上海交大梁晓峣:开源GPGPU平台为国产AI芯片企业谋出路 - 知乎
GitHub - SJTU-ACA-Lab/blue-porcelain
开源的GPU架构相对较少,因为GPU设计涉及复杂的硬件和软件交互,而且大多数商业公司如NVIDIA、AMD和Intel等将其GPU架构视为专有技术。然而,还是有一些开源项目和学术研究在致力于创建开源的GPU架构或相关组件。以下是一些已知的开源GPU架构或相关项目:
Mesa 3D Graphics Library: 如前所述,Mesa不是一个完整的GPU架构,但它是一个开源的图形驱动库,提供了OpenGL的实现,并支持多种GPU。它包含了许多开源显卡驱动程序,使得开发者可以更容易地与GPU硬件进行交互。
Nouveau: Nouveau是为NVIDIA显卡开发的开源驱动程序,它是基于Mesa的,并且试图提供对NVIDIA硬件的完全开源支持。然而,由于NVIDIA的专有性质,Nouveau的功能可能有限。
RADV / AMDVLK: 这些是为AMD显卡提供的开源Vulkan驱动程序。RADV是基于Mesa的Vulkan驱动程序,而AMDVLK是AMD官方提供的开源Vulkan驱动程序。这些驱动程序允许开发者利用Vulkan API与AMD GPU进行交互。
Intel Open Source Graphics Drivers: 正如之前提到的,Intel为其集成显卡和核心显卡提供了基于Mesa的开源图形驱动程序。
RISC-V Vector Extension: RISC-V是一个开源的指令集架构(ISA),有一个正在开发中的向量扩展,用于支持类似于现代GPU中的SIMD(单指令多数据)操作。尽管这不是一个完整的GPU架构,但它为在开源ISA中集成GPU功能提供了一个范例。
学术研究项目: 大学和研究机构可能进行自己的GPU架构研究项目。这些通常是实验性的,并且可能不会广泛发布。要获取这些项目的信息,可能需要查阅相关的学术论文和会议记录。
MIAOW或其他类似项目: MIAOW是一个基于AMD GCN指令集的开源GPGPU实现,用于学习和研究目的。虽然它不是一个完整的GPU架构,但它展示了如何在开源环境中模拟GPU功能。类似的项目可能存在于学术圈或开源社区中,但可能不为广大公众所知。
RTL模型(Register Transfer Level Model)和C模型(C Model)是电子系统设计中两种不同层次的模型,它们在描述系统时的抽象级别和实现方式上有所不同。
RTL模型:RTL(寄存器传输级)模型是电子系统设计中的一个较低层次的模型,它描述了数据在寄存器之间的流动和逻辑操作。RTL模型通常使用硬件描述语言(如VHDL或Verilog)来编写,可以精确地描述硬件电路的行为和结构。这种模型在电路设计和验证阶段非常有用,因为它可以模拟实际硬件的行为,并可以用于生成实际的电路实现。
C模型:C模型是一个较高层次的模型,使用C语言或类似的高级语言来描述系统的行为。C模型更注重于算法和功能的描述,而不是硬件的具体实现。因此,C模型通常更容易编写和理解,但它们可能无法精确地模拟硬件的所有细节。C模型在系统设计的早期阶段非常有用,可以用于快速原型设计和算法验证。
至于为什么RTL模型一般不开源,这可能有以下几个原因:
知识产权:RTL模型通常包含公司或设计团队的知识产权,包括电路设计、算法实现等。因此,为了保护这些知识产权,设计团队可能选择不开源RTL模型。
安全性:在某些情况下,RTL模型可能包含敏感信息,如加密算法、密钥等。这些信息如果泄露出去,可能会对公司的安全造成威胁。因此,为了保护这些敏感信息,设计团队可能选择不开源RTL模型。
复杂性:RTL模型通常比C模型更复杂,因为它们需要更精确地描述硬件的行为和结构。这意味着RTL模型的代码可能更难理解和维护。如果开源RTL模型,可能需要投入更多的资源来支持社区的使用和维护,这对于一些公司来说可能是一个负担。
虽然RTL模型一般不开源,但并不意味着它们无法被其他人使用或访问。在某些情况下,设计团队可能会提供RTL模型的接口或仿真环境,以便其他人可以使用这些模型进行验证和测试。此外,一些开源项目也可能会提供RTL模型的实现,但这些实现通常需要遵守特定的许可证和使用协议。
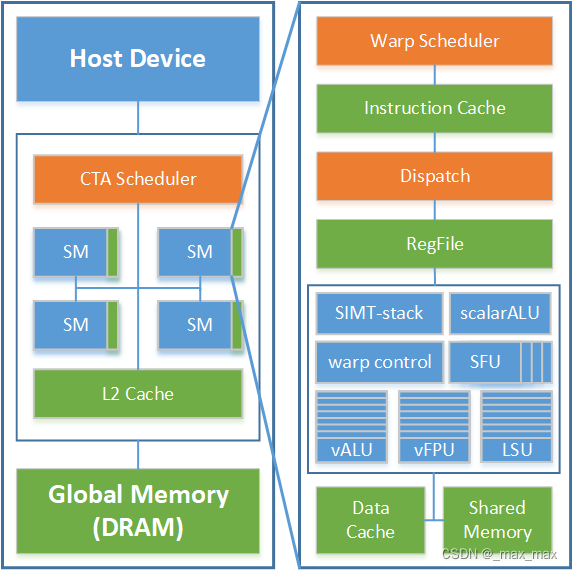
GPGPU(General-Purpose Graphics Processing Unit,通用图形处理器)是一种将图形处理单元(GPU)用于除图形渲染之外的通用计算任务的处理器。在GPGPU中,线程的调度和管理是通过GPU的硬件和软件架构来实现的。
- 硬件架构:
GPGPU的硬件架构通常包括多个处理核心(或称为流处理器、CUDA核心等),每个核心都能够同时执行多个线程。这些核心被组织成多个处理单元(如SM、CU等),每个处理单元都有自己的线程调度器、寄存器文件、共享内存等资源。
线程调度器负责将线程分配给处理单元中的核心进行执行。它根据线程的优先级、依赖关系以及其他因素来决定哪个线程应该在下一个时钟周期中执行。调度器可以采用不同的策略,如轮询、优先级队列等,以确保线程能够公平地访问处理单元的资源。
- 软件架构:
在软件层面,GPGPU通常提供了一套编程模型(如CUDA、OpenCL等),用于编写并行计算程序。这些编程模型提供了一组API和编程语言扩展,使开发人员能够利用GPU的并行处理能力。
在编程模型中,线程被组织成线程块(或工作组),每个线程块包含一组线程,这些线程在GPU上并行执行。开发人员可以通过编程模型提供的API来指定线程块的大小、线程的索引等信息,以便在GPU上正确地调度和管理线程。
此外,编程模型还提供了同步和通信机制,以确保线程之间的正确协作。例如,开发人员可以使用屏障(barrier)来确保线程块中的所有线程都完成某个阶段的工作后再继续执行下一阶段的任务。还可以使用共享内存、原子操作等机制来实现线程之间的数据共享和互斥访问。
GPGPU通过硬件和软件架构的结合来实现线程的调度和管理。硬件架构提供了多个处理核心和线程调度器来支持并行执行和线程分配,而软件架构则提供了编程模型和API来编写并行计算程序并管理线程的执行和协作。
线程调度器是操作系统或运行时环境中的一个组件,它负责决定哪个线程在什么时候获得处理器资源以执行其任务。线程调度器的工作方式取决于其采用的调度策略和算法。以下是线程调度器通常如何工作的一些关键点:
- 调度策略:
- 优先级调度:线程被赋予优先级,调度器倾向于先运行优先级高的线程。
- 时间片轮转:每个线程被分配一个固定的时间片来执行,当时间片用完时,线程被暂停,调度器选择下一个线程执行。
- 短作业优先:调度器估计线程的运行时间,并倾向于先运行预计完成时间短的线程。
- 多级反馈队列:结合优先级和时间片轮转,线程可以在不同优先级队列之间移动。
- 线程状态:
- 线程可以处于不同的状态,如就绪(等待执行)、运行(正在执行)、阻塞(等待某些条件满足,如I/O操作完成)。
- 调度器只管理处于就绪状态的线程,并根据调度策略选择一个线程来执行。
- 上下文切换:
- 当调度器决定从一个线程切换到另一个线程时,它必须保存当前线程的执行上下文(包括寄存器状态、程序计数器、内存状态等),并加载下一个线程的上下文。
- 上下文切换是有开销的,因为它涉及到保存和加载大量数据,因此调度器会尽量减少不必要的上下文切换。
- 调度时机:
- 调度器可能在多种情况下进行调度决策,如当前线程完成、当前线程阻塞、当前线程的时间片用完、或系统负载发生变化时。
- 公平性:
- 调度器应确保所有线程都有机会执行,避免某些线程长时间得不到处理器资源而导致的饥饿现象。
- 预调度和后调度:
- 在某些系统中,调度决策可以在实际上下文切换之前(预调度)或之后(后调度)进行。
- 多处理器和多核调度:
- 在多处理器或多核系统中,调度器需要管理多个处理器核心,并决定哪个线程在哪个核心上执行。
- 调度器实现:
- 调度器可以是操作系统内核的一部分,也可以是用户空间运行时环境(如Java虚拟机或Python解释器)的一部分。
- 内核级调度器负责所有进程的线程调度,而用户空间调度器通常只负责管理特定应用程序内部的线程。
GPGPU(通用图形处理器)的线程调度器是其架构中的关键组件,负责管理和调度在GPU上执行的线程,以实现高效的并行计算。以下是GPGPU线程调度器的详细介绍:
- 线程组织:
- 在GPGPU中,线程通常被组织成线程块(或工作组),每个线程块包含多个线程。这些线程块再被分配到GPU的流式多处理器(SM)上执行。
- 每个线程块内的线程可以以线程束(warp)为单位进行调度。线程束是一组同时执行的线程,它们执行相同的指令,但处理不同的数据。
- 资源分配:
- 线程块调度器负责将线程块分配给SM。它考虑SM上的可用资源,如线程空间、寄存器、共享存储器等,以决定哪个线程块可以执行。
- 当一个线程块完成执行或达到某个同步点时,其占用的资源被释放,线程块调度器可以选择新的线程块来填补这些空闲资源。
- 轮询策略:
- 简单的轮询策略可用于线程块调度,确保每个SM都有机会执行线程块,从而维持负载均衡。
- 但轮询策略可能会破坏线程块间的空间局部性,因为ID相近的线程块在内存中的数据通常也是相近的。
- 两级调度:
- 为了改进长延迟操作的处理,可以采用两级调度策略。在这种策略中,线程束被分成组(fetch group),并且组间使用优先级顺序进行轮询。
- 当一个组中的所有线程束都遇到长延迟操作(如访存指令)时,它的优先级降低,而其他组的优先级提升。这样,可以交错执行不同组的线程束,隐藏长延迟操作。
- 调度决策因素:
- 线程调度器的决策可能受到多种因素的影响,包括线程的优先级、线程块的同步需求、内存访问模式等。
- 高优先级的线程或线程块可能优先于低优先级的线程执行,以满足实时性或其他性能要求。
- 硬件实现:
- GPGPU的线程调度器在硬件层面实现,它可能包括复杂的控制逻辑和状态机,用于跟踪线程状态、管理资源分配和执行调度决策。
- 硬件线程调度器的设计需要在灵活性和效率之间进行权衡,以支持不同的应用程序和工作负载。
- 与编程模型的交互:
- 开发人员通过GPGPU的编程模型(如CUDA或OpenCL)来编写并行计算程序,并指定线程组织和同步模式。
- 编程模型提供的API和工具可以帮助开发人员理解线程调度器的行为,并优化程序以更好地利用GPGPU的资源。
GPGPU的线程调度器是一个复杂的组件,它负责在GPU上高效地调度和管理并行线程的执行。通过结合不同的调度策略和硬件优化,线程调度器可以显著提高GPGPU的性能和效率。