文章目录
【2024第一期CANN训练营】Ascend C算子开发基础篇
Ascend C是面向算子开发场景的编程语言,它原生支持C和C++标准规范,并提供了多层接口抽象、自动并行计算等关键技术,以提高算子开发效率。
Ascend C的特点
- C/C++原语编程
- 编程模型屏蔽硬件差异
- 类库API封装,兼顾易用与高效
- 孪生调试,可在CPU侧模拟NPU侧的行为
开发基本流程
环境准备
使用Ascend C完成Add算子核函数开发;
使用ICPU_RUN_KF CPU调测宏完成算子核函数CPU侧运行验证;
使用<<<>>>内核调用符完成算子核函数NPU侧运行验证。
下面以官方样例中的Add算子为例进行操作,开发之前请先获取样例代码目录quick-start,了解Add算子的各个目录和文件夹的具体作用,具体只需要依次开发下面的三个文件:add_custom.cpp,main.cpp,gen_data.py
Add
|-- input // 存放脚本生成的输入数据目录
|-- output // 存放算子运行输出数据和真值数据的目录
|-- CMakeLists.txt // 编译工程文件
|-- add_custom.cpp // 1.算子kernel实现
|-- scripts
| ├── gen_data.py // 3.输入数据和真值数据生成脚本文件
| ├── verify_result.py // 验证输出数据和真值数据是否一致的验证脚本
|-- cmake // 编译工程文件
|-- data_utils.h // 数据读入写出函数
|-- main.cpp // 2.主函数,调用算子的应用程序,含CPU域及NPU域调用
|-- run.sh // 编译运行算子的脚本
1. 环境准备
1.1 安装CANN开发套件包
- 打开CANN资源下载中心,根据机器cpu架构(uname -a来进行查看)下载对应最新的 Ascend-cann-toolkit_8.0.RC1.alpha002
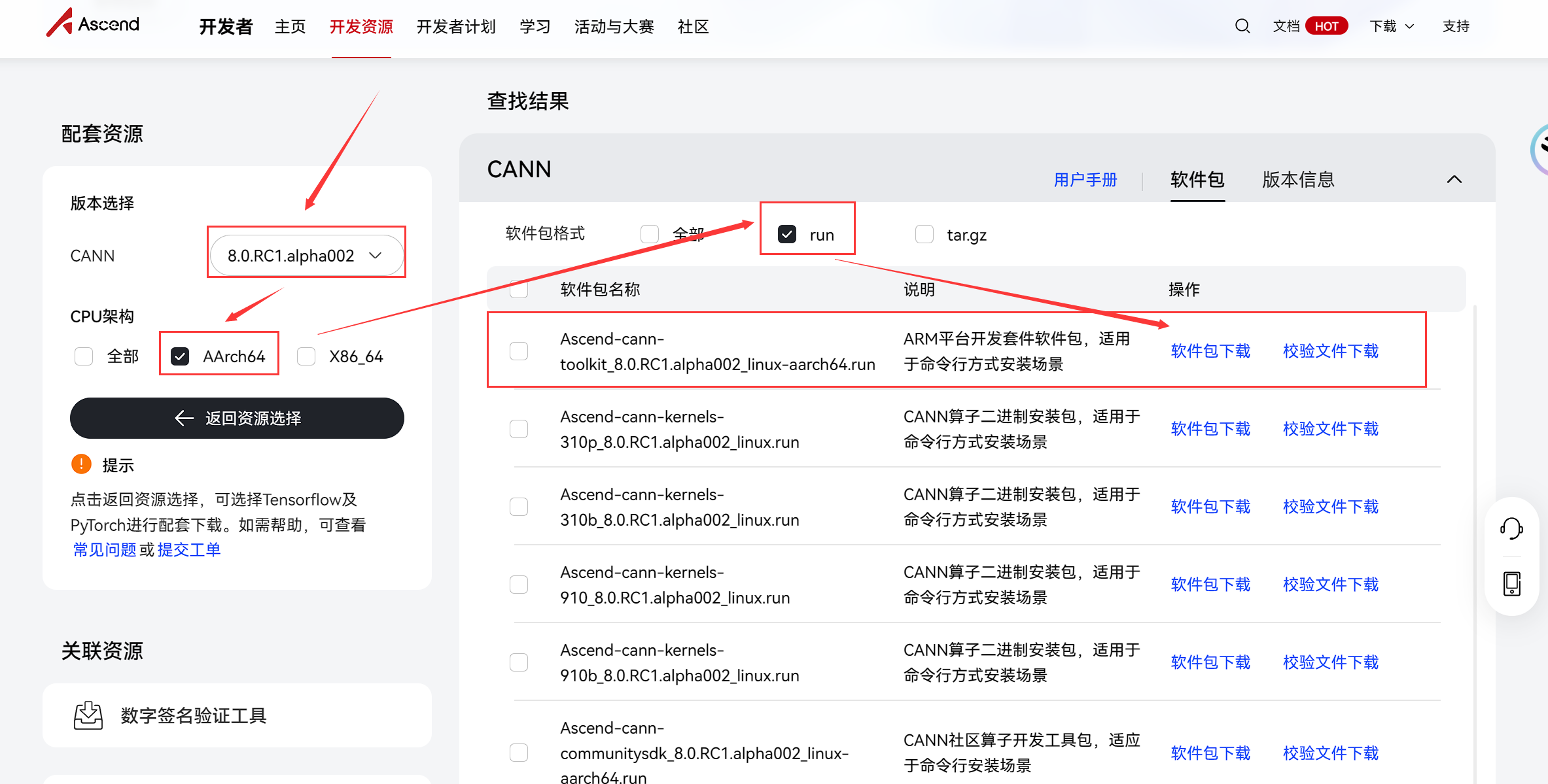
# 我的机器是AArch64,因此下载安装 Ascend-cann-toolkit_8.0.RC1.alpha002_linux-aarch64.run
wget -O Ascend-cann-toolkit_8.0.RC1.alpha002_linux-aarch64.run https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Milan-ASL/Milan-ASL%20V100R001C17SPC702/Ascend-cann-toolkit_8.0.RC1.alpha002_linux-aarch64.run?response-content-type=application/octet-stream
- 赋予可执行权限:
chmod +x Ascend-cann-toolkit_8.0.RC1.alpha002_linux-x86_64.run
- 校验软件包的一致性和完整性:
./Ascend-cann-toolkit_8.0.RC1.alpha002_linux-x86_64.run --check
- 安装CANN开发套件包,并在提示时接受华为企业业务最终用户许可协议(EULA):
# root用户会默认安装在/usr/local/下,非root用户会安装到$HOME下,下面以root用户为例进行操作
./Ascend-cann-toolkit_8.0.RC1.alpha002_linux-x86_64.run --install
- 配置CANN环境变量:
source /usr/local/Ascend/ascend-toolkit/set_env.sh
2. 算子分析
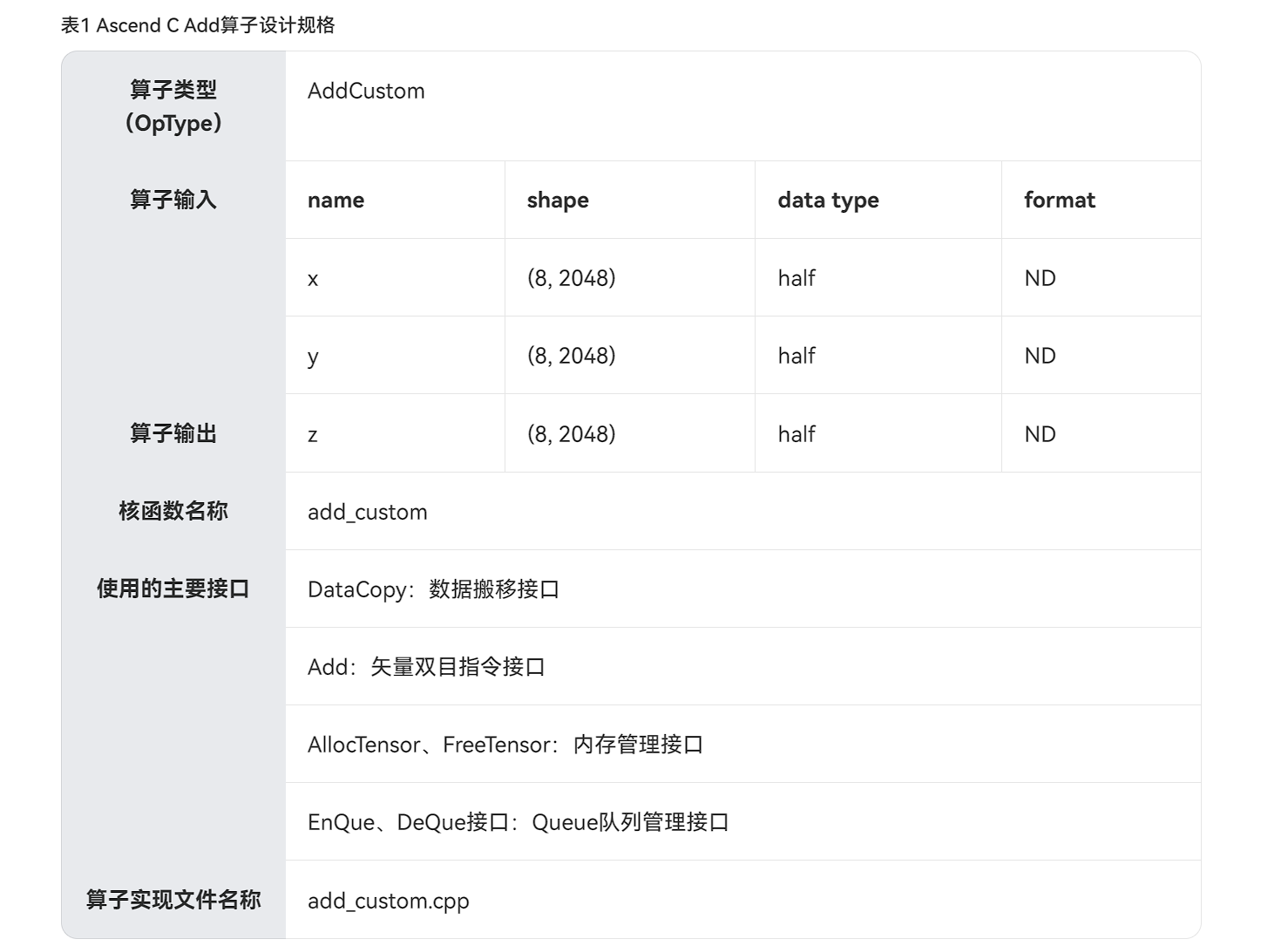
在开发Ascend C算子之前,需要对算子进行分析,明确算子的数学表达式、输入输出以及计算逻辑的实现。以Add算子为例:
- Add算子的数学表达式为:
z = x + y。 - 输入输出数据类型为
half(float16),支持的shape为(8, 2048),format为ND。 - 核函数名称自定义为
add_custom,参数为x,y,z,分别对应输入和输出的内存地址。
3. 核函数开发(add_custom.cpp)
开发之前请先获取样例代码目录quick-start,了解Add算子的各个目录和文件夹的具体作用,具体只需要依次开发下面的三个文件:add_custom.cpp,main.cpp,gen_data.py
Add
|-- input // 存放脚本生成的输入数据目录
|-- output // 存放算子运行输出数据和真值数据的目录
|-- CMakeLists.txt // 编译工程文件
|-- add_custom.cpp // 1.算子kernel实现
|-- scripts
| ├── gen_data.py // 3.输入数据和真值数据生成脚本文件
| ├── verify_result.py // 验证输出数据和真值数据是否一致的验证脚本
|-- cmake // 编译工程文件
|-- data_utils.h // 数据读入写出函数
|-- main.cpp // 2.主函数,调用算子的应用程序,含CPU域及NPU域调用
|-- run.sh // 编译运行算子的脚本
3.1 核函数定义(add_custom,add_custom_do)
**核函数(Kernel Function)是Ascend C算子设备侧实现的入口。**在核函数中,需要为在一个核上执行的代码规定要进行的数据访问和计算操作,当核函数被调用时,多个核都执行相同的核函数代码,具有相同的参数,并行执行。
Ascend C允许用户使用核函数这种C/C++函数的语法扩展来管理设备端的运行代码,用户在核函数中进行算子类对象的创建和其成员函数的调用,由此实现该算子的所有功能。核函数是主机端和设备端连接的桥梁。
// 核函数实现
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z) {
KernelAdd op;
op.Init(x, y, z); // 初始化函数,获取处理的输入输出地址,完成内存初始化
op.Process(); // 核心处理函数,完成数据搬运与计算等核心逻辑
}
- 使用
__global__限定符标识核函数,表示它可以在设备上执行。 - 使用
__aicore__限定符表明核函数在AI Core上执行。 - 参数使用
GM_ADDR宏进行修饰,表示指针指向Global Memory的内存地址。
核函数的调用需要使用特殊的内核调用符,这与普通的函数调用不同。核函数调用的语法如下:
// 核函数调用
void add_custom_do(uint32_t blockDim, void* l2ctrl, void* stream, uint8_t* x, uint8_t* y, uint8_t* z) {
add_custom<<<blockDim, l2ctrl, stream>>>(x, y, z);
}
blockDim指定核函数将在多少个核上执行。l2ctrl是一个保留参数,通常设置为nullptr。stream是aclrtStream类型,用于维护异步操作的执行顺序。
3.2 算子类实现(KernelAdd)

class KernelAdd {
public:
__aicore__ inline KernelAdd(){}
// 初始化函数,完成内存初始化相关操作
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z){}
// 核心处理函数,实现算子逻辑,调用私有成员函数CopyIn、Compute、CopyOut完成矢量算子的三级流水操作
__aicore__ inline void Process(){}
private:
// 搬入函数,完成CopyIn阶段的处理,被核心Process函数调用
__aicore__ inline void CopyIn(int32_t progress){}
// 计算函数,完成Compute阶段的处理,被核心Process函数调用
__aicore__ inline void Compute(int32_t progress){}
// 搬出函数,完成CopyOut阶段的处理,被核心Process函数调用
__aicore__ inline void CopyOut(int32_t progress){}
private:
TPipe pipe; //Pipe内存管理对象
TQue<QuePosition::VECIN, BUFFER_NUM> inQueueX, inQueueY; //输入数据Queue队列管理对象,QuePosition为VECIN
TQue<QuePosition::VECOUT, BUFFER_NUM> outQueueZ; //输出数据Queue队列管理对象,QuePosition为VECOUT
GlobalTensor<half> xGm, yGm, zGm; //管理输入输出Global Memory内存地址的对象,其中xGm, yGm为输入,zGm为输出
};
3.3 初始化函数(Init)
constexpr int32_t TOTAL_LENGTH = 8 * 2048; // 数据的总长度
constexpr int32_t USE_CORE_NUM = 8; // 使用的核心数量
constexpr int32_t BLOCK_LENGTH = TOTAL_LENGTH / USE_CORE_NUM; // 每个核心计算的长度
constexpr int32_t TILE_NUM = 8; // 每个核心将数据分割成8块
constexpr int32_t BUFFER_NUM = 2; // 每个队列的张量数量
constexpr int32_t TILE_LENGTH = BLOCK_LENGTH / TILE_NUM / BUFFER_NUM; // 由于双缓冲,将其分为两部分
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{
// 获取当前核心的起始索引,核心并行
xGm.SetGlobalBuffer((__gm__ half*)x + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
yGm.SetGlobalBuffer((__gm__ half*)y + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
zGm.SetGlobalBuffer((__gm__ half*)z + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
// 管道分配内存给队列,单位是字节
pipe.InitBuffer(inQueueX, BUFFER_NUM, TILE_LENGTH * sizeof(half));
pipe.InitBuffer(inQueueY, BUFFER_NUM, TILE_LENGTH * sizeof(half));
pipe.InitBuffer(outQueueZ, BUFFER_NUM, TILE_LENGTH * sizeof(half));
}
3.4 Process函数(CopyIn,Compute,CopyOut)
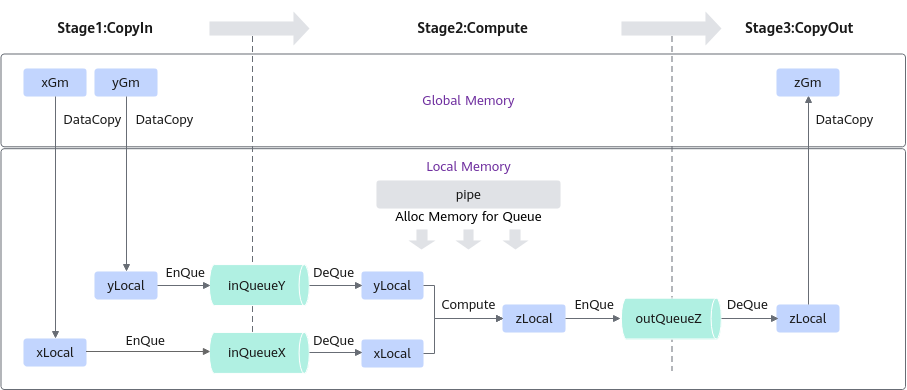
根据矢量编程范式,Process函数将核函数的执行分为三个基本任务:CopyIn、Compute和CopyOut。以下是这三个函数的调用方式。
__aicore__ inline void Process()
{
// 由于使用了双缓冲,循环计数需要翻倍
constexpr int32_t loopCount = TILE_NUM * BUFFER_NUM;
// 分块策略,流水线并行
for (int32_t i = 0; i < loopCount; i++) {
CopyIn(i);
Compute(i);
CopyOut(i);
}
}
根据上述算法分析,整个计算过程被拆分为三个阶段,用户需要分别为每个阶段编写代码,具体流程如下:
第一阶段:CopyIn函数的实现。
__aicore__ inline void CopyIn(int32_t progress) { // 从队列内存中分配张量 LocalTensor<half> xLocal = inQueueX.AllocTensor<half>(); LocalTensor<half> yLocal = inQueueY.AllocTensor<half>(); // 将第progress个分块从全局张量复制到局部张量 DataCopy(xLocal, xGm[progress * TILE_LENGTH], TILE_LENGTH); DataCopy(yLocal, yGm[progress * TILE_LENGTH], TILE_LENGTH); // 将输入张量入队到VECIN队列 inQueueX.EnQue(xLocal); inQueueY.EnQue(yLocal); }第二阶段:Compute函数的实现。
- 使用DeQue接口从VECIN队列中取出LocalTensor。
- 使用Ascend C接口Add完成矢量计算。
- 使用EnQue接口将计算结果的LocalTensor放入VECOUT类型的队列中。
- 使用FreeTensor接口释放不再使用的LocalTensor。
__aicore__ inline void Compute(int32_t progress) { // 从VECIN队列中出队输入张量 LocalTensor<half> xLocal = inQueueX.DeQue<half>(); LocalTensor<half> yLocal = inQueueY.DeQue<half>(); LocalTensor<half> zLocal = outQueueZ.AllocTensor<half>(); // 调用Add指令进行计算 Add(zLocal, xLocal, yLocal, TILE_LENGTH); // 将输出张量入队到VECOUT队列 outQueueZ.EnQue<half>(zLocal); // 释放输入张量以便重用 inQueueX.FreeTensor(xLocal); inQueueY.FreeTensor(yLocal); }第三阶段:CopyOut函数的实现。
- 使用DeQue接口从VECOUT队列中取出LocalTensor。
- 使用DataCopy接口将LocalTensor复制到GlobalTensor上。
- 使用FreeTensor接口回收不再使用的LocalTensor。
__aicore__ inline void CopyOut(int32_t progress) { // 从VECOUT队列中出队输出张量 LocalTensor<half> zLocal = outQueueZ.DeQue<half>(); // 将第progress个分块从局部张量复制到全局张量 DataCopy(zGm[progress * TILE_LENGTH], zLocal, TILE_LENGTH); // 释放输出张量以便重用 outQueueZ.FreeTensor(zLocal); }
add_custom.app完整代码如下:
```c
/*
* 版权所有 (c) 华为技术有限公司 2022-2023。保留所有权利。
*
* 函数:z = x + y
* 这个示例是一个非常基础的示例,它在Ascend平台上实现了矢量加法。
* 在这个示例中:
* x / y / z的长度是8*2048。
* 示例中使用的矢量核心数量是8。
* 每个核心计算的长度是2048。
* 每个核心的分块数量是8,这意味着我们在一次循环中添加2048/8=256个元素。
*
* 这只是一个示范性的分块策略,实际上我们可以在一次循环中计算最多128*255个元素,对于b16类型。
*/
#include "kernel_operator.h"
using namespace AscendC;
constexpr int32_t TOTAL_LENGTH = 8 * 2048; // 数据的总长度
constexpr int32_t USE_CORE_NUM = 8; // 使用的核心数量
constexpr int32_t BLOCK_LENGTH = TOTAL_LENGTH / USE_CORE_NUM; // 每个核心计算的长度
constexpr int32_t TILE_NUM = 8; // 每个核心将数据分成8块
constexpr int32_t BUFFER_NUM = 2; // 每个队列的张量数量
constexpr int32_t TILE_LENGTH = BLOCK_LENGTH / TILE_NUM / BUFFER_NUM; // 由于双缓冲,分为两部分
class KernelAdd {
public:
__aicore__ inline KernelAdd() {}
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{
// 获取当前核心的起始索引,核心并行
xGm.SetGlobalBuffer((__gm__ half*)x + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
yGm.SetGlobalBuffer((__gm__ half*)y + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
zGm.SetGlobalBuffer((__gm__ half*)z + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
// 管道分配内存给队列,单位是字节
pipe.InitBuffer(inQueueX, BUFFER_NUM, TILE_LENGTH * sizeof(half));
pipe.InitBuffer(inQueueY, BUFFER_NUM, TILE_LENGTH * sizeof(half));
pipe.InitBuffer(outQueueZ, BUFFER_NUM, TILE_LENGTH * sizeof(half));
}
__aicore__ inline void Process()
{
// 由于双缓冲,循环计数需要翻倍
constexpr int32_t loopCount = TILE_NUM * BUFFER_NUM;
// 分块策略,流水线并行
for (int32_t i = 0; i < loopCount; i++) {
CopyIn(i);
Compute(i);
CopyOut(i);
}
}
private:
__aicore__ inline void CopyIn(int32_t progress)
{
// 从队列内存中分配张量
LocalTensor<half> xLocal = inQueueX.AllocTensor<half>();
LocalTensor<half> yLocal = inQueueY.AllocTensor<half>();
// 将第progress个分块从全局张量复制到局部张量
DataCopy(xLocal, xGm[progress * TILE_LENGTH], TILE_LENGTH);
DataCopy(yLocal, yGm[progress * TILE_LENGTH], TILE_LENGTH);
// 将输入张量入队到VECIN队列
inQueueX.EnQue(xLocal);
inQueueY.EnQue(yLocal);
}
__aicore__ inline void Compute(int32_t progress)
{
// 从VECIN队列中出队输入张量
LocalTensor<half> xLocal = inQueueX.DeQue<half>();
LocalTensor<half> yLocal = inQueueY.DeQue<half>();
LocalTensor<half> zLocal = outQueueZ.AllocTensor<half>();
// 调用Add指令进行计算
Add(zLocal, xLocal, yLocal, TILE_LENGTH);
// 将输出张量入队到VECOUT队列
outQueueZ.EnQue<half>(zLocal);
// 释放输入张量以便重用
inQueueX.FreeTensor(xLocal);
inQueueY.FreeTensor(yLocal);
}
__aicore__ inline void CopyOut(int32_t progress)
{
// 从VECOUT队列中出队输出张量
LocalTensor<half> zLocal = outQueueZ.DeQue<half>();
// 将第progress个分块从局部张量复制到全局张量
DataCopy(zGm[progress * TILE_LENGTH], zLocal, TILE_LENGTH);
// 释放输出张量以便重用
outQueueZ.FreeTensor(zLocal);
}
private:
TPipe pipe;
// 为输入创建队列,在这种情况下深度等于缓冲区数量
TQue<QuePosition::VECIN, BUFFER_NUM> inQueueX, inQueueY;
// 为输出创建队列,在这种情况下深度等于缓冲区数量
TQue<QuePosition::VECOUT, BUFFER_NUM> outQueueZ;
GlobalTensor<half> xGm, yGm, zGm;
};
// 核函数的实现
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{
KernelAdd op;
op.Init(x, y, z);
op.Process();
}
#ifndef __CCE_KT_TEST__
// 核函数的调用
void add_custom_do(uint32_t blockDim, void* l2ctrl, void* stream, uint8_t* x, uint8_t* y, uint8_t* z)
{
add_custom<<<blockDim, l2ctrl, stream>>>(x, y, z);
}
#endif
4. 核函数运行验证(main.cpp)
完成核函数开发后,编写host侧的调用程序进行CPU侧和NPU侧的运行验证。
4.1 主函数框架(main)
应用程序框架编写。该应用程序通过__CCE_KT_TEST__ 宏区分代码逻辑运行于CPU侧还是NPU侧。
#include "data_utils.h" // 引入数据处理工具头文件
// 如果没有定义__CCE_KT_TEST__宏,则包含ACL头文件,否则包含TikiCPU库头文件
#ifndef __CCE_KT_TEST__
#include "acl/acl.h" // 引入AscendCL头文件,用于NPU编程
extern void add_custom_do(uint32_t coreDim, void* l2ctrl, void* stream, uint8_t* x, uint8_t* y, uint8_t* z);
#else
#include "tikicpulib.h" // 引入TikiCPU库头文件,用于CPU模拟NPU行为
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z); // 声明核函数
#endif
int32_t main(int32_t argc, char* argv[])
{
size_t inputByteSize = 8 * 2048 * sizeof(uint16_t); // 计算输入数据的字节大小,uint16_t类型代表half精度浮点数
size_t outputByteSize = 8 * 2048 * sizeof(uint16_t); // 计算输出数据的字节大小,uint16_t类型代表half精度浮点数
uint32_t blockDim = 8; // 定义块尺寸,即在NPU上并行执行的核的数量
#ifdef __CCE_KT_TEST__
// 如果定义了__CCE_KT_TEST__宏,表示进行CPU调试,下面代码块将被编译
// 用于CPU调试的调用程序
#else
// 如果没有定义__CCE_KT_TEST__宏,表示在NPU上运行,下面代码块将被编译
// NPU侧运行算子的调用程序
#endif
return 0; // 程序正常退出
}
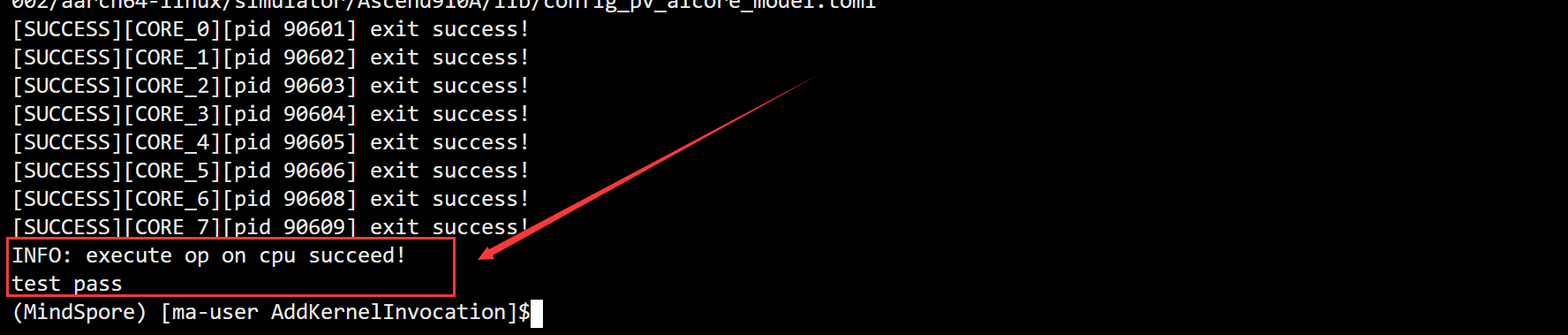
4.2 CPU侧运行验证
// 使用GmAlloc分配共享内存,并进行数据初始化
uint8_t* x = (uint8_t*)AscendC::GmAlloc(inputByteSize);
uint8_t* y = (uint8_t*)AscendC::GmAlloc(inputByteSize);
uint8_t* z = (uint8_t*)AscendC::GmAlloc(outputByteSize);
ReadFile("./input/input_x.bin", inputByteSize, x, inputByteSize);
ReadFile("./input/input_y.bin", inputByteSize, y, inputByteSize);
// 矢量算子需要设置内核模式为AIV模式
AscendC::SetKernelMode(KernelMode::AIV_MODE);
// 调用ICPU_RUN_KF调测宏,完成核函数CPU侧的调用
ICPU_RUN_KF(add_custom, blockDim, x, y, z);
// 输出数据写出
WriteFile("./output/output_z.bin", z, outputByteSize);
// 调用GmFree释放申请的资源
AscendC::GmFree((void *)x);
AscendC::GmFree((void *)y);
AscendC::GmFree((void *)z);
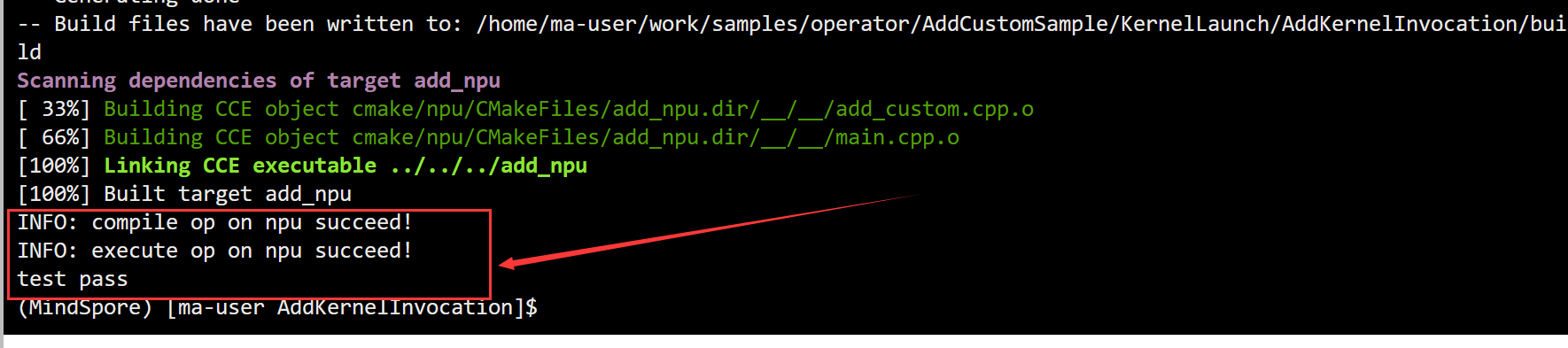
4.3 NPU侧运行验证
// AscendCL初始化
CHECK_ACL(aclInit(nullptr));
// 运行管理资源申请
aclrtContext context;
int32_t deviceId = 0;
CHECK_ACL(aclrtSetDevice(deviceId));
CHECK_ACL(aclrtCreateContext(&context, deviceId));
aclrtStream stream = nullptr;
CHECK_ACL(aclrtCreateStream(&stream));
// 分配Host内存
uint8_t *xHost, *yHost, *zHost;
uint8_t *xDevice, *yDevice, *zDevice;
CHECK_ACL(aclrtMallocHost((void**)(&xHost), inputByteSize));
CHECK_ACL(aclrtMallocHost((void**)(&yHost), inputByteSize));
CHECK_ACL(aclrtMallocHost((void**)(&zHost), outputByteSize));
// 分配Device内存
CHECK_ACL(aclrtMalloc((void**)&xDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));
CHECK_ACL(aclrtMalloc((void**)&yDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));
CHECK_ACL(aclrtMalloc((void**)&zDevice, outputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));
// Host内存初始化
ReadFile("./input/input_x.bin", inputByteSize, xHost, inputByteSize);
ReadFile("./input/input_y.bin", inputByteSize, yHost, inputByteSize);
CHECK_ACL(aclrtMemcpy(xDevice, inputByteSize, xHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE));
CHECK_ACL(aclrtMemcpy(yDevice, inputByteSize, yHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE));
// 用内核调用符<<<>>>调用核函数完成指定的运算,add_custom_do中封装了<<<>>>调用
add_custom_do(blockDim, nullptr, stream, xDevice, yDevice, zDevice);
CHECK_ACL(aclrtSynchronizeStream(stream));
// 将Device上的运算结果拷贝回Host
CHECK_ACL(aclrtMemcpy(zHost, outputByteSize, zDevice, outputByteSize, ACL_MEMCPY_DEVICE_TO_HOST));
WriteFile("./output/output_z.bin", zHost, outputByteSize);
// 释放申请的资源
CHECK_ACL(aclrtFree(xDevice));
CHECK_ACL(aclrtFree(yDevice));
CHECK_ACL(aclrtFree(zDevice));
CHECK_ACL(aclrtFreeHost(xHost));
CHECK_ACL(aclrtFreeHost(yHost));
CHECK_ACL(aclrtFreeHost(zHost));
// AscendCL去初始化
CHECK_ACL(aclrtDestroyStream(stream));
CHECK_ACL(aclrtDestroyContext(context));
CHECK_ACL(aclrtResetDevice(deviceId));
CHECK_ACL(aclFinalize());
5. 数据生成(gen_data.py )
以固定shape的add_custom算子为例,输入数据和真值数据生成的脚本样例如下:根据算子的输入输出编写脚本,生成输入数据和真值数据。
#!/usr/bin/python3
# -*- coding:utf-8__
# 版权所有 (c) 华为技术有限公司 2022-2023。
import numpy as np # 导入numpy库,用于科学计算
# 定义生成基准数据的函数
def gen_golden_data_simple():
# 生成两个大小为[8, 2048]的随机数矩阵,范围在[-100, 100]之间,数据类型为float16
input_x = np.random.uniform(-100, 100, [8, 2048]).astype(np.float16)
input_y = np.random.uniform(-100, 100, [8, 2048]).astype(np.float16)
# 计算两个矩阵的和,得到基准数据(golden data),数据类型为float16
golden = (input_x + input_y).astype(np.float16)
# 将生成的输入矩阵input_x和input_y分别保存到二进制文件"./input/input_x.bin"和"./input/input_y.bin"
# 将基准数据golden保存到二进制文件"./output/golden.bin",用于后续结果验证
input_x.tofile("./input/input_x.bin")
input_y.tofile("./input/input_y.bin")
golden.tofile("./output/golden.bin")
if __name__ == "__main__":
# 调用函数生成基准数据
gen_golden_data_simple()
6.运行验证
完成上述文件的编写后,可以执行一键式编译运行脚本,编译和运行应用程序。
执行脚本前需要配置环境变量ASCEND_HOME_DIR,配置为CANN软件的安装路径,示例如下,请根据实际安装路径进行修改:
export ASCEND_HOME_DIR=usr/local/Ascend/ascend-toolkit/latest
脚本执行方式和脚本参数介绍如下:
- <soc_version> :在安装昇腾AI处理器的服务器执行npu-smi info命令进行查询,在查询到的“Name”前增加Ascend信息
- <run_mode>:表明算子以cpu模式或npu模式运行。
bash run.sh <soc_version> <run_mode>


![代码随想录<span style='color:red;'>算法</span><span style='color:red;'>训练</span><span style='color:red;'>营</span><span style='color:red;'>第二</span>十四天 | 回溯<span style='color:red;'>算法</span>理论<span style='color:red;'>基础</span>,77. 组合 [回溯<span style='color:red;'>篇</span>]](https://img-blog.csdnimg.cn/direct/a34f6881cfd94dfa8b5eb65d7cdcbd1e.png)