DashVector
文章目录
一、关于 DashVector
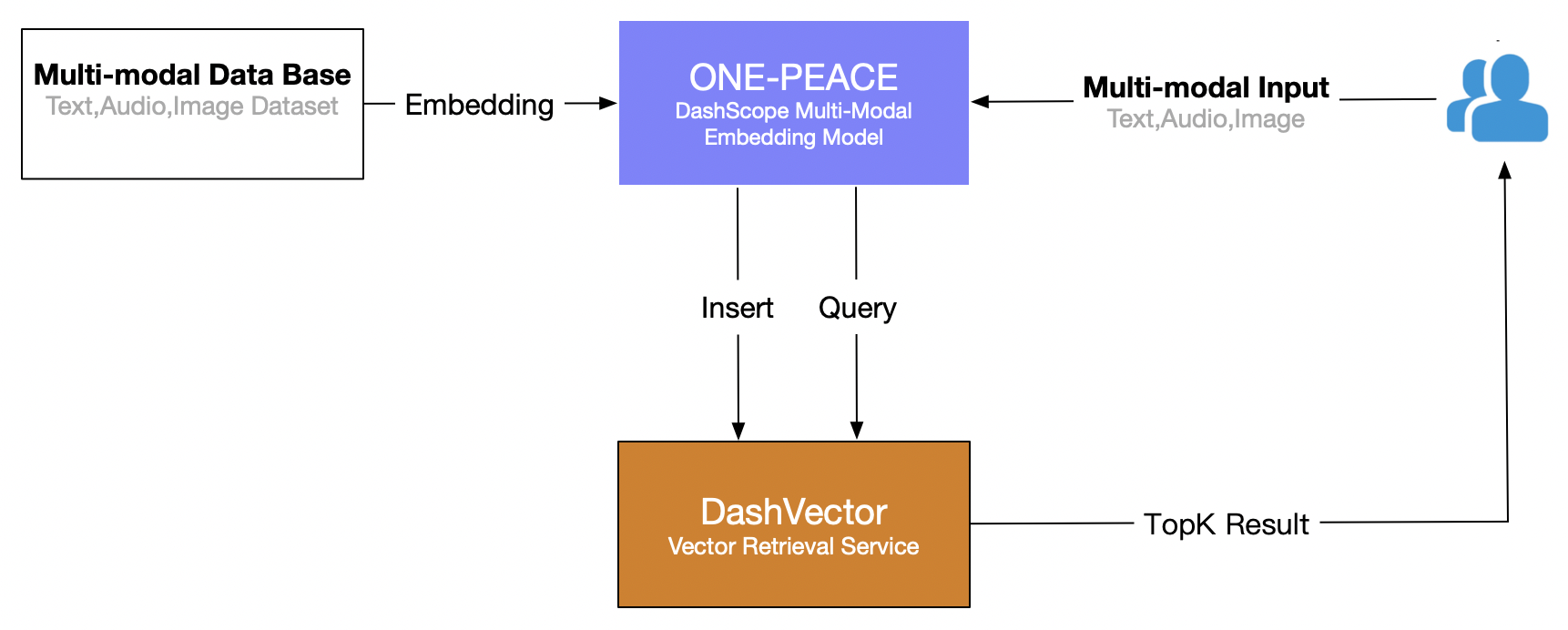
向量检索服务DashVector基于通义实验室自研的高效向量引擎Proxima内核,提供具备水平拓展能力的云原生、全托管的向量检索服务。
DashVector 将其强大的向量管理、向量查询等多样化能力,通过简洁易用的SDK/API接口透出,方便被上层AI应用迅速集成,从而为包括大模型生态、多模态AI搜索、分子结构分析在内的多种应用场景,提供所需的高效向量检索能力。
- 阿里云:向量检索服务
https://help.aliyun.com/document_detail/2510225.html - 产品首页:https://www.aliyun.com/product/ai/dashvector
- DashVector PYPI : https://pypi.org/project/dashvector/
- LangChain - DashVector
https://python.langchain.com/docs/integrations/vectorstores/dashvector - 实践教程 : https://help.aliyun.com/document_detail/2510233.html
二、使用 DashVector 前提准备
1、创建Cluster:
https://help.aliyun.com/document_detail/2631966.html
1)登录向量检索服务控制台。
https://dashvector.console.aliyun.com/
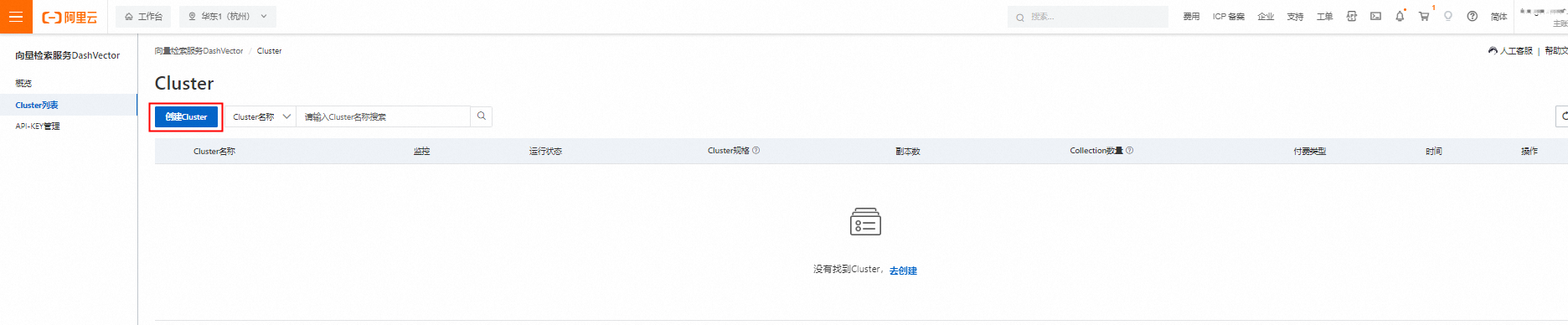
2)在左侧导航栏单击Cluster列表,单击创建Cluster。
3)选择Cluster实例类型、实例规格、副本数,填写Cluster名称,单击立即购买。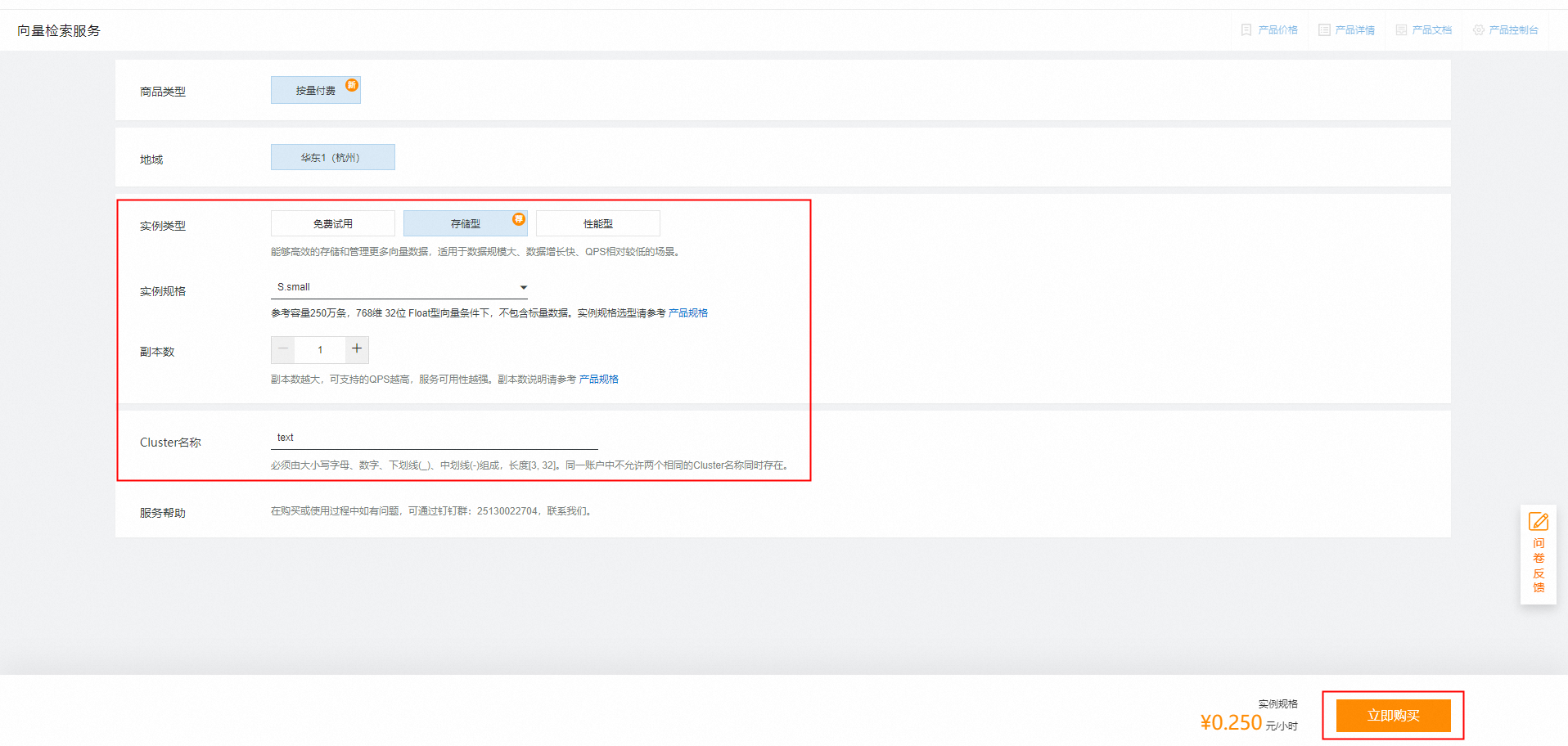
参数说明
| 参数 | 描述 |
|---|---|
| 商品类型 | 向量检索服务的收费类型。当前仅支持按量付费。详见产品计费。 |
| 地域 | 向量检索服务所在地域。当前仅支持**华东1(杭州)**地域。 |
| 实例类型 | 向量检索服务DashVector当前支持三种实例类型,以支持不同的业务场景和需求: 性能型:提供更高的QPS和更低的查询延迟,适用于高并发、大流量、延迟敏感或对写入和查询效率有较高要求的场景。 存储型:相对于性能型有5倍的存储容量优势,能够存储和管理更多的向量数据,适用于数据规模大、数据增长快、QPS相对较低的场景。 免费试用:适用于测试、体验场景,请勿用于线上生产环境。免费试用实例有效期为1个月,到期后可再次申请试用。免费实例有部分试用限制,详情可参考约束与限制。 说明 付费Cluster,最多可创建32个Collection。免费试用Cluster,最多可创建2个Collection。 重要 每个账户同一时间段仅能创建一个免费试用Cluster。免费试用Cluster到期或主动释放后可以再次创建一个免费试用Cluster。 免费试用Cluster,创建后30个自然日到期会自动释放,删除所有数据。如有重要业务数据,请及时转移到付费Cluster或者将免费试用Cluster升配为付费Cluster。 |
| 实例规格 | 免费试用Cluster:采用Serverless架构,适用于快速体验产品。免费试用实例使用限制请参考约束与限制。 存储型和性能型Cluster分别提供6种可选规格,不同规格的主要区别在于存储容量的不同。实例规格详情,请参见实例规格。 |
| 副本数 | 向量检索服务DashVector支持调整副本数,可选范围为1-5。副本之间数据完全相同,副本数越大,可支持的QPS越高,呈线性关系。同时副本数越大,服务可用性越高,建议对可用性有较高要求的生产环境选择>=2的副本数。 说明 需要注意,副本数的增加和减少不会影响存储容量,仅影响QPS和可用性。 |
| 实例名称 | 必须由大小写字母、数字、下划线(_)、中划线(-)组成,长度[3, 32]。同一账户中不允许两个相同的Cluster名称同时存在。 |
4)确认实例信息,勾选服务协议,然后单击立即开通。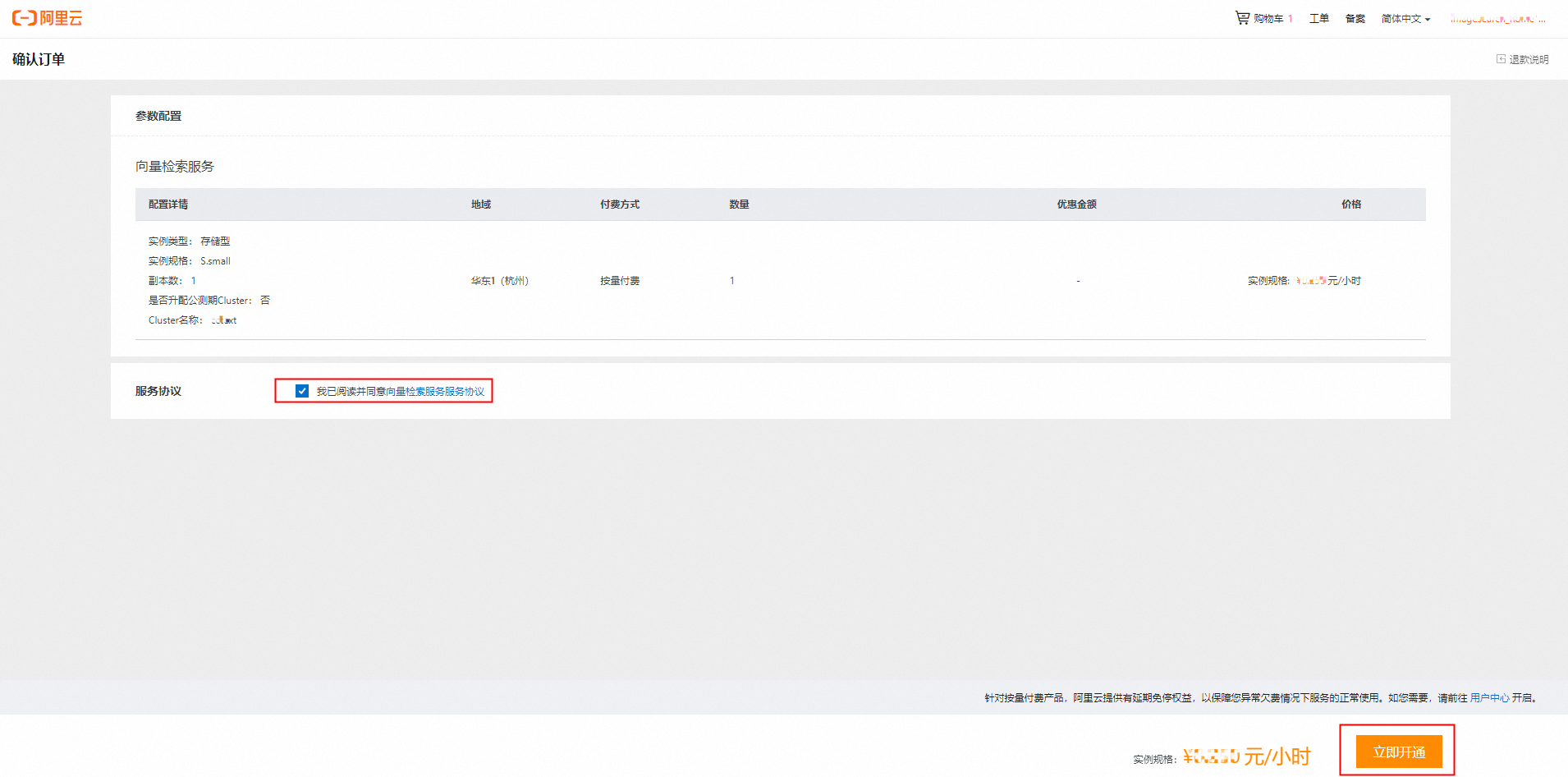
5)单击管理控制台跳转至控制台概览页,Cluster创建成功后,即可正常使用向量检索服务。 
2、获得API-KEY
API-KEY管理:https://help.aliyun.com/document_detail/2510230.html
dashscope API-Key : https://dashscope.console.aliyun.com/apiKey
3、安装最新版SDK
安装DashVector SDK:https://help.aliyun.com/document_detail/2510231.html
DashVector向量检索服务提供下列编程语言的SDK供开发者选择。
- Python SDK
- Java SDK
- HTTP API https://help.aliyun.com/document_detail/2510275.html
- 更多编程语言的DashVector SDK将在稍后陆续提供。
python 安装
pip3 install dashvector
升级:
pip3 install dashvector --upgrade
三、快速使用 DashVector
转载自:https://help.aliyun.com/document_detail/2510223.html
1. 创建Client
使用HTTP API时可跳过本步骤。
import dashvector
client = dashvector.Client(
api_key='YOUR_API_KEY',
endpoint='YOUR_CLUSTER_ENDPOINT'
)
assert client
2. 创建Collection
创建一个名称为quickstart,向量维度为4的collection。
client.create(name='quickstart', dimension=4)
collection = client.get('quickstart')
assert collection
说明
- 在未指定距离度量参数时,将使用默认的Cosine距离度量方式。
- 在未指定向量数据类型时,将使用默认的
Float数据类型。
3、插入Doc
from dashvector import Doc
# 通过dashvector.Doc对象,插入单条数据
collection.insert(Doc(id='1', vector=[0.1, 0.2, 0.3, 0.4]))
# 通过dashvector.Doc对象,批量插入2条数据
collection.insert(
[
Doc(id='2', vector=[0.2, 0.3, 0.4, 0.5], fields={'age': 20, 'name': 'zhangsan'}),
Doc(id='3', vector=[0.3, 0.4, 0.5, 0.6], fields={'anykey': 'anyvalue'})
]
)
4、相似性检索
rets = collection.query([0.1, 0.2, 0.3, 0.4], topk=2)
print(rets)
5、删除Doc
# 删除1条数据
collection.delete(ids=['1'])
6. 查看Collection统计信息
stats = collection.stats()
print(stats)
7. 删除Collection
client.delete('quickstart')
四、关于 Proxima
- proxima github : https://github.com/alibaba/proxima
- proxima 文档:https://proximabilin.github.io/docs/
Proxima 是阿里巴巴达摩院系统 AI 实验室自研的向量检索内核。
目前,其核心能力广泛应用于阿里巴巴和蚂蚁集团内众多业务,如淘宝搜索和推荐、蚂蚁人脸支付、优酷视频搜索、阿里妈妈广告检索等。
同时,Proxima 还深度集成在各式各类的大数据和数据库产品中,如阿里云 Hologres、搜索引擎 Elastic Search 和 ZSearch、离线引擎 MaxCompute (ODPS) 等,为其提供向量检索的能力。
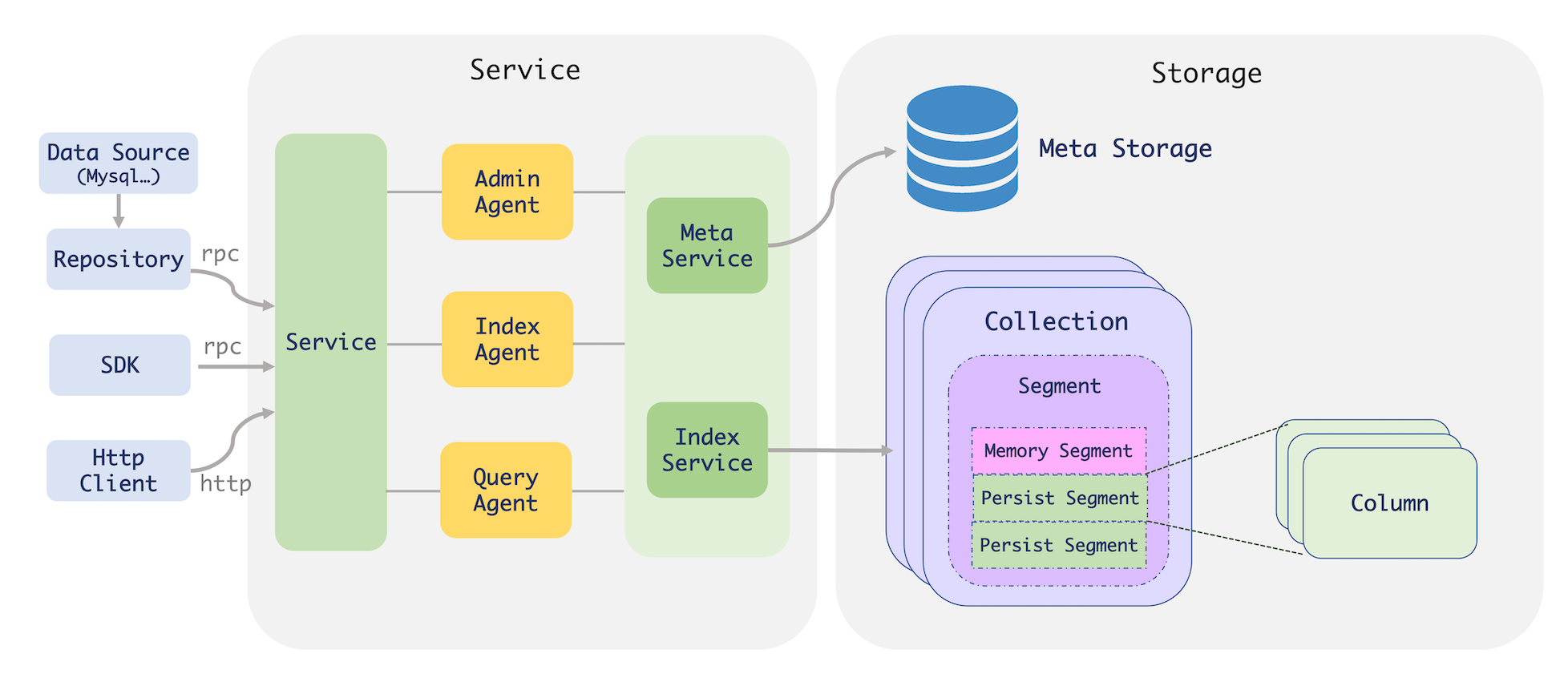
Proxima BE,全称 Proxima Bilin Engine,是 Proxima 团队开发的服务化引擎,实现了对大数据的高性能相似性搜索。
支持 RESTful HTTP 接口访问,同时也支持多种语言的 SDK 以 GRPC 协议访问。
核心能力
Proxima BE 的主要核心能力有以下几点:
- 支持单机超大规模索引:基于底层向量索引的工程和检索算法优化,使得有限成本下,实现了高效率的检索方法,并支持磁盘索引,单片索引可达几十亿的规模。
- 支持多数据源全量和增量同步:通过 Mysql Repository 等组件,可将 mysql 等数据源中的数据,实时同步至索引服务,提供查询能力,简化数据处理流程。
- 支持向量索引实时增删改查:基于全新 CRUD 图索引,支持在线大规模向量索引的从 0 到 1 的流式写入,并实现了索引即时增删改查,避免索引需定期重建。
- 支持正排数据查询:支持在查询时,可展示文档的所有结构化字段。同时后期将基于此功能,进一步扩展出与文本与向量联合检索等功能。
五、构建 Proxima
环境要求:
- Linux or MacOS
- gcc >= 4.9
- cmake >= 3.14
git clone https://github.com/alibaba/proximabilin.git
cd proximabilin && git submodule update --init
mkdir build && cd build
# Build with Debug (Intel Haswell Microarchitecture)
#cmake -DCMAKE_BUILD_TYPE=Debug -DENABLE_HASWELL=ON ..
# Build with Release (Intel Haswell Microarchitecture)
cmake -DCMAKE_BUILD_TYPE=Release -DENABLE_HASWELL=ON ..
make -j all
获取 Docker 镜像
| 平台 | 仓库 | 版本 |
|---|---|---|
| Linux X86_64 | ghcr.io/proximabilin/proxima-be | 0.2.0 |
六、向量检索基本概念
转载自:https://help.aliyun.com/document_detail/2511804.html
Client**(客户端)
Client(客户端),是用户用于连接DashVector服务端的基础对象,相当于关系型数据库中的Connection。通过设置API_KEY即可完成Client对象的创建,即完成与DashVector服务端的连接。通过Client对象可进行Collection操作(如新建Collection、获取Collection列表等)。
Cluster(实例)
Cluster(实例),是面向售卖的资源管理单位,相当于关系型数据库中的一个库,我们提供了不同的实例产品规格以满足用户不同的业务需求。用户可以通过控制台进行Cluster管理操作(如创建Cluster、升配Cluster、释放Cluster)等,在创建好的Cluster里,用户可以进行后续的Collection、Partition 等操作。
说明
- 同一个账户支持创建多个Cluster,账户内单个Cluster名称唯一。
- 每个账户同一时间段仅能创建一个免费试用Cluster,免费试用Cluster到期或主动释放后可以再次创建一个免费试用Cluster。
Collection(集合)
Collection(集合),是一个相同类型Doc组成的集合,相当于关系型数据库中的一张表。每个Collection必须使用唯一的名称来标识,通过名称可唯一获取Collection对象。Collection对象可进行各种Doc操作(如插入Doc、检索Doc等)和Partition操作(如新建Partition等)。
说明
- Collection名称在Cluster内必须唯一,不允许两个相同名称的Collection同时存在。
- 付费Cluster最多支持创建32个支持Collection;免费Cluster最多支持创建2个Collection。
Partition**(分区)
Partition(分区),是指同一个Collection下的Doc可通过不同的Partition进行分区。各种Doc操作(如插入Doc、检索Doc等)如若指定Partition,则该操作将限定在该指定的Paritition内进行。通过合理的Partition设置,可有效提升Doc操作的效率。
Doc**(文档)
Doc(文档),是DashVector最基础的数据单元,相当于关系型数据库中的一行数据。Doc包含以下属性:id(主键)、vector(向量)、fields(key-value结构的字段名和字段值)。Doc是插入Doc、更新Doc、插入或更新Doc操作的基础输入结构,同时也是检索Doc和获取Doc操作的输出结构。
Field(字段)
Field(字段),是组成Doc的基础单位之一,每个Doc可具备多个Field,相当于关系型数据库中的列。
Vector(向量)
Vector(向量),Embedding Vector,非结构化数据通过各种AI Embedding模型进行特征的提取,获取到的多维数据。DashVector中,Vector作为Doc的基础数据单位之一,用于描述各种非结构化数据的特征。例如,[0.1, 0.2, 0.3, 0.4]就是一个维度(dimension)为4的向量。
Sparse Vector(稀疏向量)
Sparse Vector(稀疏向量),稀疏向量是指大部分元素为0,仅少量元素非0的向量。在DashVector中,稀疏向量可用来表示词频等信息。例如,{1:0.4, 10000:0.6, 222222:0.8}就是一个稀疏向量,其第1、10000、222222位元素(分别代表三个关键字)有非0值(代表关键字的权重),其他元素全部为0。
QPS**(访问频次)
每秒能向DashVector服务的API发起的最大查询请求次数。QPS越高,同一时段内能够处理的业务量越多。例如QPS为5时,则在1秒内可以进行5次调用请求。
API-KEY
API-KEY是您访问向量检索服务(DashVector)的密 钥。DashVector通过API-KEY进行调用鉴权和计量计费,目前仅支持通过阿里云主账号进行API-KEY管理,每个账户同时可拥有3个有效的API-KEY。
请妥善保存和使用API-KEY,如需进一步了解API-KEY有关的安全信息,请参考保护并正确使用API-KEY。
伊织 2024-03-22(五)





























![[AutoSar]BSW_Com018 COM模块介绍(二)](https://img-blog.csdnimg.cn/direct/84382a3c560e435da5ef2b99dfe01bc8.png)