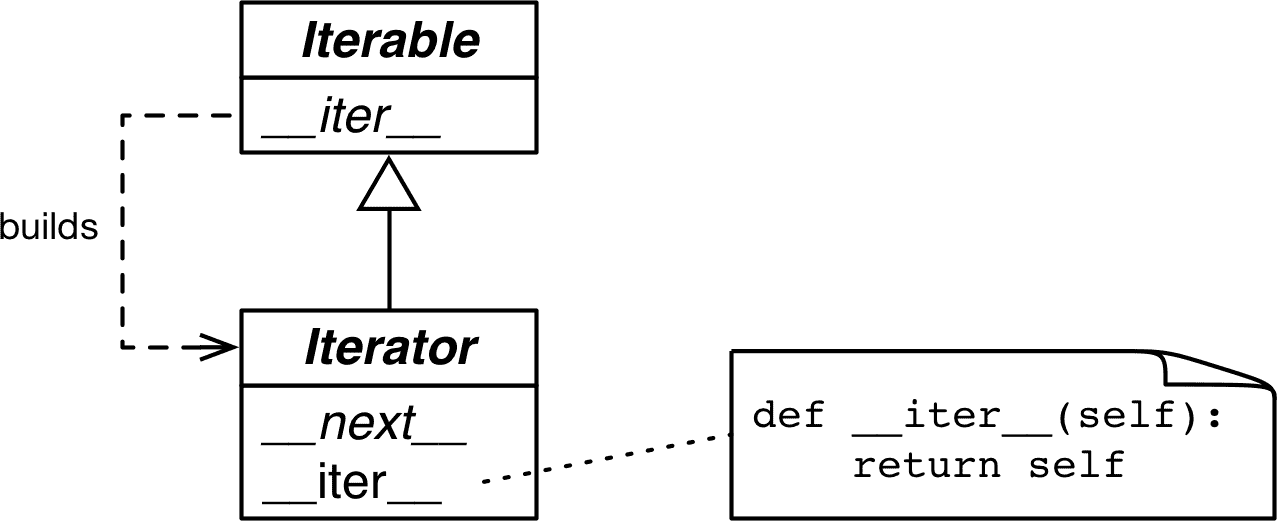
创建KafkaSink对象:
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord, RecordMetadata}
import java.util.concurrent.Future
/**
*
* Author:jianjipan@kanzhun.com
* Date:2024/2/26 10:50
*/
class KafkaSink[K, V](createProducer: () => KafkaProducer[K, V]) extends Serializable {
lazy val producer = createProducer()
def send(topic: String, key: K, value: V): Future[RecordMetadata] =
producer.send(new ProducerRecord[K, V](topic, key, value))
def send(topic: String, value: V): Future[RecordMetadata] =
producer.send(new ProducerRecord[K, V](topic, value))
}
该对象接受一个类型为() => KafkaProducer[K, V]的函数类型参数createProducer。这是一种高阶函数,允许在实例化时提供创建KafkaProducer对象的具体逻辑。
使用了lazy关键字进行声明。这意味着producer属性在首次访问时才会被初始化,延迟了对象的创建,提高了性能。
然后创建KafkaSink单例对象,用来实例化KafkaSink对象
import com.zhipin.model.factory.spark.kafka.KafkaSink
import org.apache.kafka.clients.producer.KafkaProducer
/**
*
* Author:jianjipan@kanzhun.com
* Date:2024/2/26 10:59
*/
object KafkaSink {
import scala.collection.JavaConversions._
def apply[K, V](config: Map[String, Object]): KafkaSink[K, V] = {
val createProducerFunc = () => {
val producer = new KafkaProducer[K, V](config)
sys.addShutdownHook {
producer.close()
}
producer
}
new KafkaSink(createProducerFunc)
}
def apply[K, V](config: java.util.Properties): KafkaSink[K, V] = apply(config.toMap)
}
在Scala中,apply方法是一种特殊的方法,可以在对象名后面使用圆括号调用,就像调用一个函数一样。具体调用的方式有以下几种情况:
对象名():当对象的apply方法没有参数时,可以直接使用圆括号调用,例如obj()。
对象名(参数1, 参数2, …):当对象的apply方法具有参数时,可以通过将参数放入圆括号中来调用,例如obj(arg1, arg2)。
对象名.apply():也可以显式地使用.apply方法来调用。例如obj.apply()。
除了上述示例,还可以在类似于集合的场景下使用apply方法。例如,对于一个List对象list,可以通过下标来访问元素,实际上是调用了list的apply方法。例如list(0)实际上调用了list.apply(0)。
总之,Scala中的apply方法可以让对象像函数一样被调用,提供了一种简洁的语法来创建和调用对象。
然后应用上述方法实现DataFrame数据导入Kafka的逻辑
val sparkConf = new SparkConf().setAppName("DatasetToKafka")
sparkConf.set("spark.serializer", classOf[KryoSerializer].getName)
val spark = SparkSession.builder()
.config(sparkConf)
.getOrCreate()
val taskId=args(0)
val paramEntity = JobArgsService.queryJobArgs(taskId,classOf[DataSetToKafkaEntity])
//构建kafkaProducer广播变量
val kafkaProducer: Broadcast[KafkaSink[String, String]] = {
val kafkaProducerConf = {
val p = new Properties()
val userName=paramEntity.getMqUserName
val password=paramEntity.getMqPassWord
p.setProperty("bootstrap.servers", paramEntity.getMqBrokenIps)
p.setProperty("key.serializer", classOf[StringSerializer].getName)
p.setProperty("value.serializer", classOf[StringSerializer].getName)
p.setProperty("acks","1")
p.setProperty("retries","3")
p.setProperty("security.protocol","SASL_PLAINTEXT")
p.setProperty("sasl.mechanism","SCRAM-SHA-256")
p.setProperty("sasl.jaas.config", "org.apache.kafka.common.security.scram.ScramLoginModule required " +
"username=\"" + userName + "\" password=\"" + password + "\";")
p
}
spark.sparkContext.broadcast(KafkaSink[String, String](kafkaProducerConf))
}
//从dataset取数
val topic = paramEntity.getMqTopic
val sqlLogic = paramEntity.getSqlLogic
val df = spark.sql(sqlLogic).withColumn("taskId",lit(taskId)).toJSON
//写入Kafka
df.foreach(row => {
kafkaProducer.value.send(topic, row)
println("推送完成:" + row)
})
通过使用广播变量,可以将KafkaSink实例在集群中的多个任务中共享,减少了每个任务中创建KafkaSink的开销,提高了效率。