动态规划问题真是属于那种刷了忘忘了刷啊
背包问题概述
- 0-1 背包问题:每种物品只能选择放入或不放入背包一次。
- 完全背包问题:每种物品可以无限次选择放入背包。
- 多重背包问题:每种物品有限定的数量,可以选择放入背包多次,但不超过这个数量。
- 分组背包问题:物品被分为若干组,每组中的物品互斥,即从每组中最多只能选一个放入背包。
经典0/1背包问题
题目
已知重量和价值的 n 件物品,以及一个用来装这些物品的背包。背包不能装载超过一定最大重量的物品。
需要使背包中物品的总价值最大化,同时确保所选物品的重量之和不超过背包的容量。
如果没有在容量限制范围内的组合方式则返回0。
思路
初始化动态数组,需要注意多初始一行一列,为“真正的”第一行第一列生成数据做准备
对于此题目的动态数组,dp[i][w]的含义为考虑前i个物品,在背包容量不超过w的条件下可以获得的最大价值,也就是说列代表了容量,一直变大,行代表了商品,一行一个商品
- 遍历过程中,我们需要考虑到前i个物品,容量为w,如果i物品的相应容量比我们的w小或者相等,证明可以装下
不加入物品
i到背包:不把物品加入背包,背包的最大价值要继承dp数组里i-1(不考虑第i个物品)行,w(容量还是w大小)列的值。加入物品
i到背包:考虑第i个物品,则需要考虑i-1个物品在背包容量为w-i的重量时所获的最大值以及第i个物品价值作为这个单元格的值。最后返回最右下角的值,这里是在整个背包容量下考虑所有物品放入背包的最大价值。
代码
def knapsack(values, weights, capacity):
n = len(values)
dp = [[0 for _ in range(capacity + 1)] for _ in range(n + 1)]
for i in range(1, n + 1):
for w in range(1, capacity + 1):
if weights[i-1] <= w:
# 如果当前物品可以加入背包
dp[i][w] = max(dp[i-1][w], dp[i-1][w-weights[i-1]] + values[i-1])
else:
# 如果当前物品不能加入背包
dp[i][w] = dp[i-1][w]
return dp[n][capacity]
完全背包问题 leetcode322题
题目
给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。
计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。
你可以认为每种硬币的数量是无限的。
示例 1:
输入:coins =[1, 2, 5], amount =11输出:3解释:11 = 5 + 5 + 1
示例 2:
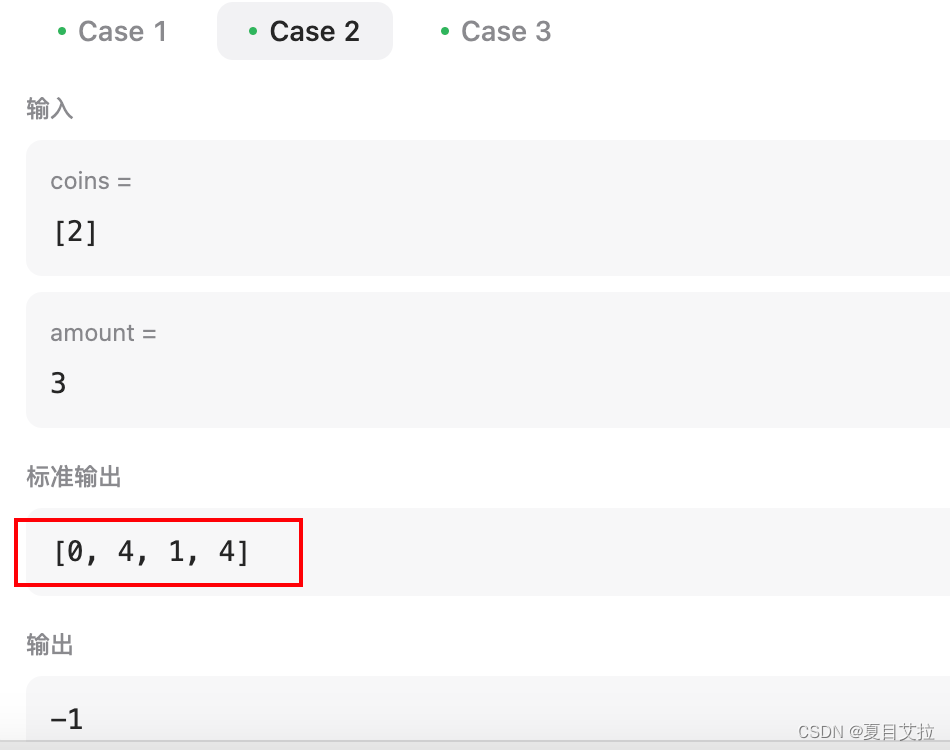
输入:coins =[2], amount =3输出:-1
示例 3:
输入:coins = [1], amount = 0 输出:0
提示:
1 <= coins.length <= 121 <= coins[i] <= 231 - 10 <= amount <= 104
思路
初始化动态数组,这里只要看总和为i的物品总价值怎么凑,所以动态数组就一行,同样多初始化一列,需要注意第一列为0容易理解,即凑0元钱不需要任何物品,其他的动态数组值为了后面代码方便统一初始化为一个较大的值
遍历i,i代表了需要凑的总价值,对于所有的coin面值,如果i比coin大或者相等,此时i这里的值要进行更新
更新为此时现有的凑法硬币数量,以及价值i减去此coin值凑法硬币数量两者硬币最小的那种方式的硬币数量
最后返回时检查需要凑的价值哪个单元格值是否小于amount + 1(我们为动态数组设置的初始值),如果小于,则证明有解,返回dp数组中这个解即可
补充说明
当硬币不能正好凑成amount数,但是可以凑的大于amount数的情况,dp数组如下
可以得知我们的方法有效,如果dp[amount]有值,证明amount确实是可以被凑成的
代码
此题目的动态数组由于只有一个需要考虑的维度
def coinChange(coins, amount):
dp = [amount + 1] * (amount + 1)
dp[0] = 0
for i in range(1, amount + 1):
for coin in coins:
if i - coin >= 0:
dp[i] = min(dp[i], dp[i - coin] + 1)
return dp[amount] if dp[amount] < amount + 1 else -1
较为特殊的完全背包问题 leetcode139题
题目
给你一个字符串 s 和一个字符串列表 wordDict 作为字典。如果可以利用字典中出现的一个或多个单词拼接出 s 则返回 true。
注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。
示例 1:
输入: s = "leetcode", wordDict = ["leet", "code"] 输出: true 解释: 返回 true 因为 "leetcode" 可以由 "leet" 和 "code" 拼接成。
示例 2:
输入: s = "applepenapple", wordDict = ["apple", "pen"] 输出: true 解释: 返回 true 因为"applepenapple"可以由"apple" "pen" "apple" 拼接成。 注意,你可以重复使用字典中的单词。
示例 3:
输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"] 输出: false
思路
本题也可以回溯法解决
初始化dp数组,多初始化一列,返回的是True和False,所以让除第一个元素以外所有元素都为False
如果dp[j]可以被组合成功且从j到i部分的字符串在wordDict内,则可以让dp[i]为True,因为可以被组合得到
代码
class Solution(object):
def wordBreak(self, s, wordDict):
dp = [False] * (len(s) + 1)
dp[0] = True
for i in range(1, len(s) + 1):
for j in range(i):
if dp[j] and s[j:i] in wordDict:
dp[i] = True
break
return dp[len(s)]1143. 最长公共子序列
题目
给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。
一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
- 例如,
"ace"是"abcde"的子序列,但"aec"不是"abcde"的子序列。
两个字符串的 公共子序列 是这两个字符串所共同拥有的子序列。
示例 1:
输入:text1 = "abcde", text2 = "ace" 输出:3 解释:最长公共子序列是 "ace" ,它的长度为 3 。
示例 2:
输入:text1 = "abc", text2 = "abc" 输出:3 解释:最长公共子序列是 "abc" ,它的长度为 3 。
示例 3:
输入:text1 = "abc", text2 = "def" 输出:0 解释:两个字符串没有公共子序列,返回 0 。
提示:
1 <= text1.length, text2.length <= 1000text1和text2仅由小写英文字符组成。
思路
老样子初始化,老样子遍历
dp构造依据
当
text1[i-1] == text2[j-1]时:这个字符一定属于两个字符串的公共子序列。当
text1[i-1] != text2[j-1]时:最长公共子序列要么在text1的前i-1个字符与text2的前j个字符之间,要么在text1的前i个字符与text2的前j-1个字符之间。要注意
text1[i-1] == text2[j-1]时,dp[i][j]直接 = dp[i-1][j-1] + 1
代码
class Solution(object):
def longestCommonSubsequence(self, text1, text2):
m, n = len(text1), len(text2)
dp = [[0] * (n + 1) for _ in range(m + 1)]
for i in range(1, m+1):
for j in range(1, n+1):
if text1[i-1] == text2[j-1]:
dp[i][j] = dp[i-1][j-1] + 1
else:
dp[i][j] = max(dp[i-1][j], dp[i][j-1])
return dp[m][n]