macOS
Windows 预览版
Linux
curl -fsSL https://ollama.com/install.sh | sh
Docker
官方的 Ollama Docker 镜像 ollama/ollama 已经在 Docker Hub 上发布。
库
快速开始
启动服务
刚安装完成时,默认时开启的,如果停止后请执行,下面命令开启:
service ollama start
停止服务
在Linux环境下,如果"ollama"是一个后台运行的服务,可以通过以下类似命令来停止:
service ollama stop
运行模型
要运行并与 Llama 2 进行交互:
ollama run llama2
模型库
Ollama 支持一系列可在 ollama.com/library 查找的语言模型列表。
以下是一些可下载的示例模型:
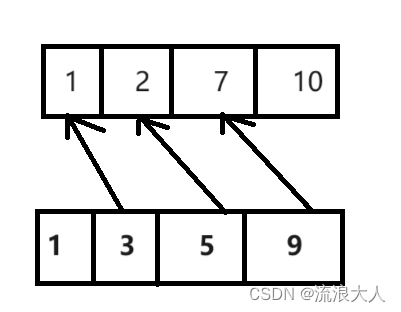
| 模型名称 | 参数数量 | 大小 | 下载命令 |
|---|---|---|---|
| Llama 2 | 70亿 | 3.8GB | ollama run llama2 |
| Mistral | 70亿 | 4.1GB | ollama run mistral |
| Dolphin Phi | 27亿 | 1.6GB | ollama run dolphin-phi |
| Phi-2 | 27亿 | 1.7GB | ollama run phi |
| Neural Chat | 70亿 | 4.1GB | ollama run neural-chat |
| Starling | 70亿 | 4.1GB | ollama run starling-lm |
| Code Llama | 70亿 | 3.8GB | ollama run codellama |
| Llama 2 无限制版 | 70亿 | 3.8GB | ollama run llama2-uncensored |
| Llama 2 130亿参数版 | 130亿 | 7.3GB | ollama run llama2:13b |
| Llama 2 700亿参数版 | 700亿 | 39GB | ollama run llama2:70b |
| Orca Mini | 30亿 | 1.9GB | ollama run orca-mini |
| Vicuna | 70亿 | 3.8GB | ollama run vicuna |
| LLaVA | 70亿 | 4.5GB | ollama run llava |
| Gemma | 20亿 | 1.4GB | ollama run gemma:2b |
| Gemma | 70亿 | 4.8GB | ollama run gemma:7b |
注意:运行 70亿参数模型至少需要 8 GB 内存,运行 130亿参数模型需要 16 GB 内存,而运行 330亿参数模型则需要 32 GB 内存。
自定义模型
从GGUF导入模型
Ollama支持从GGUF导入模型至Modelfile中:
创建一个名为
Modelfile的文件,其中包含一个FROM指令,指定要导入的本地模型文件路径。FROM ./vicuna-33b.Q4_0.gguf在Ollama中创建模型
ollama create example -f Modelfile运行模型
ollama run example
从PyTorch或Safetensors导入
有关导入模型的更多信息,请参阅导入指南。
自定义提示
可以从Ollama库中自定义带有提示的模型。例如,要自定义llama2模型:
ollama pull llama2
创建一个Modelfile:
FROM llama2
# 设置温度为1 [数值越高创造力越强,数值越低连贯性越好]
PARAMETER temperature 1
# 设置系统消息
SYSTEM """
您是来自《超级马里奥兄弟》的马里奥。请以马里奥助手的身份作答。
"""
接下来,创建并运行模型:
ollama create mario -f ./Modelfile
ollama run mario
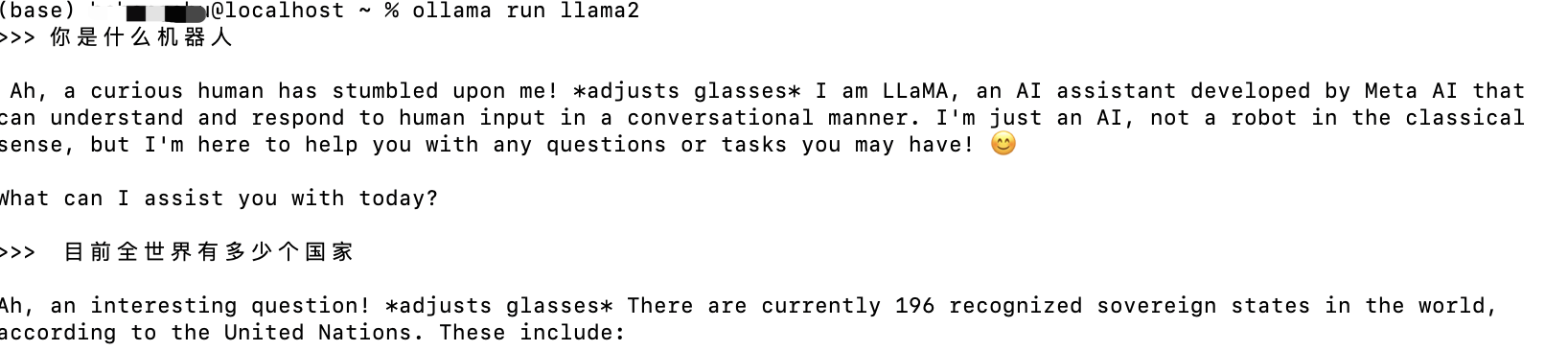
>>> hi
你好!我是你的朋友马里奥。
更多示例请查看示例目录。有关如何使用Modelfile的更多详细信息,请参阅Modelfile文档。
CLI参考文献
翻译摘要
Ollama工具支持导入GGUF格式的模型,流程如下:
- 在
Modelfile文件中通过FROM语句指定本地模型文件路径进行导入。 - 利用Ollama创建导入模型实例。
- 运行创建好的模型实例。
对于从PyTorch或Safetensors导入模型,请参照相关导入指南。
Ollama还允许用户自定义模型的提示内容,例如针对llama2模型的定制:
- 先拉取
llama2模型。 - 创建一个
Modelfile文件,设置参数如温度,并提供系统消息(即提示文本)。 - 根据
Modelfile文件创建并运行自定义模型实例。
更多例子可在示例目录中查看,有关Modelfile的详细使用说明请参阅Modelfile文档部分。
创建模型
使用ollama create命令基于Modelfile创建模型。
ollama create 我的模型 -f ./Modelfile
下载模型
ollama pull llama2
此命令也可用于更新本地模型。只会拉取差异部分。
删除模型
ollama rm llama2
复制模型
ollama cp llama2 我的-llama2
多行输入
对于多行输入,可以使用 """ 包裹文本:
>>> """
... 你好,
... 世界!
... """
我是一个基础程序,会在控制台上打印著名的"你好,世界!"消息。
多模态模型
>>> 这张图片里面是什么?/Users/jmorgan/Desktop/smile.png
图片中有一个黄色笑脸,很可能是图片的焦点所在。
将提示作为参数传递
$ ollama run llama2 "总结这个文件:$(cat README.md)"
Ollama是一款轻量级、可扩展的框架,用于在本地机器上构建和运行语言模型。它提供了一个简单的API,用于创建、运行和管理模型,同时也提供了一系列预建模型库,这些模型可在多种应用中轻松使用。
列出计算机上的模型
ollama list
启动Ollama服务
当你不想运行桌面应用程序而直接启动Ollama时,使用ollama serve命令。
构建过程
安装cmake和go开发工具:
brew install cmake go
然后生成依赖项:
go generate ./...
接着编译二进制文件:
go build .
更详细的构建指南可以在开发者指南中找到。
运行本地构建
接下来启动服务器:
./ollama serve
最后,在另一个终端窗口中运行模型:
./ollama run llama2
REST API
Ollama提供了一个用于运行和管理模型的REST API。
默认启动的11434端口,但是只能本机访问。如果需要设置外网访问,修改修改服务配置
修改文件 /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="OLLAMA_HOST=0.0.0.0"
Environment="PATH=/home/dtjk/bin:/home/dtjk/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin:/home/dtjk/.dotnet/tools:/home/dtjk/.dotnet/tools"
[Install]
WantedBy=default.target
- 文件内添加 Environment=“OLLAMA_HOST=0.0.0.0” 保存
更新配置命令
sudo systemctl daemon-reload
sudo service ollama restart
生成响应
curl http://localhost:11434/api/generate -d '{
"model": "llama2",
"prompt": "为什么天空是蓝色的?"
}'
与模型聊天
curl http://localhost:11434/api/chat -d '{
"model": "mistral",
"messages": [
{ "role": "user", "content": "为什么天空是蓝色的?" }
]
}'
有关所有端点的详细信息,请查阅API文档。
社区集成
网页与桌面应用集成
- Bionic GPT
- Enchanted (macOS native)
- HTML UI
- Chatbot UI
- Typescript UI
- Minimalistic React UI for Ollama Models
- Open WebUI
- Ollamac
- big-AGI
- Cheshire Cat assistant framework
- Amica
- chatd
- Ollama-SwiftUI
- MindMac
- NextJS Web Interface for Ollama
- Msty
- Chatbox
- WinForm Ollama Copilot
- NextChat with Get Started Doc
- Odin Runes
- LLM-X: Progressive Web App
终端
- oterm
- Ellama Emacs client
- Emacs client
- gen.nvim
- ollama.nvim
- ollama-chat.nvim
- ogpt.nvim
- gptel Emacs client
- Oatmeal
- cmdh
- tenere
- llm-ollama for Datasette’s LLM CLI.
- ShellOracle
数据库
包管理
库
- LangChain and LangChain.js with example
- LangChainGo with example
- LangChain4j with example
- LlamaIndex
- LangChain4j
- LiteLLM
- OllamaSharp for .NET
- Ollama for Ruby
- Ollama-rs for Rust
- Ollama4j for Java
- ModelFusion Typescript Library
- OllamaKit for Swift
- Ollama for Dart
- Ollama for Laravel
- LangChainDart
- Semantic Kernel - Python
- Haystack
- Elixir LangChain
- Ollama for R - rollama
- Ollama-ex for Elixir
- Ollama Connector for SAP ABAP
移动
扩展和插件
- Raycast extension
- Discollama (Discord bot inside the Ollama discord channel)
- Continue
- Obsidian Ollama plugin
- Logseq Ollama plugin
- NotesOllama (Apple Notes Ollama plugin)
- Dagger Chatbot
- Discord AI Bot
- Ollama Telegram Bot
- Hass Ollama Conversation
- Rivet plugin
- Llama Coder (Copilot alternative using Ollama)
- Obsidian BMO Chatbot plugin
- Copilot for Obsidian plugin
- Obsidian Local GPT plugin
- Open Interpreter
- twinny (Copilot and Copilot chat alternative using Ollama)
- Wingman-AI (Copilot code and chat alternative using Ollama and HuggingFace)
- Page Assist (Chrome Extension)