找最后一个等于目标值的元素
T438066 天秀的宝藏终点
为了找到目标值在有序数组中最后一次出现的位置,我们可以通过稍微修改二分查找的算法来实现。基本思想是当我们找到一个目标值时,不立即返回,而是继续在右侧查找,以确定是否有相同的值出现在更后面的位置。
下面是使用C++实现的解决方案:
#include <iostream>
#include <vector>
using namespace std;
int findLastOccurrence(const vector<int>& nums, int target) {
int left = 0, right = nums.size() - 1;
int result = -1; // 默认为-1,表示未找到
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target) {
result = mid; // 更新找到的位置
left = mid + 1; // 继续在右半部分查找是否有更晚的出现位置
} else if (nums[mid] < target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return result;
}
int main() {
int n, target;
cin >> n >> target;
vector<int> treasure(n);
for (int i = 0; i < n; ++i) {
cin >> treasure[i];
}
cout << findLastOccurrence(treasure, target) << endl;
return 0;
}
这段代码定义了findLastOccurrence函数,该函数接收一个按升序排列的整数数组nums和一个整数target作为参数,返回target在数组中最后一次出现的下标。如果target不存在于数组中,则返回-1。主函数main从标准输入读取数组的长度和目标值,然后读取数组元素,并调用findLastOccurrence函数。最后,它打印出目标值最后一次出现的下标。
内置函数版本
要使用C++的内置函数解决“天秀的宝藏终点”问题,即找到目标值在有序数组中最后一次出现的位置,可以使用upper_bound函数。upper_bound函数返回一个指向给定值在有序范围内第一个大于该值的元素的迭代器。因此,要找到目标值最后一次出现的位置,我们可以找到upper_bound返回的位置的前一个位置,这个位置即为目标值最后一次出现的位置(前提是目标值确实存在于数组中)。
下面是使用upper_bound来解决这个问题的C++代码示例:
#include <iostream>
#include <vector>
#include <algorithm> // 包含 upper_bound
using namespace std;
int main() {
int n, target;
cin >> n >> target;
vector<int> treasure(n);
for (int i = 0; i < n; ++i) {
cin >> treasure[i];
}
// 使用 upper_bound 查找第一个大于 target 的元素
auto it = upper_bound(treasure.begin(), treasure.end(), target);
// 检查目标值是否存在于数组中
if (it != treasure.begin() && *(it - 1) == target) {
// 输出最后一次出现的下标
cout << (it - treasure.begin() - 1) << endl;
} else {
cout << -1 << endl;
}
return 0;
}
这段代码首先读取数组的大小和目标值,然后读取数组元素。接着,它使用upper_bound在数组中查找第一个大于目标值的元素。如果找到的元素不是数组的第一个元素且前一个元素等于目标值,则说明目标值存在于数组中,并且最后一次出现的位置就是upper_bound返回的迭代器的前一个位置。然后,代码通过计算迭代器和数组开始的迭代器之间的距离来输出最后一次出现的下标。如果目标值不存在于数组中,则输出-1。
2.2.3 查找第一个大于等于目标值的元素
T438067 天秀的宝藏起点
为了找到数组中第一个大于等于特定值target的元素的位置,我们可以直接使用C++标准库中的lower_bound函数。lower_bound函数在给定的有序范围内查找第一个不小于(即大于或等于)给定值的元素。如果找到这样的元素,它返回一个指向该元素的迭代器;如果所有元素都小于target,则返回一个指向范围末尾的迭代器。
以下是解决“天秀的宝藏起点”问题的C++代码示例:
#include <iostream>
#include <vector>
#include <algorithm> // 包含 lower_bound
using namespace std;
int main() {
int n, target;
cin >> n >> target;
vector<int> treasure(n);
for (int i = 0; i < n; ++i) {
cin >> treasure[i];
}
// 使用 lower_bound 查找第一个不小于 target 的元素
auto it = lower_bound(treasure.begin(), treasure.end(), target);
// 输出找到元素的下标,如果所有元素都小于 target,则输出 n
cout << (it - treasure.begin()) << endl;
return 0;
}
这段代码首先读取数组的大小和目标值,然后读取数组元素。接着,它使用lower_bound在数组中查找第一个不小于目标值的元素。最后,代码通过计算迭代器和数组开始的迭代器之间的距离来输出找到的元素的下标。如果lower_bound返回的迭代器指向数组的末尾(即所有元素都小于target),则按照题目要求输出数组的长度。
2.2.4查找所有等于目标值的元素个数
T438068 天秀的宝藏计数
要计算目标值在有序数组中出现的次数,我们可以使用C++标准库中的lower_bound和upper_bound函数。lower_bound函数用于找到第一个不小于目标值的元素的位置,而upper_bound函数用于找到第一个大于目标值的元素的位置。目标值的出现次数即为这两个位置的差。
以下是解决“天秀的宝藏计数”问题的C++代码示例:
#include <iostream>
#include <vector>
#include <algorithm> // 包含 lower_bound 和 upper_bound
using namespace std;
int main() {
int n, target;
cin >> n >> target;
vector<int> treasure(n);
for (int i = 0; i < n; ++i) {
cin >> treasure[i];
}
// 使用 lower_bound 查找第一个不小于 target 的元素的位置
auto lower = lower_bound(treasure.begin(), treasure.end(), target);
// 使用 upper_bound 查找第一个大于 target 的元素的位置
auto upper = upper_bound(treasure.begin(), treasure.end(), target);
// 计算 target 出现的次数
cout << (upper - lower) << endl;
return 0;
}
这段代码首先读取数组的大小和目标值,然后读取数组元素。接着,它使用lower_bound和upper_bound在数组中查找目标值的边界位置。通过计算这两个位置的差值,即可得到目标值在数组中出现的次数。如果目标值不存在于数组中,lower_bound和upper_bound将返回相同的位置,因此出现次数为0。
不需要内置函数版本
如果不使用C++的内置函数来解决这个问题,我们可以手动实现二分查找的变体来分别找到目标值第一次出现的位置和最后一次出现的位置。目标值的出现次数即为这两个位置的差加一。
以下是不使用内置函数版本的C++代码示例:
#include <iostream>
#include <vector>
using namespace std;
// 查找目标值第一次出现的位置
int findFirst(const vector<int>& nums, int target) {
int left = 0, right = nums.size() - 1, result = -1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target) {
result = mid;
right = mid - 1; // 继续向左查找
} else if (nums[mid] < target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return result;
}
// 查找目标值最后一次出现的位置
int findLast(const vector<int>& nums, int target) {
int left = 0, right = nums.size() - 1, result = -1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target) {
result = mid;
left = mid + 1; // 继续向右查找
} else if (nums[mid] < target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return result;
}
int main() {
int n, target;
cin >> n >> target;
vector<int> treasure(n);
for (int i = 0; i < n; ++i) {
cin >> treasure[i];
}
int first = findFirst(treasure, target);
int last = findLast(treasure, target);
// 如果目标值不存在于数组中,则输出0
if (first == -1) cout << 0 << endl;
else cout << (last - first + 1) << endl;
return 0;
}
这个解决方案首先定义了两个辅助函数findFirst和findLast,分别用于查找目标值第一次和最后一次出现的位置。主函数读取输入,然后调用这两个函数来确定目标值的边界位置,最后计算并输出目标值出现的次数。如果目标值不存在于数组中,findFirst函数会返回-1,此时直接输出0。
2.2.4 有序数组中查找第 k 小元素
T438069 天秀的无序宝藏
解决这个问题,我们需要一个算法能够在部分排序的数组中找到第k小的元素。由于数组被分为若干个已排序的部分,直接使用快速选择算法可能不适用,因为快速选择需要在整个数组上进行分区。相反,我们可以利用这些已排序部分的信息,通过比较各部分的首尾元素,找到一个合适的方法来寻找第k小的元素。
但在题目给定的条件下,没有一个直接的、高效的方法能够直接应用于这种部分排序的数组。一个可能的解决方案是将数组的所有元素复制到一个新的数组中,对这个新数组进行全排序,然后直接访问第k小的元素。虽然这种方法在效率上不是最优的,但它提供了一种简单直接的解决方案。
考虑到题目的复杂性,下面提供了一个简化的C++解决方案,该方案首先将数组完全排序,然后直接找到第k小的元素:
#include <iostream>
#include <vector>
#include <algorithm> // 用于 std::sort
using namespace std;
int main() {
int n, k;
cin >> n >> k;
vector<int> candies(n);
for (int i = 0; i < n; ++i) {
cin >> candies[i];
}
// 对数组进行完全排序
sort(candies.begin(), candies.end());
// 直接输出第k小的元素
cout << candies[k - 1] << endl;
return 0;
}
这段代码首先读取糖果的数量和要找的第k小的糖果。然后,它读取每个糖果的甜度并存储在一个数组中。使用std::sort对整个数组进行排序后,直接通过索引访问找到第k小的元素。
请注意,这种方法忽略了题目中提到的数组部分排序的特性,而是采取了更通用但效率较低的全排序方法。在实际应用中,如果有关于数组部分排序段的更多信息,可能会有更高效的算法来解决这个问题。






















![[热门]通义灵码做活动,送挺多礼品,快来薅羊毛!!!](https://img-blog.csdnimg.cn/direct/3fd2b17ffeeb43b6839f39c9890ee7ad.png)