协程Goroutine
在java/c++中我们要实现并发编程的时候,我们通常需要自己维护一个线程池,并且需要自己去包装一个又一个的任务,同时需要自己去调度线程执行任务并维护上下文切换,这一切通常会耗费程序员大量的心智。那么能不能有一种机制,程序员只需要定义很多个任务,让系统去帮助我们把这些任务分配到CPU上实现并发执行呢?
在Go语言编程中你不需要去自己写进程、线程、协程,当你需要让某个任务并发执行的时候,你只需要把这个任务包装成一个go修饰的函数就可以了。
func main(){
go hello("A");
}
func hello(name string) string {
return "Hellow "
}
golang协程调度
操作系统线程一般都有固定的栈内存(通常为2MB),一个goroutine的栈在其生命周期开始时只有很小的栈(典型情况下2KB),goroutine的栈不是固定的,他可以按需增大和缩小,goroutine的栈大小限制可以达到1GB,虽然极少会用到这个大。所以在Go语言中一次创建十万左右的goroutine也是可以的。
GPM是Go语言运行时(runtime)层面的实现,是go语言自己实现的一套调度系统。区别于操作系统调度OS线程。
1.G很好理解,就是个goroutine的,里面除了存放本goroutine信息外 还有与所在P的绑定等信息。
2.P管理着一组goroutine队列,P里面会存储当前goroutine运行的上下文环境(函数指针,堆栈地址及地址边界),P会对自己管理的goroutine队列做一些调度(比如把占用CPU时间较长的goroutine暂停、运行后续的goroutine等等)当自己的队列消费完了就去全局队列里取,如果全局队列里也消费完了会去其他P的队列里抢任务。
3.M(machine)是Go运行时(runtime)对操作系统内核线程的虚拟, M与内核线程一般是一一映射的关系, 一个groutine最终是要放到M上执行的;
P与M一般也是一一对应的。他们关系是: P管理着一组G挂载在M上运行。当一个G长久阻塞在一个M上时,runtime会新建一个M,阻塞G所在的P会把其他的G 挂载在新建的M上。当旧的G阻塞完成或者认为其已经死掉时 回收旧的M。
P的个数是通过runtime.GOMAXPROCS设定(最大256),Go1.5版本之后默认为物理线程数。 在并发量大的时候会增加一些P和M,但不会太多,切换太频繁的话得不偿失。
单从线程调度讲,Go语言相比起其他语言的优势在于OS线程是由OS内核来调度的,goroutine则是由Go运行时(runtime)自己的调度器调度的,这个调度器使用一个称为m:n调度的技术(复用/调度m个goroutine到n个OS线程)。 其一大特点是goroutine的调度是在用户态下完成的, 不涉及内核态与用户态之间的频繁切换,包括内存的分配与释放,都是在用户态维护着一块大的内存池, 不直接调用系统的malloc函数(除非内存池需要改变),成本比调度OS线程低很多。 另一方面充分利用了多核的硬件资源,近似的把若干goroutine均分在物理线程上, 再加上本身goroutine的超轻量,以上种种保证了go调度方面的性能。
Sync包
有时候在Go代码中可能会存在多个goroutine同时操作一个资源(临界区),这种情况会发生竞态问题(数据竞态)。
互斥锁
互斥锁是一种常用的控制共享资源访问的方法,它能够保证同时只有一个goroutine可以访问共享资源。Go语言中使用sync包的Mutex类型来实现互斥锁。
互斥锁主要就是上锁和解锁操作。
package main
import (
"fmt"
"sync"
"time"
)
// Go 程序的默认入口函数(主函数).
func main() {
mutex_lock := &sync.Mutex{}
go hello(mutex_lock, "json")
go hello(mutex_lock, "yuehan")
go hello(mutex_lock, "jayeu")
for {} //防止主程序退出导致协程无法被执行
}
func hello(lock *sync.Mutex, name string) {
lock.Lock()
fmt.Println("Hello%s", name)
time.Sleep(1 * time.Second)
lock.Unlock()
}
执行结果是每隔1s打印一下,为什么呢,因为使用互斥锁能够保证同一时间有且只有一个goroutine进入临界区,其他的goroutine则在等待锁;当互斥锁释放后,等待的goroutine才可以获取锁进入临界区,多个goroutine同时等待一个锁时,唤醒的策略是随机的(并发无法保证哪个获得所有权)。
读写互斥锁
互斥锁是完全互斥的,但是有很多实际的场景下是读多写少的,当我们并发的去读取一个资源不涉及资源修改的时候是没有必要加锁的,这种场景下使用读写锁是更好的一种选择。读写锁在Go语言中使用sync包中的RWMutex类型。
当一个goroutine获取读锁之后,其他的goroutine如果是获取读锁会继续获得锁,如果是获取写锁就会等待;当一个goroutine获取写锁之后,其他的goroutine无论是获取读锁还是写锁都会等待。
读锁示例
package main
import (
"fmt"
"sync"
"time"
)
// Go 程序的默认入口函数(主函数).
func main() {
rwmutex_lock := &sync.RWMutex{}
go hello(rwmutex_lock, "json")
go hello(rwmutex_lock, "yuehan")
go hello(rwmutex_lock, "jayeu")
for {
}
}
func hello(lock *sync.RWMutex, name string) {
lock.RLock()
fmt.Println("Hello%s", name)
time.Sleep(1 * time.Second)
lock.RLock()
}
这段程序执行,我们可以看到瞬间打印了hellow 【name】,读锁不互斥,不会阻塞其他读取锁,但是与写锁互斥。
写锁示例
package main
import (
"fmt"
"sync"
"time"
)
var (
x int32
lock sync.Mutex
rwmutex_lock sync.RWMutex
)
func main() {
go write_lock(rwmutex_lock)
go write_lock(rwmutex_lock)
go write_lock(rwmutex_lock)
go read_lock(rwmutex_lock)
go read_lock(rwmutex_lock)
go read_lock(rwmutex_lock)
for {
}
}
func write_lock(lock sync.RWMutex) {
lock.Lock()
x++
fmt.Println("写锁\t ", x)
time.Sleep(1 * time.Second)
lock.Unlock()
}
func read_lock(lock sync.RWMutex) {
lock.RLock()
fmt.Println("读锁\t", x)
time.Sleep(1 * time.Second)
lock.RUnlock()
}
/*
写锁 1
写锁 2
读锁 2
写锁 3
读锁 3
读锁 3
*/
Once
在编程的很多场景下我们需要确保某些操作在高并发的场景下只执行一次,例如只加载一次配置文件、只关闭一次通道等。
sync.Once只有一个Do方法,其签名如下:
package main
import (
"fmt"
"sync"
"time"
)
var (
x int32
lock sync.Mutex
rwmutex_lock sync.RWMutex
once sync.Once
)
func main() {
once.Do(func() { read_lock(rwmutex_lock) })
once.Do(func() { read_lock(rwmutex_lock) })
once.Do(func() { read_lock(rwmutex_lock) })
for {
}
}
func read_lock(lock sync.RWMutex) {
lock.RLock()
fmt.Println("读锁\t", x)
time.Sleep(1 * time.Second)
lock.RUnlock()
}
// 读锁 0
可以看到只要once是同一个,无论执行多少次once.Do内部回调只会执行一次。
实现原理:依赖于计数,内部存放执行次数,当次数为0执行函数回调,并上锁。
WaitGroup
之前我们都是用for{} 来防止主程序运行完退出,Go语言中可以使用sync.WaitGroup来实现并发任务的同步。
WaitGroup等待组有三个主要方法
- 通过Add方法要等待的任务数量,函数签名为
(wg * WaitGroup) Add(delta int) Done表示某个任务执行完成了内部会将等待组任务数量–,其函数签名为(wg *WaitGroup) Done()Wait阻塞知道等待组任务数量为0,其函数签名为(wg *WaitGroup) Wait()
package main
import (
"fmt"
"sync"
"time"
)
var (
x int32
lock sync.Mutex
rwmutex_lock sync.RWMutex
once sync.Once
wg sync.WaitGroup
)
func main() {
wg.Add(3)
go read_lock(lock)
go read_lock(lock)
go read_lock(lock)
wg.Wait()
}
func read_lock(lock sync.Mutex) {
time.Sleep(3 * time.Second)
fmt.Println(x)
wg.Done()
}
Map
Go语言中内置的map不是并发安全的。如果并发对一个map进行读写会报错,示例如下
package main
import (
"fmt"
"strconv"
"sync"
)
var m = make(map[string]int)
func get(key string) int {
return m[key]
}
func set(key string, value int) {
m[key] = value
}
func main() {
wg := sync.WaitGroup{}
for i := 0; i < 20; i++ {
wg.Add(1)
go func(n int) {
key := strconv.Itoa(n)
set(key, n)
fmt.Printf("k=:%v,v:=%v\n", key, get(key))
wg.Done()
}(i)
}
wg.Wait()
}
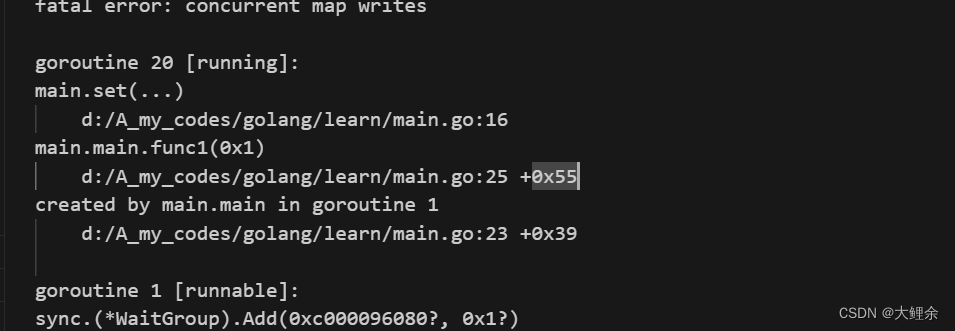
这种场景下就需要为map加锁来保证并发的安全性了,Go语言的sync包中提供了一个开箱即用的并发安全版map–sync.Map。开箱即用表示不用像内置的map一样使用make函数初始化就能直接使用。同时sync.Map内置了诸如Store、Load、LoadOrStore、Delete、Range等操作方法。
package main
import (
"fmt"
"strconv"
"sync"
)
var m = sync.Map{}
func main() {
wg := sync.WaitGroup{}
for i := 0; i < 20; i++ {
wg.Add(1)
go func(n int) {
key := strconv.Itoa(n)
m.Store(key, n)
value, _ := m.Load(key)
fmt.Printf("k=:%v,v:=%v\n", key, value)
wg.Done()
}(i)
}
wg.Wait()
}
/*
k=:18,v:=18
k=:4,v:=4
k=:3,v:=3
k=:7,v:=7
k=:2,v:=2
k=:1,v:=1
k=:0,v:=0
k=:5,v:=5
k=:6,v:=6
k=:19,v:=19
k=:8,v:=8
k=:9,v:=9
k=:10,v:=10
k=:11,v:=11
k=:12,v:=12
k=:13,v:=13
k=:14,v:=14
k=:15,v:=15
k=:16,v:=16
k=:17,v:=17
*/
Pool并发池
Pool是一个可以分别存取的临时对象的集合。
Pool中保存的任何item都可能随时不做通告的释放掉。如果Pool持有该对象的唯一引用,这个item就可能被回收。
Pool的目的是缓存申请但未使用的item用于之后的重用,以减轻GC的压力。也就是说,让创建高效而线程安全的空闲列表更容易。但Pool并不适用于所有空闲列表。这如何理解呢?简单来说,当我们需要频繁地创建和销毁对象时,会导致大量的内存分配和垃圾回收操作,从而降低程序的性能。通过使用Pool,我们可以将这些对象缓存起来,以便在后续需要时直接重用,而不是再次进行分配和释放操作。这样可以减少内存分配的次数,降低垃圾回收的频率,提高程序的性能。
Pool的合理用法是用于管理一组静静的被多个独立并发线程共享并可能重用的临时item。Pool提供了让多个线程分摊内存申请消耗的方法。怎么理解?
1.Pool的作用之一是让多个线程共享和分摊内存申请的消耗。通过将对象缓存在Pool中,线程可以直接从Pool中获取对象,而不需要每次都进行内存申请。
2.Pool适合用于管理一组静态的临时对象或资源。这些对象可以是事先创建好的,并且在多个独立的并发线程中被共享和重用。Pool负责对这些对象进行有效的分配和回收,以满足线程的需求。
3.Pool中的对象是可以被重用的临时item。这意味着当一个线程使用完一个对象后,可以将该对象归还给Pool,以便其他线程可以重新使用它。通过重用临时item,可以避免频繁地创建和销毁对象,减少内存分配和垃圾回收的开销。
Pool可以安全的被多个线程同时使用。
使用方法
Pool只有两个方法,分别是func (p *Pool) Get() interface{}和func (p *Pool) Put(x interface{})
Get方法从池中选择任意一个item,删除其在池中的引用计数,并提供给调用者。如果pool池为空则取得值为nil
Put方法将x放入池中。
func main(){
pool := &sync.Pool{}
pool.put(1)
fmt.Println(pool.get())
}
使用场景
对象的创建和销毁操作开销较大:如果对象的创建和销毁操作比较耗时,那么使用Pool可以避免频繁地进行这些操作,提高性能。
对象的重用频率高:如果对象在程序执行过程中会频繁地被使用和释放,并且对象的重用频率较高,那么使用Pool可以显著减少对象的创建和销毁次数,提高性能。
对象的生命周期较短:如果对象的生命周期比较短,即对象在创建后很快就会被释放,那么使用Pool可以减少内存分配和垃圾回收的开销。























![[蓝桥杯 2022 国 B] 出差(P8802)](https://img-blog.csdnimg.cn/direct/bf7c7cf712e747e7a29fcf0cec32f2f7.png)