初始神经网络
用一个实际例子来理解神经网络。
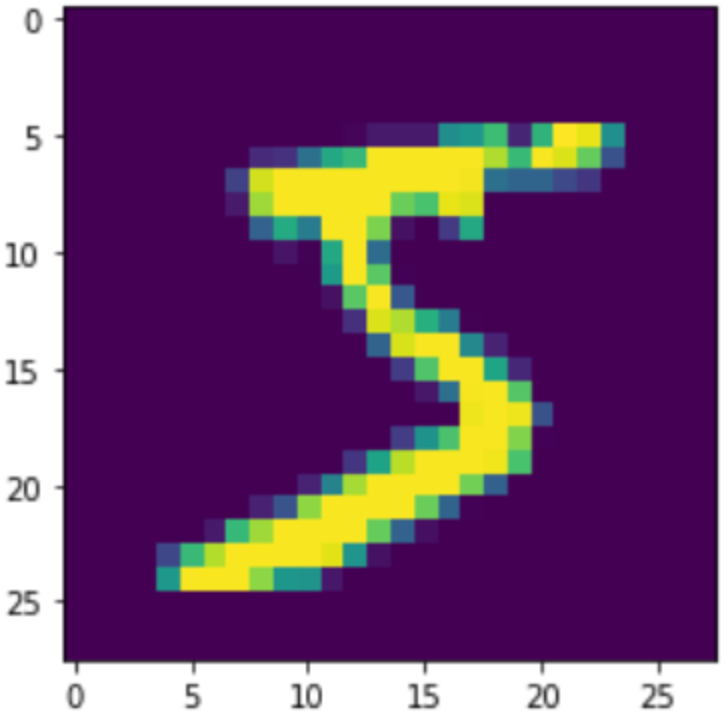
使用MNIST数据集,它就像是深度学习的hello word,包含60000张训练图像和10000张测试图像。
代码地址:
2.2神经网络的数据表示
在例子中,数据存储在多维的NumPy的数组中,也叫做张量(tensor)
标量(0阶张量)
仅包含一个数字的张量叫做标量(scalar)。
如下例子新建一个仅包含一个数组的标量,并查看他的轴(ndim
import numpy as np
x = np.array(12)
x.ndim # 0
向量(1阶张量)
数字组成的数组,叫做向量(vector),也叫一阶张量。
x = np.array([12, 3, 6, 14, 7])
x.ndim # 1
矩阵(2阶张量)
向量组成的二维数组叫做矩阵(matrix),也叫二阶张量。
3阶张量与更高阶张量
将多个矩阵打包到一起,就得到了3阶张量。
将多个3阶张量打包,就的到了4阶张量。用这种方式可以得到更高阶的张量。一般4阶就够用了。处理视频可能需要5阶。
张量的属性
- **轴的个数(阶数):**在NumPy库中对应张量的ndim属性
- **形状:**这是一个由整数组成的元组,表示张量沿每个轴的维度大小(元素个数)。比如一个矩阵的形状是(3,5),表示该矩阵有3行5列。三阶张量(3,3,5)表示由3个3*5的矩阵组成。
- **数据类型:**dtype,一般是float16,float32,float64,unit8等
举例来说:
from tensorflow.keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# 轴的个数,说明训练数据是一个3阶张量
train_images.ndim # 3
# 训练数据的形状 由60000个28*28的矩阵组成
train_images.shape # (60000, 28, 28)
# 训练数据的数据类型
train_images.dtype # dtype('uint8')
操作张量
可以对张量进行切片:
# 张量的切片
my_slice = train_images[10:100]
my_slice.shape # (90, 28, 28)
# 一样的效果,这样写更详细
my_slice = train_images[10:100, :, :]
my_slice = train_images[10:100, 0:28, 0:28]
数据批量
# 分批处理,一般是128,这叫做批量轴
batch = train_images[:128]
batch = train_images[128:256]
n = 3
batch = train_images[128 * n:128 * (n + 1)]
常见张量实例
向量数据:形状是(samples, features)的2阶张量,也就是一维数组。例如:
保险数据集。每个人的年龄,性别,收入对应3个feature,总人数10000,所以最终存储在(10000,3)的2阶张量中。
文档文本数据集。500个文档,记录2000的常用单词出现的次数。最终存储在(500,20000)的2阶张量中。
时间序列数据或序列数据:当时间堆数据很重要时,时间被加入到每个样本的二阶张量中,编译成一个3阶张量。例如:
股票价格数据集。每一分钟,保存股票的当前价格、前一分钟的最高价和最低价。每一分钟是一个3维的向量,一个交易日被编码为(390,3)的矩阵,250天的数据保存在(250,390,3)的3阶张量中。
推文数据集:每条推文280个字符,每个字符来自128个字符的字母表。因此每条推文是一个(290,128)的向量,包含10000条推文的数据集是(10000,290,128)的三阶张量。
图像数据
灰度图像不存在颜色,假如存储100张256x256的图像,灰度图像是(100,256,256,1),彩色图像是(100,256,256,3)
**视频数据:**视频数据由帧组成,(samplse, frames, height, width, color_depth)
例如一个144*256分辨率的60s视频,以每秒4帧计算,共有240帧。存储4个视频片段,保存在形状是(4, 240, 244, 256, 3)的张量中。
2.3张量运算
所有的计算机运算,最终都可以简化为对二进制输入的二进制运算(AND,OR,NOR),与之类似的,深度神经网络的所有变换也可以简化为对数值数据张量进行的张量运算或张量函数,比如张量加法、张量乘法。
# 张量积运算
x = np.random.random((32,))
y = np.random.random((32,))
z = np.dot(x, y)
逐元素运算
目前大多直接借助Numpy的内置方法实现:
# np内置方法,计算一个20*100的矩阵每个元素相加和relu运算耗时
import time
x = np.random.random((20, 100))
y = np.random.random((20, 100))
t0 = time.time()
for _ in range(1000):
z = x + y
z = np.maximum(z, 0.)
print("Took: {0:.2f} s".format(time.time() - t0))
广播
如果两个张量的阶数不一样,较小的张量会被广播。
# 广播
import numpy as np
# x是一个32*10的矩阵
x = np.random.random((32, 10))
# y是一个随机数组,也就是向量
y = np.random.random((10,))
# y的形状变为(1,10)
y = np.expand_dims(y, axis=0)
# 将y沿着新轴重复32次,就的到了和x形状相同的轴
y = np.concatenate([y] * 32, axis=0)
被广播后,y的形状和x一样,就可以进行运算了
实际上该方法也已经内置
import numpy as np
x = np.random.random((64, 3, 32, 10))
y = np.random.random((32, 10))
z = np.maximum(x, y)
张量积
在numpy中,使用np.dot来实现张量积
x = np.random.random((32,))
y = np.random.random((32,))
z = np.dot(x, y)
标量的张量积和矩阵的张量积
张量变形
重新排列张量的行和列,这就是张量的变形。
import numpy as np
# 一个3*2的张量
x = np.array([[0., 1.],
[2., 3.],
[4., 5.]])
x.shape # (3, 2)
# 转换成6*1的张量
x = x.reshape((6, 1))
常见的变形有矩阵的转置,也就是互换矩阵的行和列。
x = np.zeros((300, 20))
x = np.transpose(x)
x.shape # (20, 300)
张量运算的几何解释
平移:2个向量的和,对应了向量在坐标系中的平移相加
旋转:通过与一个2*2的矩阵做点积运算,可以实现对二维向量的逆时针旋转。
缩放:
线性变换:与任意矩阵做点积运算,就进行了一次线性变换。上述缩放和旋转,都是线性变换
深度学习的几何解释
就像把2张揉在一起的纸,重新用手一步步解开的过程。
2.4神经网络的引擎:基于梯度的优化
梯度
什么是梯度(gradient)?我们在数学上学过,函数的导数用来描述在x发生变化时,y的最小变化。张量运算的导数,就是梯度。
举例说明如下:
- 一个输入向量x(数据集中的一个样本)
- 一个矩阵W(模型权重)
- 一个目标值y_true
- 一个损失函数loss
用w可以得出预测值y_pred,然后可以计算损失值,也就是y_pred和y_true之间的差距。
y_pred = dot(W, x)
loss_value = loss(y_pred, y_true)
我们的目标是利用梯度来更新W,使得loss_value变小。
如果输入数据x和y_true保持不变,那么上面的运算可以看做一个将权重W映射到损失值的函数
loss_value = f(W)
f在W0点的导数是一个张量grad(loss_value, W0),每个grad(loss_value, W0)[i,j]表示的是当矩阵W0[i, j]发生变化时loss_value变化的方向和大小。
张量grad(loss_value, W0)就是函数f(W) = loss_value在W0处的梯度。
随机梯度下降
如果一个函数可导,那么我们求出所有导数为0的点, 然后比较f(x)的大小,就能得到函数的最小值。
于此类似,在神经网络中,对grad(f(W), W)=0求解,就可以求出损失函数的最小值。在参数是2个或3个的时候,确实可以这么做。然鹅事实上往往有很多参数,甚至成千上百个参数,这样是无法求解的。
我们可以基于当前在随机数据批量上的损失值,慢慢对参数进行调整:
- 抽取训练样本x和对应目标y_true组成的一个数据批量
- 在x上运行模型,得到预测值y_pred。这叫做前向传播。
- 计算模型在这批数据上的损失值,用于衡量y_pred和y_true之间的差距
- 计算损失相对于模型参数的梯度。这叫做反向传播。
- 将参数沿着梯度的反方向移动一小步。比如W -= learning_rate * gradient。从而是这批数据损失值降低。
以上这种方法,叫做小批量随机梯度下降,简称小批量SGD。随机指的是,每批数据都是随机抽取的。
如果每次只抽取一个样本和目标,这叫做**真SGD;另一个极端是每次迭代都在所有数据上进行,这叫做批量梯度下降。**数据太多的话,计算成本很高;但太少又不够准确。这两个方法的折中,在于选择合适批量大小。
链式求导:反向传播算法
假设有2个函数,f(x)和g(x),如果可以分别求出他们的导数,那么就可以求出他们的复合函数f(g(x))的导数。如果中间函数更多,看起来就像一条链子,这就是链式法则。
将链式法则应用于神经网络梯度值的计算,就得到了反向传播算法。
目前可以使用自动微分的工具来实现反向传播,比如TensorFlow库。
import tensorflow as tf
# 将初始值设置为0
x = tf.Variable(0.)
# 创建一个GradientTape作用域
with tf.GradientTape() as tape:
# 在作用域内,对变量做一些张量运算
y = 2 * x + 3
# 利用梯度带获取输出y相对于变量x的梯度
grad_of_y_wrt_x = tape.gradient(y, x)
例子
现在我们对神经网络有了一个基本的了解,用学到的知识来看一下例子
- 输入数据,数据保存在float32类型的Numpy张量中,形状分别为(6000, 2828)(训练数据)和(10000, 2828)(测试数据)
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype("float32") / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype("float32") / 255
- 生成模型,包含两个链接在一起的Dense层,每层都对输入数据做一些张量运算。
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(512, activation="relu"),
layers.Dense(10, activation="softmax")
])
- 模型编译
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
- 循环训练
model.fit(train_images, train_labels, epochs=5, batch_size=128)
用TensorFlow实现(暂时只需要知道大概流程就行,后面会详细说明
Dense主要实现如下输入变换:
output = activation(dot(W, input) +b)
我们来写一个简单的Dense类
import tensorflow as tf
class NaiveDense:
def __init__(self, input_size, output_size, activation):
self.activation = activation
# 创建一个指定形状的矩阵w,并将其随机初始化
w_shape = (input_size, output_size)
w_initial_value = tf.random.uniform(w_shape, minval=0, maxval=1e-1)
self.W = tf.Variable(w_initial_value)
# 创建一个形状为(output_size,)的零向量b
b_shape = (output_size,)
b_initial_value = tf.zeros(b_shape)
self.b = tf.Variable(b_initial_value)
def __call__(self, inputs):
# 前向传播
return self.activation(tf.matmul(inputs, self.W) + self.b)
@property
def weights(self):
return [self.W, self.b]
通过一个Sequential类,连接这些层
class NaiveSequential:
def __init__(self, layers):
self.layers = layers
def __call__(self, inputs):
x = inputs
for layer in self.layers:
x = layer(x)
return x
@property
def weights(self):
weights = []
for layer in self.layers:
weights += layer.weights
return weights
利用以上两个类,我们可以创建一个类似Keras的模型
model = NaiveSequential([
NaiveDense(input_size=28 * 28, output_size=512, activation=tf.nn.relu),
NaiveDense(input_size=512, output_size=10, activation=tf.nn.softmax)
])
assert len(model.weights) == 4
进行小批量迭代
import math
class BatchGenerator:
def __init__(self, images, labels, batch_size=128):
assert len(images) == len(labels)
self.index = 0
self.images = images
self.labels = labels
self.batch_size = batch_size
self.num_batches = math.ceil(len(images) / batch_size)
def next(self):
images = self.images[self.index : self.index + self.batch_size]
labels = self.labels[self.index : self.index + self.batch_size]
self.index += self.batch_size
return images, labels
完成一次训练
def one_training_step(model, images_batch, labels_batch):
with tf.GradientTape() as tape:
predictions = model(images_batch)
per_sample_losses = tf.keras.losses.sparse_categorical_crossentropy(
labels_batch, predictions)
average_loss = tf.reduce_mean(per_sample_losses)
gradients = tape.gradient(average_loss, model.weights)
update_weights(gradients, model.weights)
return average_loss
from tensorflow.keras import optimizers
optimizer = optimizers.SGD(learning_rate=1e-3)
def update_weights(gradients, weights):
optimizer.apply_gradients(zip(gradients, weights))
一轮训练就是对训练数据的每个批量都重复上述训练步骤,完整的训练循环就是重复多伦训练。
def fit(model, images, labels, epochs, batch_size=128):
for epoch_counter in range(epochs):
print(f"Epoch {epoch_counter}")
batch_generator = BatchGenerator(images, labels)
for batch_counter in range(batch_generator.num_batches):
images_batch, labels_batch = batch_generator.next()
loss = one_training_step(model, images_batch, labels_batch)
if batch_counter % 100 == 0:
print(f"loss at batch {batch_counter}: {loss:.2f}")
from tensorflow.keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype("float32") / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype("float32") / 255
fit(model, train_images, train_labels, epochs=10, batch_size=128)
评估模型
# 评估模型
import numpy as np
predictions = model(test_images)
predictions = predictions.numpy()
predicted_labels = np.argmax(predictions, axis=1)
matches = predicted_labels == test_labels
print(f"accuracy: {matches.mean():.2f}")