CBAM,全称Convolutional Block Attention Module,是一种注意力机制模块,用于增强卷积神经网络(CNN)的特征表达能力。该模块由通道注意力模块和空间注意力模块两部分组成,能够分别关注输入特征图的通道信息和空间信息,进而提升模型对于重要特征的关注度。
在通道注意力模块中,CBAM通过全局平均池化和最大池化操作捕获通道间的依赖关系,生成两个通道描述子。这两个描述子随后通过共享的全连接层和ReLU激活函数进行变换,再经过Sigmoid函数得到通道注意力权重。这些权重与原始特征图相乘,实现通道维度的特征重标定。
空间注意力模块则关注特征图的空间位置信息。它首先对特征图进行通道维度的平均池化和最大池化操作,生成两个空间描述子。这两个描述子经过一个卷积层进行融合,再通过Sigmoid函数得到空间注意力权重。这些权重与原始特征图相乘,实现对空间位置的特征重标定。
CBAM模块可以轻松地嵌入到现有的卷积神经网络架构中,如ResNet、VGG等,通过增强模型的注意力能力,提升其在图像分类、目标检测等任务上的性能。同时,CBAM还具有良好的可解释性,有助于理解模型在决策过程中的关注点,为深度学习模型的可视化和解释提供了有力的工具
一、通道注意力
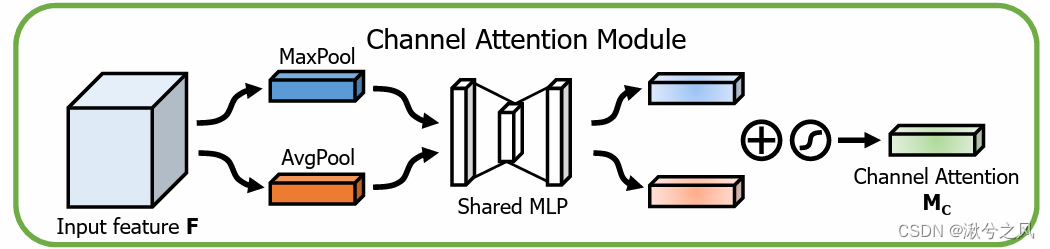
相同视角下,取不同的池化值,然后就是通道的压缩及扩展,最后通过sigmoid得到最终权重。其实这里模式很像SE,但也不能照搬SE,所以用了个多分支。
class ChannelAttentionModule(nn.Module):
def __init__(self, channel, reduction=16):
super(ChannelAttentionModule, self).__init__()
mid_channel = channel // reduction
# 使用自适应池化缩减map的大小,保持通道不变
self.avg_pool = nn.AdaptiveAvgPool2d(1) #(1) 表示输出的高度和宽度都被设置为 1。
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.shared_MLP = nn.Sequential(
nn.Linear(in_features=channel, out_features=mid_channel),
nn.ReLU(),
nn.Linear(in_features=mid_channel, out_features=channel)
)
self.sigmoid = nn.Sigmoid()
# self.act=SiLU()
def forward(self, x):
avgout = self.shared_MLP(self.avg_pool(x).view(x.size(0), -1)).unsqueeze(2).unsqueeze(3)
maxout = self.shared_MLP(self.max_pool(x).view(x.size(0), -1)).unsqueeze(2).unsqueeze(3)
return self.sigmoid(avgout + maxout)二、空间注意力
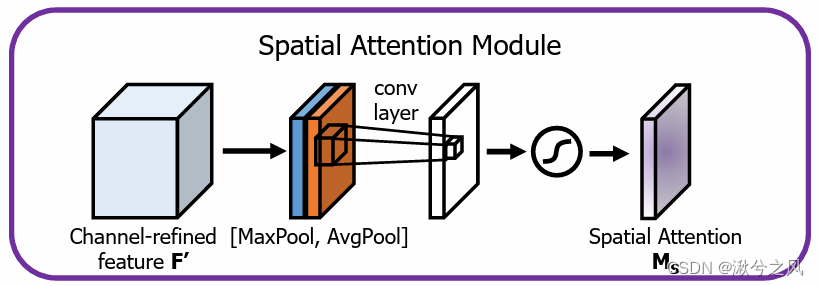
刚才那个是通道上的压缩及放缩,那这里就是空间特征图上,依然采用两种池化方式。
# 空间注意力模块
class SpatialAttentionModule(nn.Module):
def __init__(self):
super(SpatialAttentionModule, self).__init__()
self.conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3)
# self.act=SiLU()
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# map尺寸不变,缩减通道
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avgout, maxout], dim=1)
out = self.sigmoid(self.conv2d(out))
return out该论文采用的创新,从两个不同的视角建立注意力,这个出发点还是不错的,但实际比如在小数据集上的效果怎么样,那么就需要你自己斟酌了。
三、CBAM_ResNet(Pytorch)
# ------------------------#
# CBAM模块的Pytorch实现
# ------------------------#
# 通道注意力模块
import torch.nn as nn
import torch
class ChannelAttentionModule(nn.Module):
def __init__(self, channel, reduction=16):
super(ChannelAttentionModule, self).__init__()
mid_channel = channel // reduction
# 使用自适应池化缩减map的大小,保持通道不变
self.avg_pool = nn.AdaptiveAvgPool2d(1) #(1) 表示输出的高度和宽度都被设置为 1。
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.shared_MLP = nn.Sequential(
nn.Linear(in_features=channel, out_features=mid_channel),
nn.ReLU(),
nn.Linear(in_features=mid_channel, out_features=channel)
)
self.sigmoid = nn.Sigmoid()
# self.act=SiLU()
def forward(self, x):
avgout = self.shared_MLP(self.avg_pool(x).view(x.size(0), -1)).unsqueeze(2).unsqueeze(3)
maxout = self.shared_MLP(self.max_pool(x).view(x.size(0), -1)).unsqueeze(2).unsqueeze(3)
return self.sigmoid(avgout + maxout)
# 空间注意力模块
class SpatialAttentionModule(nn.Module):
def __init__(self):
super(SpatialAttentionModule, self).__init__()
self.conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3)
# self.act=SiLU()
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# map尺寸不变,缩减通道
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avgout, maxout], dim=1)
out = self.sigmoid(self.conv2d(out))
return out
# CBAM模块
class CBAM(nn.Module):
def __init__(self, channel):
super(CBAM, self).__init__()
self.channel_attention = ChannelAttentionModule(channel)
self.spatial_attention = SpatialAttentionModule()
def forward(self, x):
out = self.channel_attention(x) * x
out = self.spatial_attention(out) * out
return out
from CBAM import CBAM
import torch
import torch.nn as nn
from torch.hub import load_state_dict_from_url
from torchvision.models import ResNet
def conv3x3(in_planes, out_planes, stride=1):
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, padding=1, bias=False)
class CBAMBasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None,
*, reduction=16):
# 参数列表里的 * 星号,标志着位置参数的就此终结,之后的那些参数,都只能以关键字形式来指定。
super(CBAMBasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes, 1)
self.bn2 = nn.BatchNorm2d(planes)
self.cbam = CBAM(planes, reduction)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.cbam(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class CBAMBottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None,
*, reduction=16):
# 参数列表里的 * 星号,标志着位置参数的就此终结,之后的那些参数,都只能以关键字形式来指定。
super(CBAMBottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.cbam = CBAM(planes * 4, reduction)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.cbam(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
def cbam_resnet18(num_classes=1_000):
model = ResNet(CBAMBasicBlock, [2, 2, 2, 2], num_classes=num_classes)
model.avgpool = nn.AdaptiveAvgPool2d(1)
return model
def cbam_resnet34(num_classes=1_000):
model = ResNet(CBAMBasicBlock, [3, 4, 6, 3], num_classes=num_classes)
model.avgpool = nn.AdaptiveAvgPool2d(1)
return model
def cbam_resnet50(num_classes=1_000, pretrained=False):
model = ResNet(CBAMBottleneck, [3, 4, 6, 3], num_classes=num_classes)
model.avgpool = nn.AdaptiveAvgPool2d(1)
if pretrained:
model.load_state_dict(load_state_dict_from_url(
"https://github.com/moskomule/senet.pytorch/releases/download/archive/seresnet50-60a8950a85b2b.pkl"))
return model
def cbam_resnet101(num_classes=1_000):
model = ResNet(CBAMBottleneck, [3, 4, 23, 3], num_classes=num_classes)
model.avgpool = nn.AdaptiveAvgPool2d(1)
return model
def cbam_resnet152(num_classes=1_000):
model = ResNet(CBAMBottleneck, [3, 8, 36, 3], num_classes=num_classes)
model.avgpool = nn.AdaptiveAvgPool2d(1)
return model
if __name__ == "__main__":
inputs = torch.randn(2, 3, 224, 224)
model = cbam_resnet50(pretrained=False)
# outputs = model(inputs)
# print(outputs.size())
print(model)