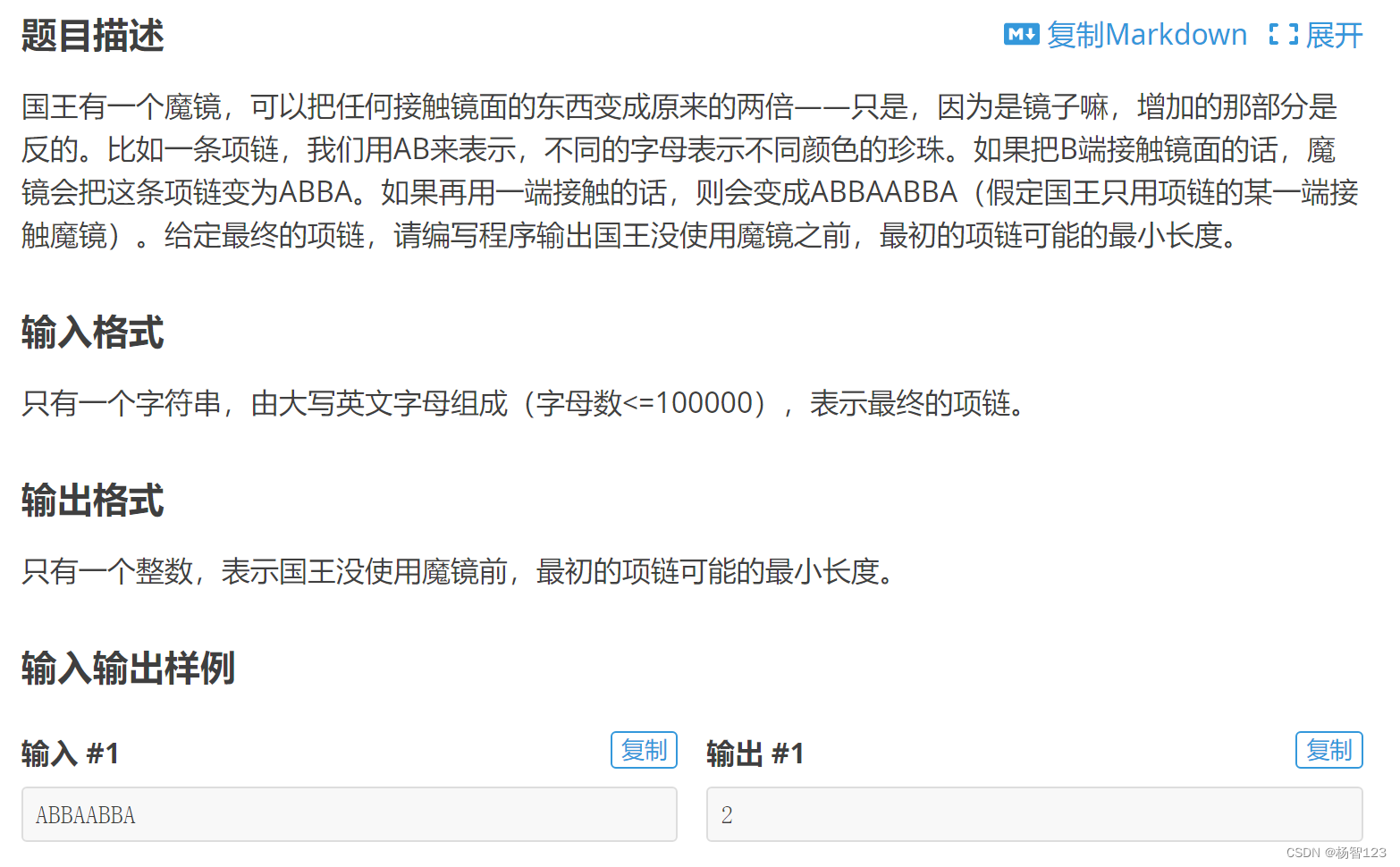
在使用Spark和Doris进行数据仓库开发时,报表生成的效率对于业务分析和决策支持至关重要。当报表复杂且数据量大时,任何改动都可能导致需要重新从零开始处理数据,这不仅耗时而且资源消耗巨大。更为严重的时,可以导致项目延期,影响了绩效,甚至因此失业。为了优化这一过程,可以采取以下措施:
1. 分成独立的几个部分
采用分而治之的思想,把报表分为相互独立的几个部分,这几个互相独立的部分可以考虑都保存DWS层的表,这样出错时需要重跑时,只需要修改其中一部分,并重新跑Union操作互相独立几部分。
2、充分考虑复用
在BI报表开发时,要避免烟囱式开发。相同的指标,尽量只有一个地方去计算,别的报表不要重复计算,而是去使用它。例如下面的代码就是从别的报表获取指标:
val callrecordColumnsSeq = DIM_COM_SEQ :+ "multiple_cases" :+ "identity_number" :+ "total_manual_call_duration" :+ "total_manual_call_duration_nowait" :+ "total_mediation_num" :+ "ai_outbound_mediation_record_num" :+ "manual_mediation_num"
var callrecordDF = readDoris(spark, DATABASE_NAME + ".dws__callrecord").filter("dt='" + dt + "'"