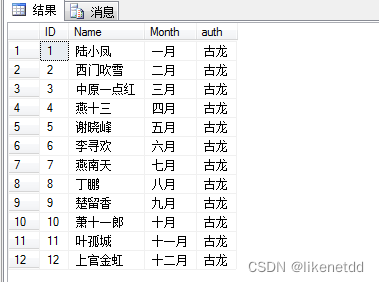
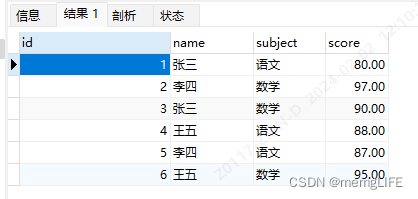
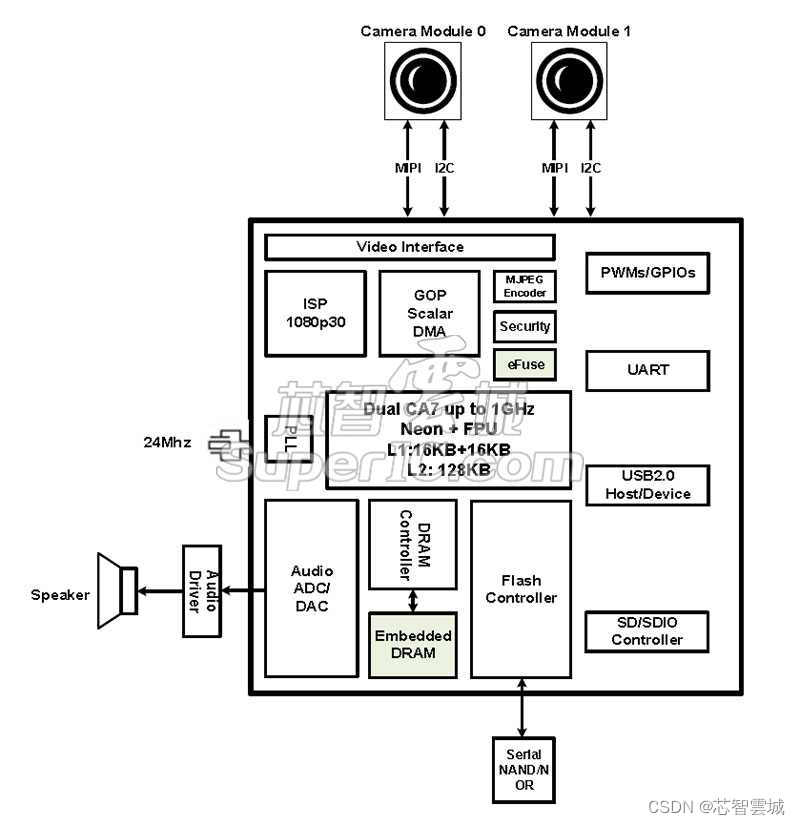
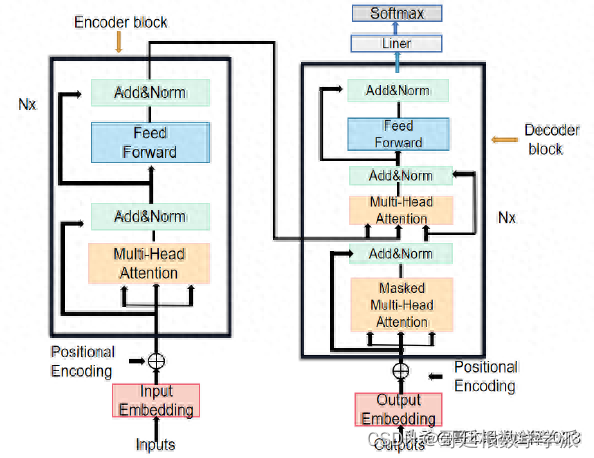
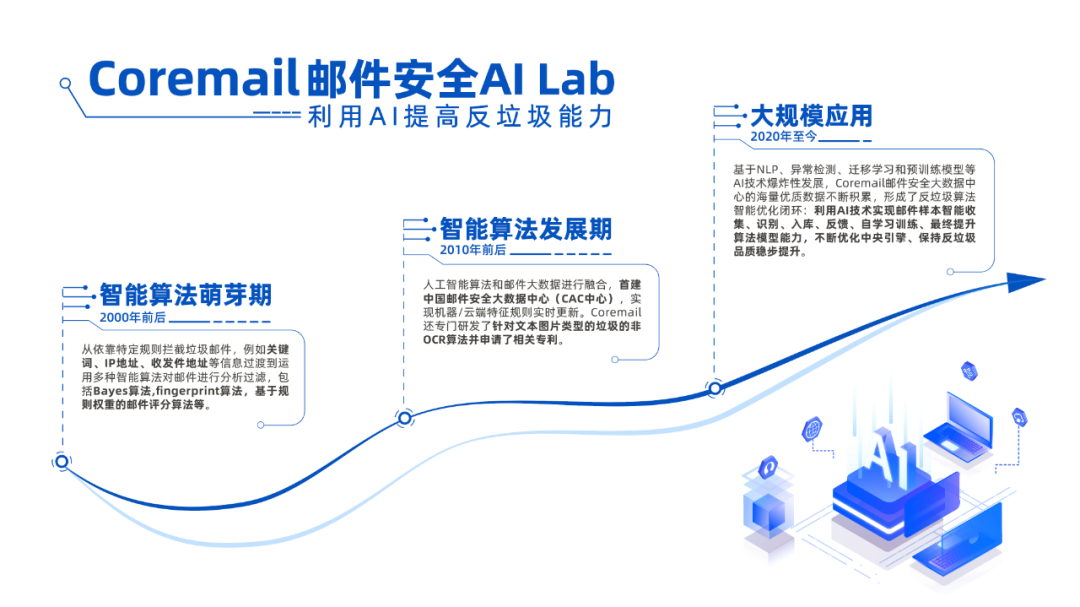
在Python中,如果你想要对数据框(DataFrame)中的某一列进行操作,你可以使用Pandas库,这是处理数据时常用的一个库。以下是一个简单的例子,展示了如何对DataFrame中的某一列进行操作:
首先,你需要安装Pandas库(如果你还没有安装的话):
```bash
pip install pandas
```
然后,你可以使用以下代码:
```python
import pandas as pd
# 创建一个示例DataFrame
data = {
'A': [1, 2, 3, 4],
'B': [5, 6, 7, 8],
'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data)
# 选择列'A'
column_A = df['A']
# 对列'A'中的每个元素加1
df['A'] = column_A + 1
print(df)
```
这段代码首先创建了一个包含三列数据的DataFrame。然后,它选择了列'A',并对该列中的每个元素进行了加1的操作。最后,它打印出了修改后的DataFrame。
如果你想要对列进行更复杂的操作,比如应用一个函数或者进行条件筛选,你可以使用Pandas的`.apply()`方法或者条件索引。例如:
```python
# 使用.apply()方法对列'A'中的每个元素应用一个函数
df['A'] = df['A'].apply(lambda x: x * 2)
# 使用条件索引来选择列'B'中大于6的所有元素
filtered_B = df['B'][df['B'] > 6]
```
在这些例子中,`.apply()`方法允许你对列中的每个元素应用一个函数,而条件索引则允许你根据条件选择列中的特定元素。
记住,这些操作都是向量化的,这意味着它们会直接在底层的数值数组上执行,而不是在Python的循环中逐个元素处理,这样可以显著提高代码的执行效率。