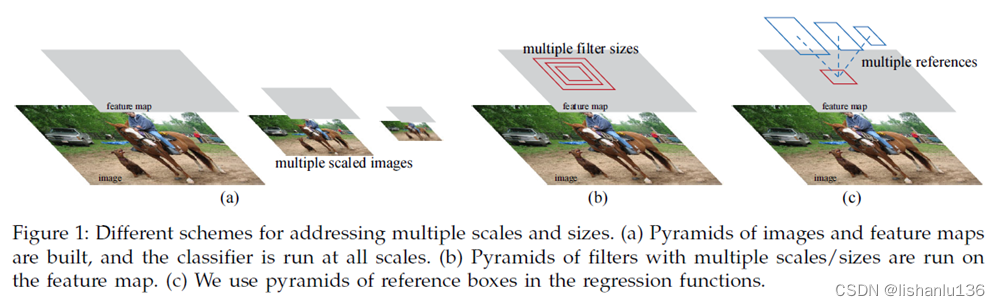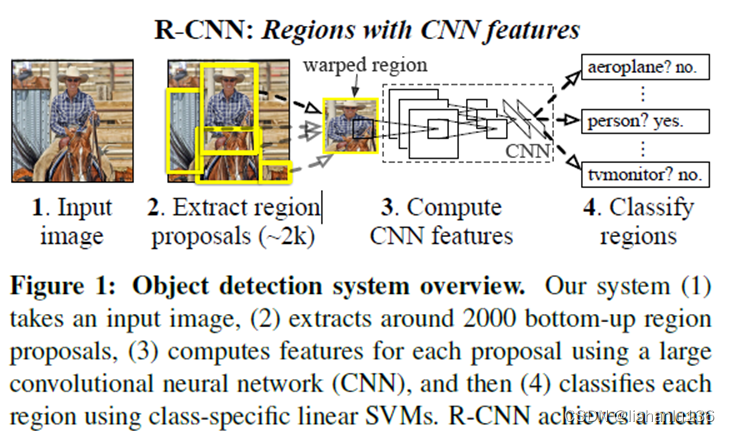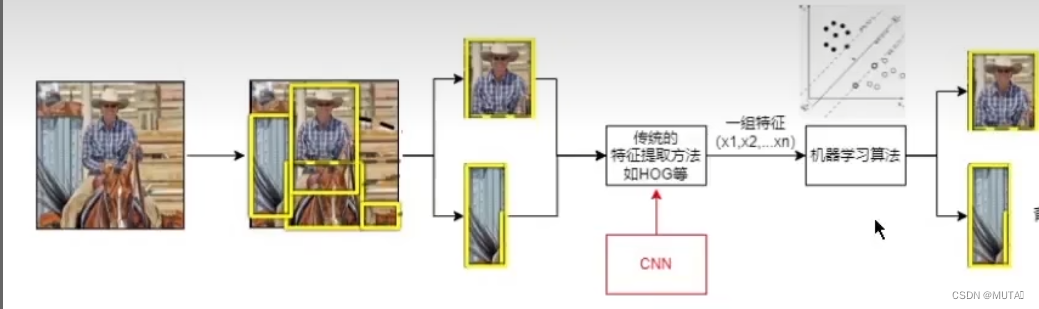
在该论文提出之前,主流的目标检测思路是: 将一幅图片划分成很多个区域,单独提取出来 对于每个区域使用传统的特征提取方法提取 提取结束后可以使用以为特征向量表示 可以用预处理好的机器学习算法对提取到的特征向量分类
当时Alex Net取得了很好的成就,所以该篇论文是想将深度学习替换调传统的特征提取方法
摘要
两大特点:
- 用元及神经网络替换传统特征提取方法
- 由于数据集较少,使用了迁移学习的方法更好提升目标检测效果——RCNN
对比了R-CNN和OverFeat(OverFeat也是使用的cnn来特征提取)
一 引言
目标检测的传统思路发展受限
尝试解释传统思路为什么受限(讲故事)
从CNN在图像分类任务的成功引出本文的思路:
待解决的两个问题
如何使用CNN定位目标?

对于目标分类而言,给一张图片只需要识别出这张图片所属的类别; 对于目标检测而言,CNN需要识别出多个目标所在的位置和所属类别;
思路
思路1: 用CNN把坐标预测出来,把定位目标当作一个回归问题(无效)
思路2: 使用滑动窗口在图像上进行滑动,对每一个窗口使用浅层CNN检测,但该方法大多适用于人脸、行人等比例固定的待检测目标;而且使用的是浅卷积神经网络,但作者想使用的是比较深的、检测效果好的深层卷积神经网络;
思路3:基于区域的识别方法

输入一张图片,先使用一种特定的算法提取出不同的候选区域(大小不同);对于每个候选区域使用一个深的CNN提取这个区域的图片特征; 由于CNN需要输入尺寸一致,因此需要把每个区域缩放到特定的尺寸大小再传入CNN; 通过CNN提取到的区域特征后通过特定分类器对区域进行分类,从而得知区域所属类别。
标注数据太少?
图像分类:ImageNet; 目标检测:PASCAL VOC;(当时很少)
思路
思路1: 传统:无监督的预训练配合有监督的微调;
思路2: 先在数据量大的数据集上做有监督的训练,再在小的数据集上进行微调,通过迁移学习的思路解决数据不够的问题;
二 使用R-CNN目标检测
2.1 模块设计
产生候选区域
算法:objectness、selective search、category-independent、object proposals、 constrained parametric min-cuts(CPMC)、multi-scale combinatorial grouping、Ciresan等
选用了selective search这种方法
提取图片特征

利用CNN提取这个区域的特征,使用的AlexNet图像分类网络;
由于原始的AlexNet是使用在imageNet这种大型的图像分类数据集上,因此最后一层全连接层输出为1000个分类类别,在这里我们可以把最后一层输出的类别删掉,使用第二个全连接层的输出(4096维的输出)来作为每一个候选区域的图像特征;
AlexNet输入必须是尺寸相等的图片,但由于在上一步候选框生成的区域大小不一,因此需要转换为特定大小;(输入图片转为特定大小)
注意:上述得到的候选区域并不是直接截下来,而是多出一小部分,因为在做卷积神经网络的时候,边缘会损失一些信息;
![]()
这里的16就是比原候选区域多出16个像素(为什么是16?因为在做完卷积后图像比原图缩放了32倍,上下左右各多16个像素则整体多了32倍
如何利用候选区对特征进行分类
支持向量机(SVM)——容易实现二分类;
使用多个支持向量机判断候选区域所属类别;
2.2 R-CNN测试流程
采用selective search算法在测试图片上产生大约2000个候选区域;
把每个候选区域缩放到227 * 227 大小;
通过一次前向传播,使用CNN获得特征;
对于每一个提取到的特征向量我们都需要使用一个二分类的SVM对每一个类别进行预测;
将2000个候选区域预测后,就可以得到一张图片上的所有目标框了;
将所有目标框进行非极大抑制算法(NMS),除掉冗余的目标框;
R-CNN为什么高效?
所有参数是可以跨类别、共享的(即对于一个候选区域,不需要注意它的类别,直接传入CNN提取特征);
CNN提取到的候选框特征维数很低(4096),其他方法提取到的方法维数到达(360k); 维数越高,计算约复杂;
R-CNN唯一针对特定类执行特定计算的操作: 图片特征和SVM 权重之间的点集操作; 非极大值抑制(NMS)算法;
使用矩阵运算,可分别上千的类别(添加列向量):

2.3 训练
有两个特征模块需要训练;
第一个:CNN特征提取网络模型; 第二个:支持向量机SVM模型;
CNN特征提取网络模型
先在大的image net数据集上做有监督的预训练,得到图像分类模型;
再在VOC上做微调;
微调方法: 将原先在image net训练的得到图像分类网络的最后一层(图像分类类别,原来是1000类)改为N+1(N=20),+1是因为添加了一个背景类别;

对于imageNet,它有大量的图片并分好了类别; 对于PASCAL VOC,它是一张图片上标注出了目标所在的框以及所属类别;与专门的图像分类数据集有区别;
怎么利用VOC标注数据训练分类模型?
把标注框直接截下来,但这样有问题,因为在预测图片时,会产生两千个候选框,位置随机,所以训练网络时候,不光需要利用标注区域,还需要其他区域,以便网络可以学习到图片的各个位置的特征;
因此可以把这2000个区域和标注框做一个IoU计算,当IoU≥0.5 时,将它作为正样本;否则为负样本;
通常在图片中目标所占的这个比例是比较小的,也就是说在整个数据集中负样本占了大多数;
在训练卷积神经网络的时候,是需要一个批次一个批次的去给它喂数据, 这里的batch大小是128,通常在每一轮训练过程中,正样本和负样本的数量不能相差太大,但是我们的这个数据集里正样本的数量远远少于负样本,所以我们在每一轮迭代的过程中,都强制采样32个正样本和96个负样本,以确保正负样本的比例不会相差过大。
支持向量机SVM图像分类模型
训练完图像分类网络之后,就可以利用这个网络很好地提取PASCAL VOC数据集上的图片特征。在提取了候选区域的图片特征之后,需要训练一个支持向量机分类模型来对候选区域进行分类。
刚训练特征提取网络的时候使用了一种正负样本的划分方法,也就是把loU大于等于0.5的区域作为正样本,把小于0.5的区域,作为负样本。 但是作者在训练的时候,并没有采用这种方法,而是只把ground Truth标注框作为每个类的正样本,把IoU小于0.3的区域作为负样本,而并不是这里小于0.5的区域作为负样本,并且由于负样本数量通常是远远多于正样本的,在训练支持向量机的时候,作者采用了一种难例挖掘 hard negative mining的方法来挑选负样本。
为什么是0.3?
在附录B中进行了详细的解释。
作者理了一下做实验的时间线,刚开始做实验训练RCNN的时候,并没有在VOC数据集上进行微调,也就是说只使用ImageNet来预训练一个能分类1000类目标的CNN来提取图片特征,并使用提取到的特征来训练支持向量机进行分类。
在这项实验中作者对SVM实验了不同的阈值,发现当阈值低于0.3的时候作为负样本,标注框作为正样本的划分效果最好。
在这之后,才引入了微调,并且在引入微调之后,还是先尝试去使用了和SVM一样的正负样本划分方法,但是支持向量机的这种正负样本划分方法并没有取得很好的效果,才通过实验进一步得出了IoU阈值0.5这种正负样本划分方法对CNN的效果最好。
所以,前因后果: 先确认支持向量机的正负样本划分方法,再确定CNN正负样本划分方法。
作者从理论层面上去解释为什么会出现这种结果: 作者认为出现这一结果的原因是微调的数据太少了。在使用旧的SVM的划分方法时,只有标注框才作为正样本,但是使用新方法后会在标注框周围引入大量的抖动样本,从而把正样本数量扩大了大约30倍。
丰富的数据量可以避免CNN的过拟合,所以这也解答了为什么CNN和SVM要采用不同的正负样本划分方法。
CNN最后全连接层可以完成目标分类为什么要引入SVM?
作者通过实验尝试发现,直接用CNN去分类使得精度从原来的54.2%降低到了50.9%,作者认为效果不好的原因:可能是每个正样本也就是抖动区域它并不是每个目标的精确的位置坐标,这可能会导致一些误差;并且我们在训练CNN的时候,副样本是被随机挑选的,对于CNN的预测出错的样本,可以单独把它们挑出来,作为难样本(hard negatives)可以重新训练一个支持向量机的分类器;
基于这两点,尽管微调的CNN它能够实现多分类,但是我们只用它来提图片特征,专门额外的训练多个SVM分类器对这个图片特征进行分类。
测试效果


三 可视化特征、消融实验和分析误差
3.1 可视化RCNN提取到的特征
对于神经网络第一层提取到的特征一般都是提取了某个小区域的边缘信息或者是色彩信息,但是随后的高层信息不容易可视化了,因此作者提出了一种新的方法来可视化这种高层的图片特征。
对于一张图片可以用selected search这种方法找到大约2000个候选位置,那么在PASCAL VOC的整个数据集上,可以找到大约1,000万个候选区域,每一个候选区域把它缩放到特定的227×227大小之后,可以通过CNN来提取图片特征。

这里的第五层卷积后面有一个池化层没有画出来,也就是说输入227×227×3大小的勾选区域图片之后,会得到一个6×6×256通道的一个特征图,把这256通道的第一个通道的特征图给专门取出来也就是个6×6大小的特征图。

这个6×6的每一个位置都有一个值,先只看左上角的这个值,每一个候选区域都会有第一个通道的左上角的这么一个值,在整个数据集上大约有1,000万个候选区域,那么就会有1,000万个这个值,把这1,000万个值按从大到小的顺序排序之后单独挑出来,只是最大的前几个对应的图片所列出的对应的候选区域的图片会发现这些候选区域的图片全部都表示人的图片。
假如你不选左上角的这个值,而是选择了右下角的这个值,你会发现你挑出来的所有图片也都是人的图片,只不过白框不是在左上角的,而是变成了右下角的一个白框;
假如你选择的不是第一个通道,而是第二个通道,你会发现第二个通道对应的候选区域图片是黑色的点状区域;

对于高层特征来说,每一个不同的通道,它学习到的就是一个高层的特征:比如说人,或者这种黑色的点状区域;
对于同一个通道的不同位置,它表示的类别是相同的,只是这个白色的框的位置偏了一点,比如左上角的这个值对应的就是左上角这个框,如果是右下角这个值,这白框就往右下角偏了一点;
下图是作者举例的不同通道结果:

3.2 消融实验
在之前的特征提取,使用的是第二个全连接层输出作为图片的特征,这里想用第五个卷积层、第一个全连接层、第二个全连接层作为图片特征输出,分别命名:
 此外,还探讨了使用微调对三种特征提取的区别,结果如下:
此外,还探讨了使用微调对三种特征提取的区别,结果如下:

结果:
- 不使用微调,FC6提取到的特征用于目标检测时的精度是最高的;
- 微调提升了检测精度;
- 使用微调时FC7层的特征是最好;
- 微调更多影响的是全连接层的特征提取能力;
3.3 3.4 对比了不同CNN结构对特征提取的影响
之前用的都是AlexNet网络结构提取特征; VGG是比AlexNet层数更多的模型;
这里把AlexNet替换成VGG; (AlexNet也叫T Net;VGG 也叫O Net)
测试结果:
结果1:

两行表示挑选了两类目标来举例子,第一行表示动物,第二行表示家具;
竖着三列分别表示没有微调的RCN、微调后的RCN、以及改进后的R-CNN BB算法的分析结果;
横轴表示识别错的目标个数;
误检框分为4类,每一种误检用一个颜色来表示出来: Loc: 表示检测的类别正确,但是定位不准确; Sim: 表示similar,表示把目标错误识别成相似的类别; Oth: 表示识别出了完全不相关的类别; BG: 表示background,也就是识别出了背景;
观察纵轴可以发现大部分的误识别都是蓝色的部分,也就是预测框的定位不准确,所以RCN的候选框生成算法所产生的位置其实是不准确的,会带来比较大的误差导致最终的预测结果位置不太准确。
结果2: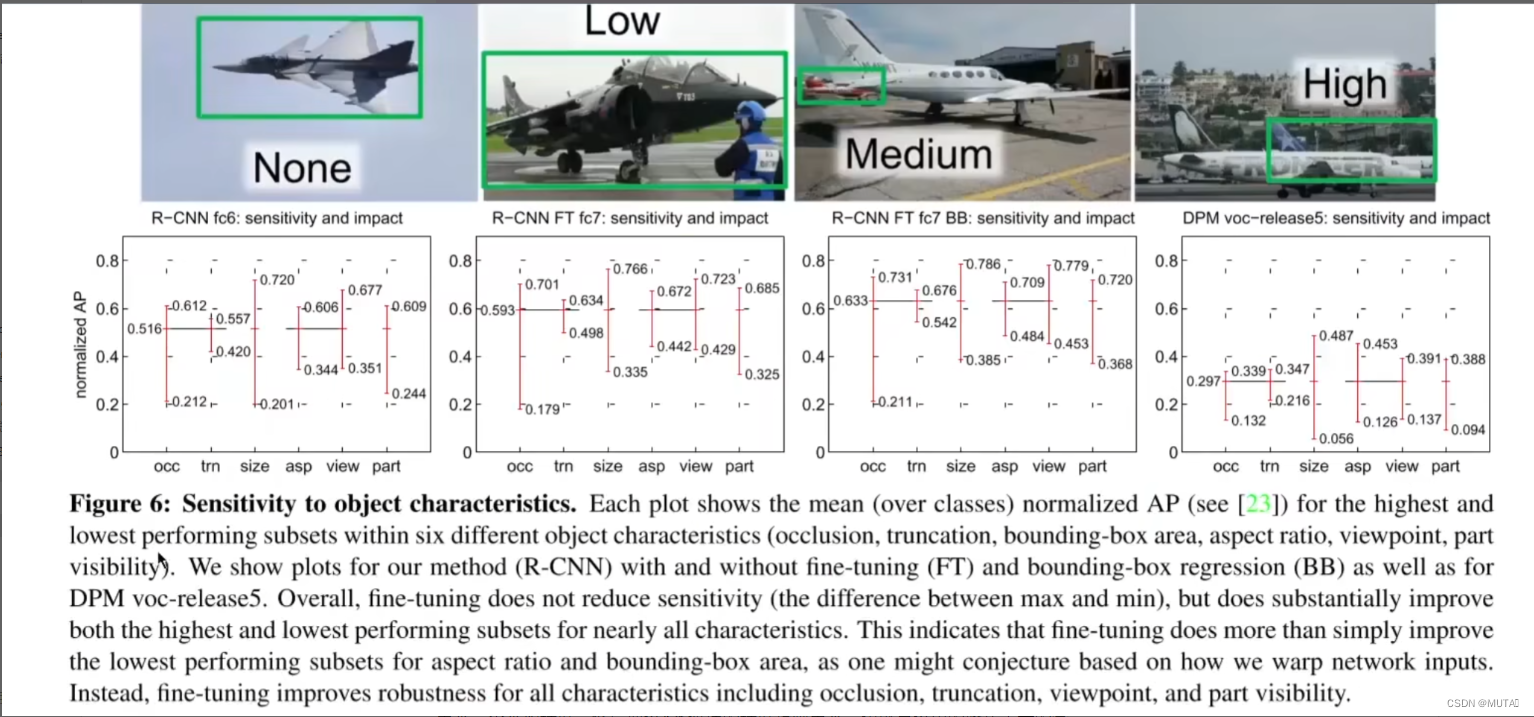
上图表示没有微调的RCNN、微调后的RCNN、R-CNN BB、DPM这4个算法对数据集中不同因素的敏感度sensitivity,以及这些因素在多大程度上会影响算法效果?
每幅图中的横坐标分别表示不同的因素: occ: 表示目标的遮挡程度; size: 表示目标的尺寸大小;
以遮挡因素为例,可以把数据集中的所有图片按遮挡程度进一步细分为4类,分别是不遮挡,低遮挡,中等程度遮挡和高遮挡; 数据集里面的所有目标都可以按这4类求出来一个平均精度,然后把这4类遮挡的精度给画出来,也就是这里的竖线表示的含义; 比如严重遮挡的目标它的识别效果可能会比较差,因此求出来的精度可能只有0.212,不遮挡的目标识别效果通常比较好,所以它求出来的精度可能就是0.612,中间的这条横线就表示在整个数据集上的平均精度。
通过观察这些图片,我们可以发现: 微调过后几乎能提高所有类型数据的最低精度和最高精度; 并且使用RCN的方法,通常要比epm这种传统方法的精度高很多;
敏感度: 红线跨度就表示这个算法对尺寸这个因素的敏感程度,可以看到微调过后的这个跨度明显比之前小,说明微调后的算法对目标尺寸更不敏感;
影响度: 平均精度到最高点的范围,就表示这个因素对这个算法的影响; 比如最好情况是0.766,由于这个因素的影响存在,会把最好情况给拉低到0.593,所以这个范围表示的就是某个因素对算法的影响。
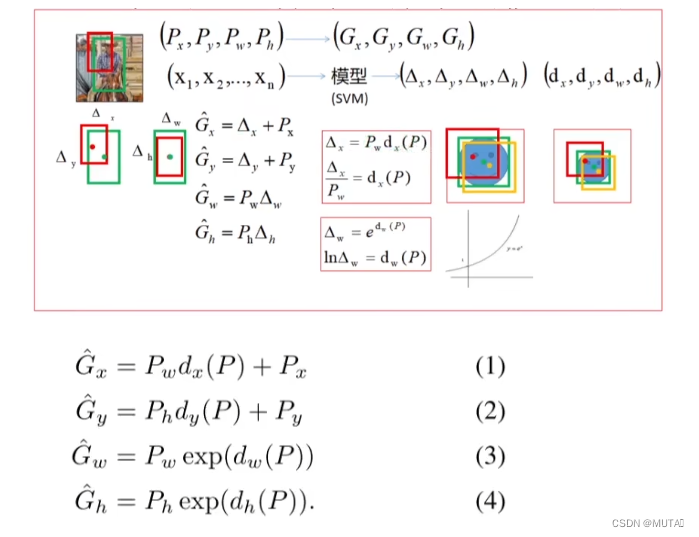
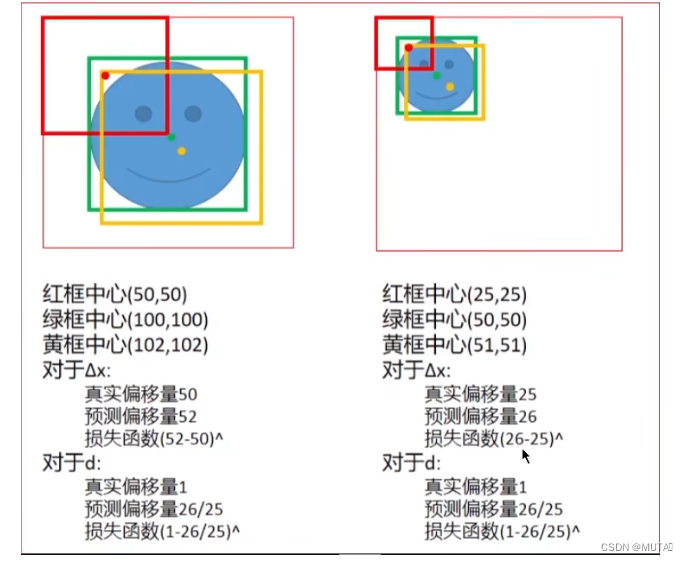
3.5 边界框回归
在分析图5的时候有提到过大部分识别错误的情况,都是因为目标的定位不够准确,因此在3.5小节作者专门提出了一个根据R-CNN优化后的R-CNN BB算法;