引言
这是李宏毅老师深度强化学习视频的学习笔记,主要介绍强化学习的基本概念,从直观的角度去教大家如何理解强化学习的知识而不是理论的角度,所以包含的数学公式不多。
什么是强化学习

我们知道监督学习需要人类给机器一个标签,让机器根据输入去预测这个标签,比如上图中识别是否为猫的例子。虽然监督学习很好用,但是还有很多问题通过监督学习来解决会很复杂。
比如让机器下围棋,甚至当给机器一个输入(现在棋盘的信息)时可能我们人类也不知道最佳的输出(落子位置)是什么,此时就可以考虑使用强化学习(Reinforcement Learning,RL)。虽然我们不知道正确的答案是什么,但机器可以通过与环境互动知道结果的好坏,比如最终导致赢棋了(好)或者棋子被围了(坏),机器可以学出一个模型去学习最终赢棋的走法。
强化学习和机器学习一样,也是想要寻找一个函数。
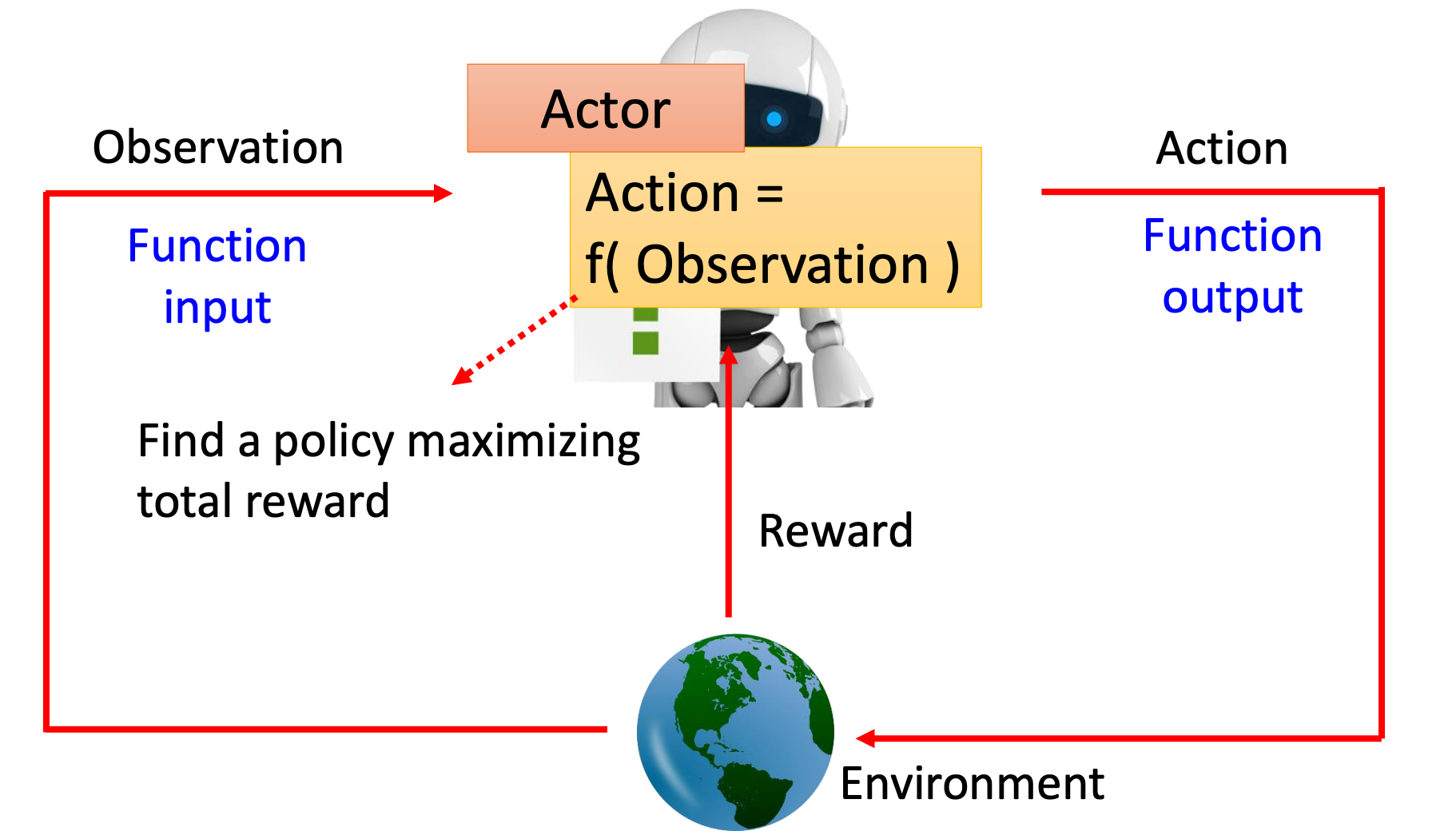
在强化学习中,有一个智能体(Agent,也就是这里的Actor),然后智能体会和环境(Environment)进行互动,环境会给智能体一个观测(Observation,函数的输入)。智能体可以根据这个观测产生一个动作(Action,函数的输出),这个动作反过来也会影响环境,然后环境会给出新的观测,同时也会给出一个奖励(Reward),告诉智能体所采取动作的好坏。智能体看到新的观测后,会继续采取一个新的动作,如此循环往复。
这里的智能体就是我们要找的函数,这个函数的目标是找到一个策略(Policy)去最大化从环境中获取的奖励总和。
这里以让机器(智能体)玩太空侵略者游戏为例,下面是一个游戏屏幕: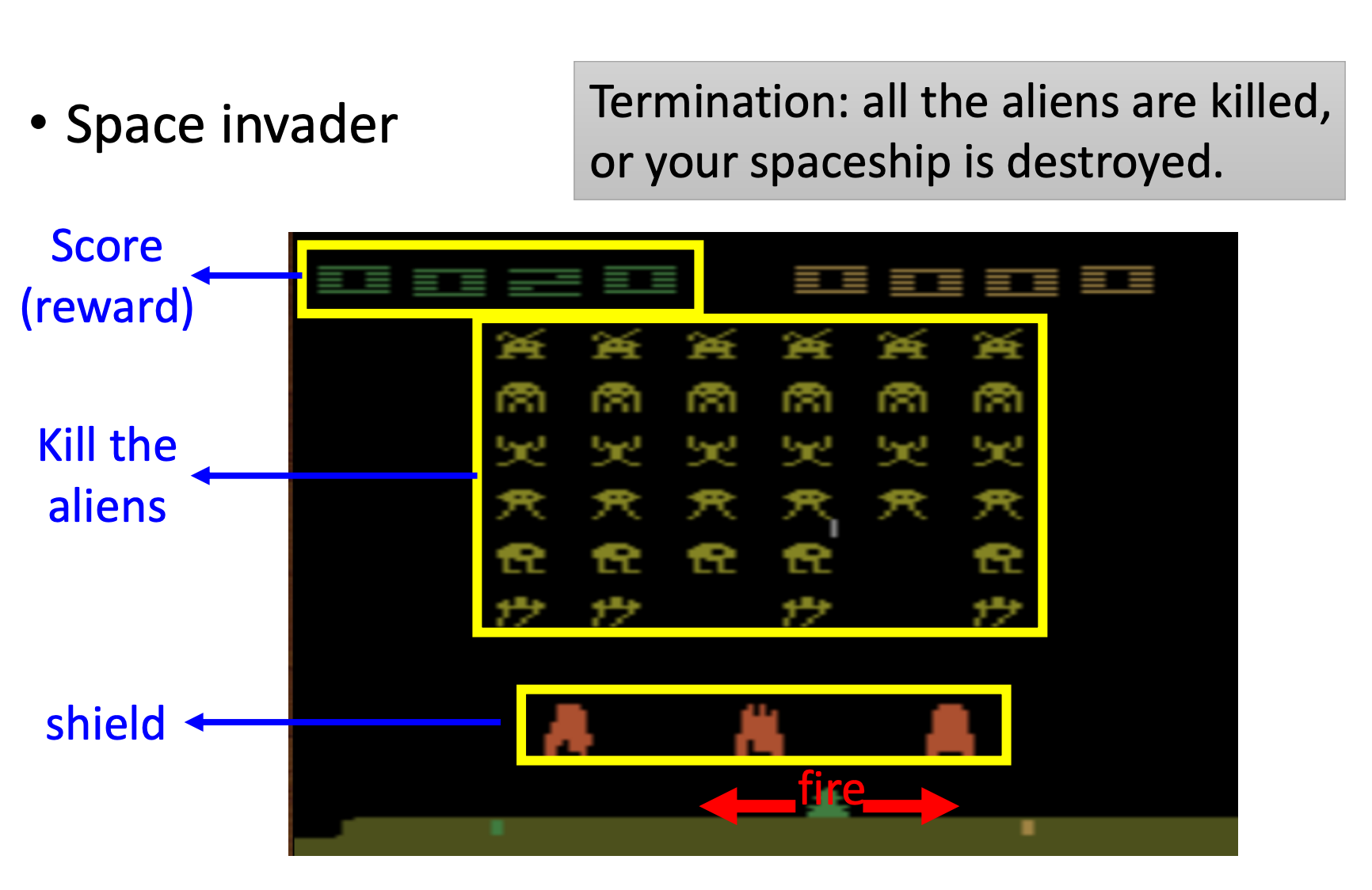 机器可以采取的动作有三个:左移、右移和开火。游戏的目标是通过控制角色(上图最下面绿色部分,一艘飞船)开火杀掉画面中的这些外星人,在绿色飞船前面还有三个防护罩,但是它也可以被自己打掉。
机器可以采取的动作有三个:左移、右移和开火。游戏的目标是通过控制角色(上图最下面绿色部分,一艘飞船)开火杀掉画面中的这些外星人,在绿色飞船前面还有三个防护罩,但是它也可以被自己打掉。
在平面的最上面的数字代表是分数,它是杀死外星人后(环境给)的奖励。
游戏的终止条件为所有的外星人被杀掉或你的飞船被击毁,外星人也会发射子弹,被击中就GG。
这只是一个游戏,没有外星人受到伤害。
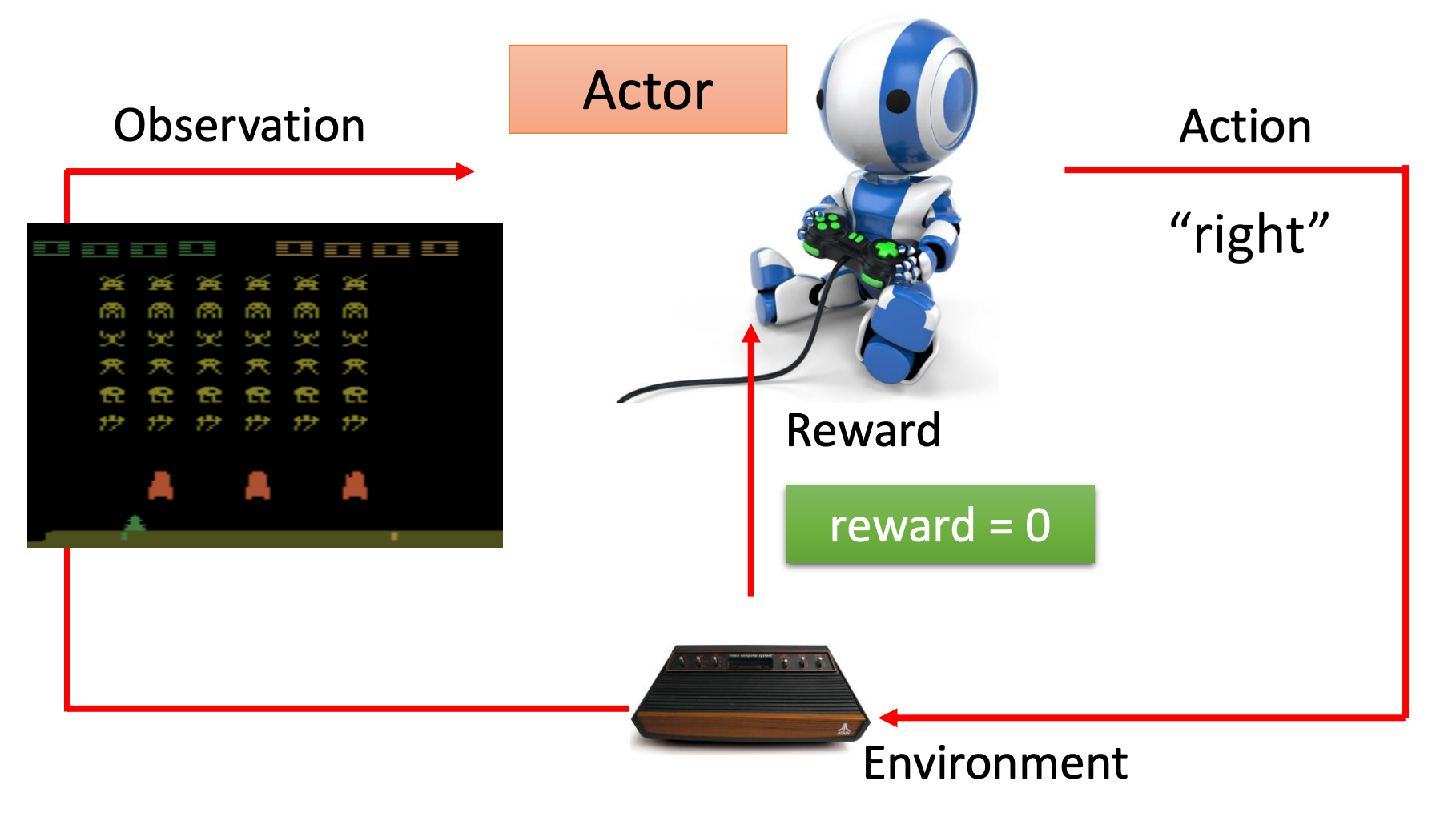
如果要让机器来玩这个游戏,那么通常情况下机器和人类看到的画面是一样的,即它的输入是游戏的一帧画面,环境是游戏的主机,输出是事先定义好可以采取的动作(或者说行为)。
当机器此时选择向右这个动作之后,它会得到奖励值为0,因为我们定义只有击毙外星人才会获得奖励(游戏中也会获得分数)。是的,获取奖励的条件以及多少(正负)是由人类定义的。
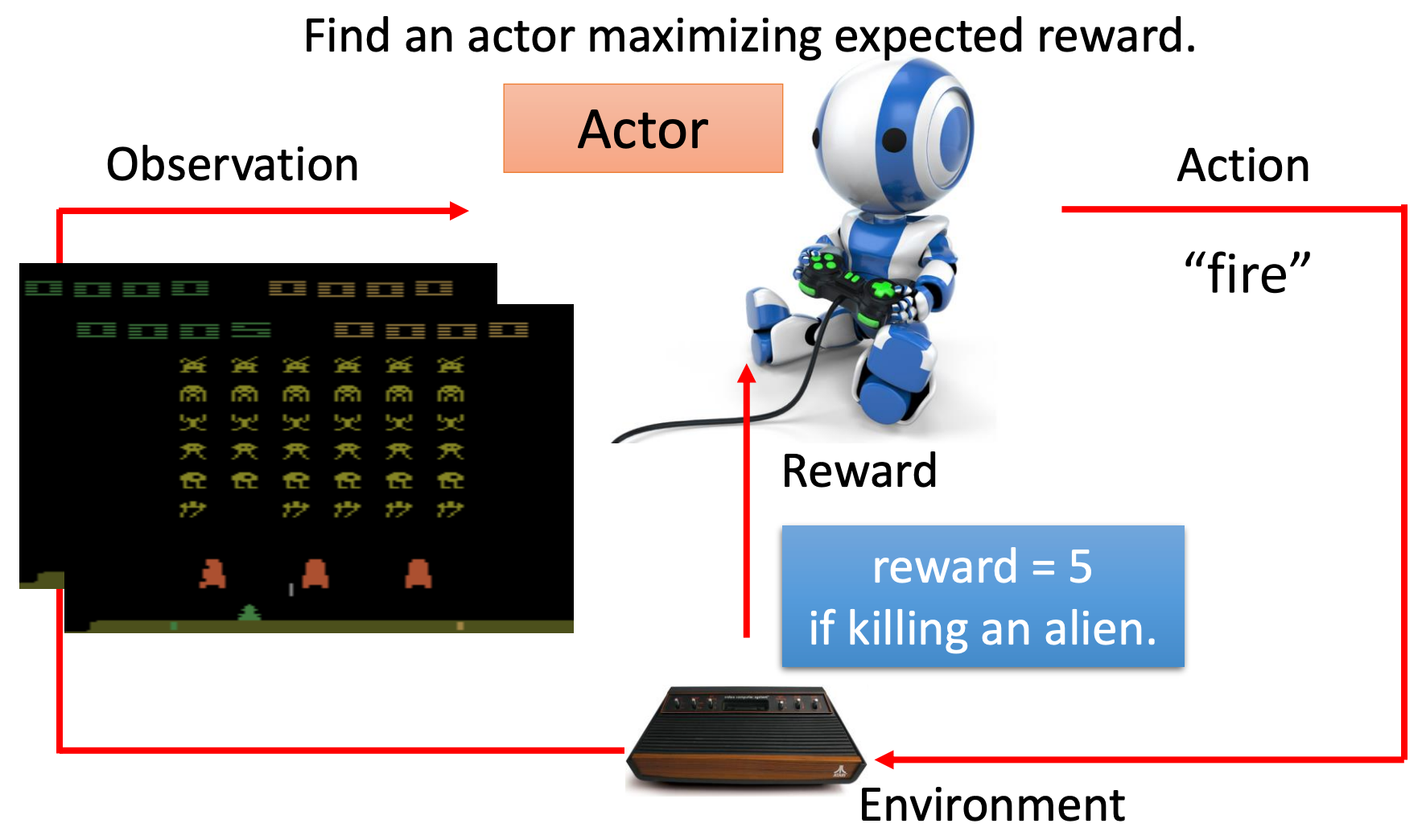
当采取一个动作之后游戏的画面也会发生改变,代表我们有了新的观测。此时智能体可以采取新的动作,假设智能体采取的动作是开火,并且击杀了一个外星人,游戏中得到的分数是5分,这里假设我们也将奖励设为5分。
这样我们在玩游戏的过程中会不断的得到奖励(可能为正、可能为零、还可能为负),只要游戏没有终止。强化学习的目标就是想要找到一个能获取到最大奖励总和的智能体。

同理,回到我们开始下围棋的例子,通过强化学习训练机器人下围棋就和刚才玩游戏的例子很相似。只不过问题的复杂度不一样。
以AlphaGo和李世石下围棋为例,智能体就是AlphaGo,环境是人类对手李世石,智能体的输入是当前的棋盘信息,输出(动作)是下一步落子的位置,然后环境会产生新的观测,智能体又可以输出一个新的动作。
大多数情况下动作所得的奖励都是0,只有当围棋比赛结束时根据输赢来得到+1或-1的奖励。
强化学习和机器学习一样,也只需要三个步骤。
Step 1 定义函数
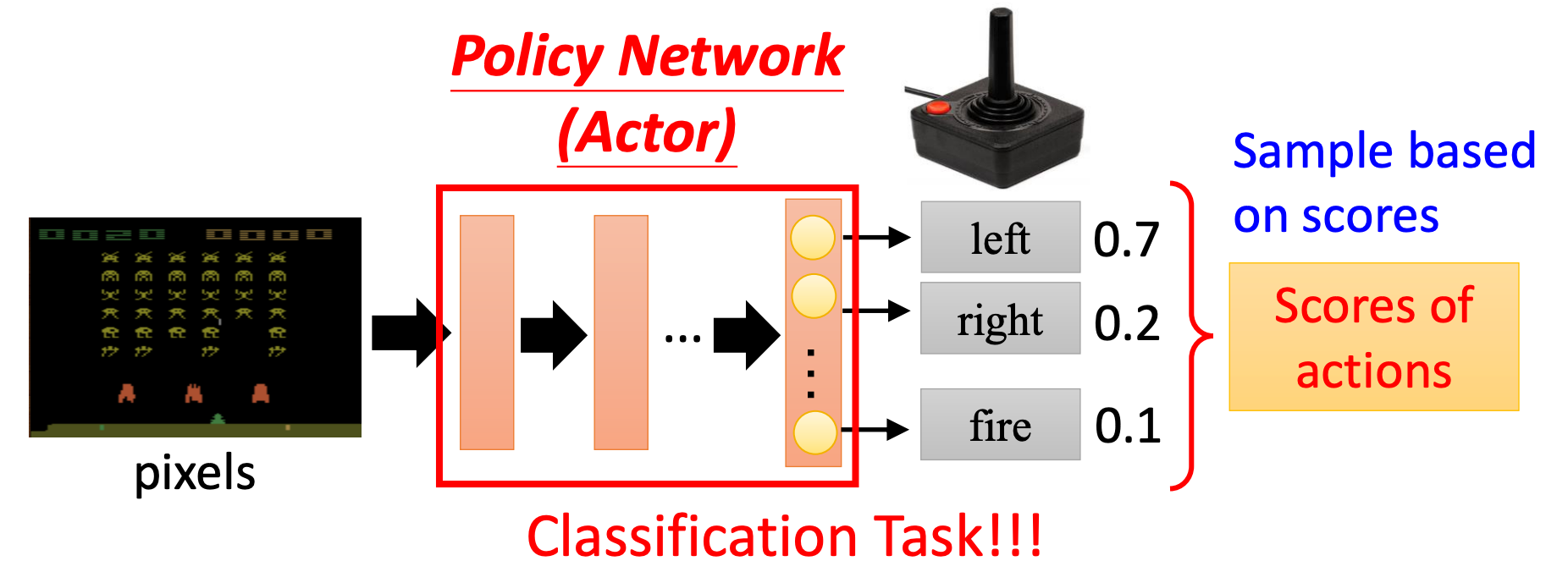
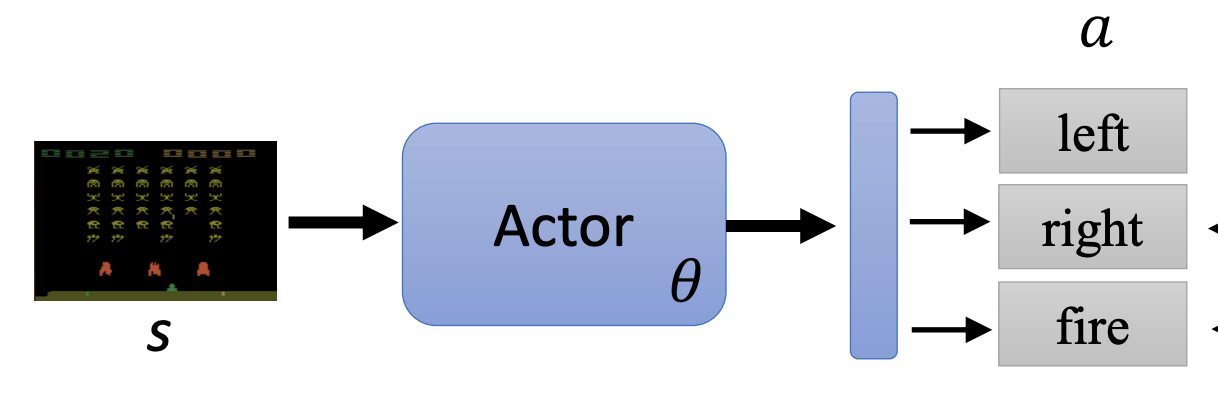
这个函数就是智能体(Actor),它可以通过(策略)网络来拟合,就是一个神经网络。它的输入是游戏的画面,可以用CNN来对画面进行编码。它的输出是可能的动作和对应的(神经网络给的)分数,在上图的例子中输出共有3个,其中left的分数(概率)最大。实际上就是一个分类问题!
具体的网络架构可以自己定义,如果输入是一帧图像的话,那么可能需要用到CNN,甚至还可以不止考虑当前的画面,而是从开始到目前位置所有的画面,那么可以结合RNN或用Transformer来做。
具体采取哪个动作可以将网络输出的分数转换为概率分布(如上图),然后根据这个分布去采样动作。那为什么不直接选择分数最高的动作呢?实际上是为了引入随机性,有时随机性是非常重要的。比如剪刀石头布的游戏,如果你每次选择的动作都是固定的,很容易被对手针对。
有了函数后下一步是定义损失。
Step 定义损失
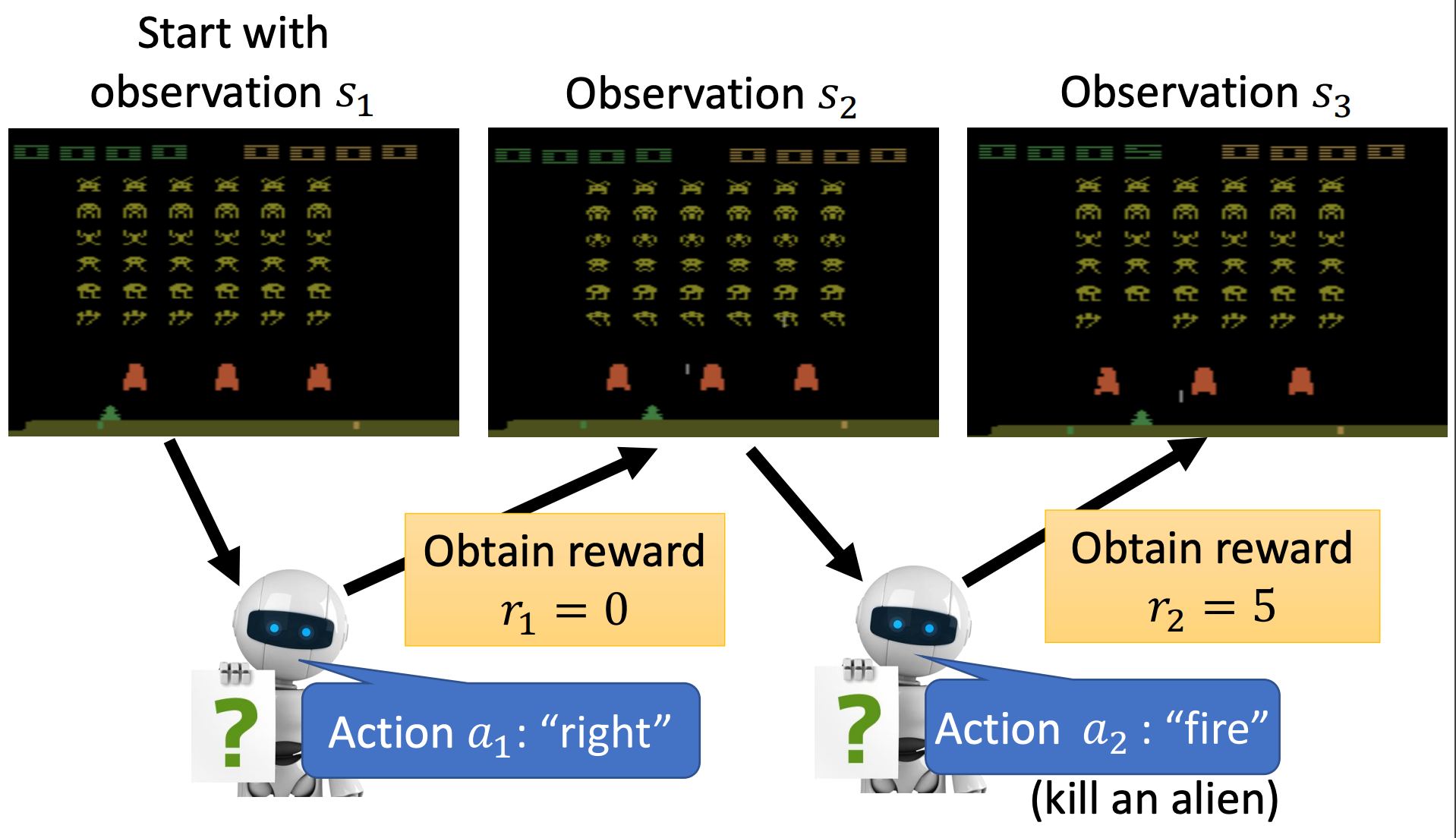
我们先来重新看一下机器和环境互动的过程:
- 有一个初始游戏画面(观测 s 1 s_1 s1),作为智能体的输入,智能体输出了一个动作向右( a 1 a_1 a1)。
- 得到奖励( r 1 = 0 r_1=0 r1=0)并看到了新的游戏画面( s 2 s_2 s2),智能体采取新的动作开火( a 2 a_2 a2),假设恰好击杀了一个外星人。
- 得到奖励( r 2 = 5 r_2=5 r2=5)并看到新的游戏画面( s 3 s_3 s3)…
- 上面三个过程会反复下去,直到游戏结束。
- 可能是飞船被摧毁或者是击毙最后一个外星人。
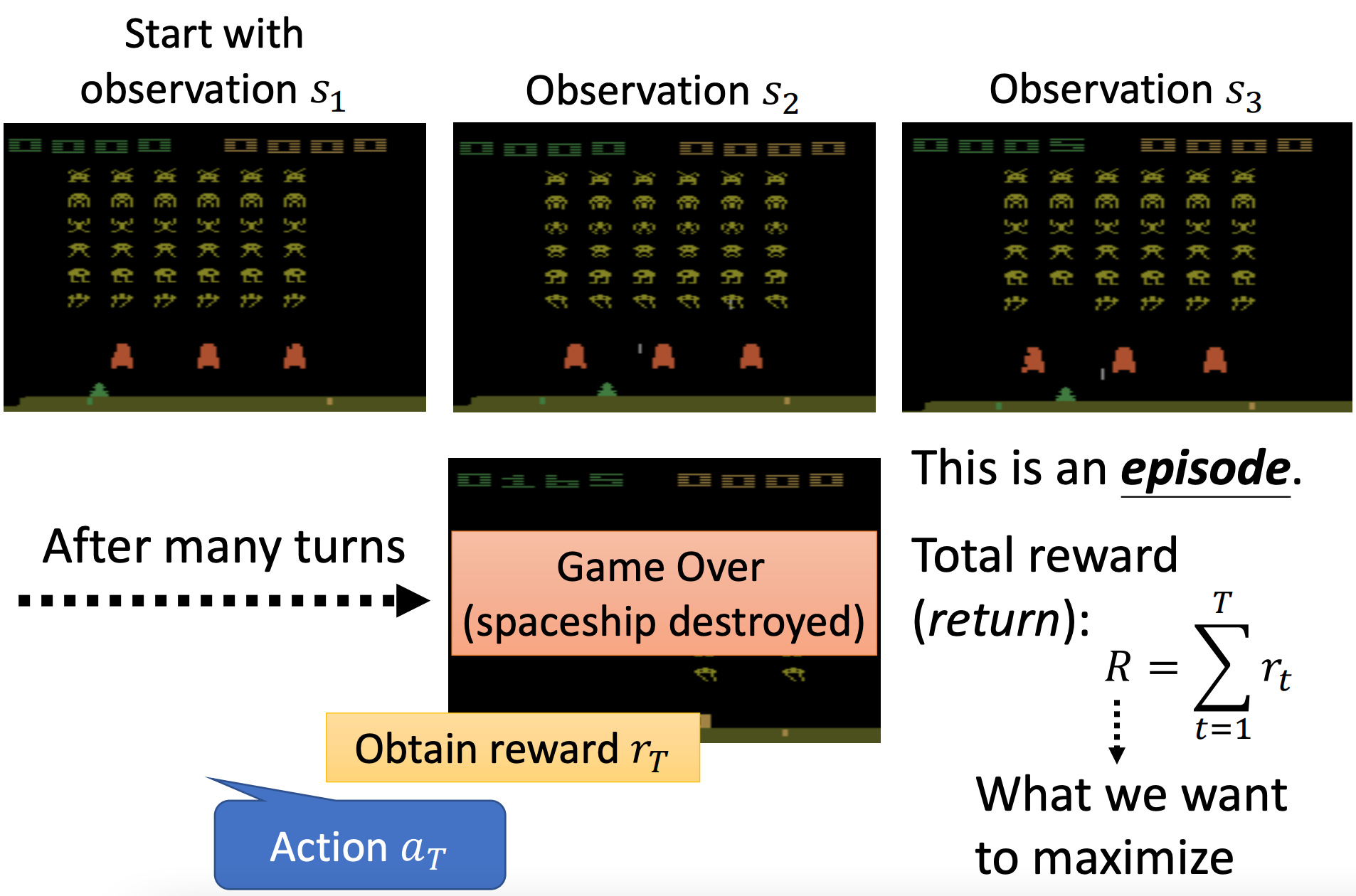
从游戏开始到结束的过程称为一个episode(回合/轮/场);整场游戏得到的奖励总和称为回报(return):
R = ∑ t = 1 T r t R = \sum_{t=1}^T r_t R=t=1∑Trt
注意回报和奖励的区别,智能体采取一个动作后立即得到的是奖励,整场游戏所有的奖励加起来就是回报。
我们的训练目标就是最大化这个回报。
可以把负的回报看成是RL的损失。
优化
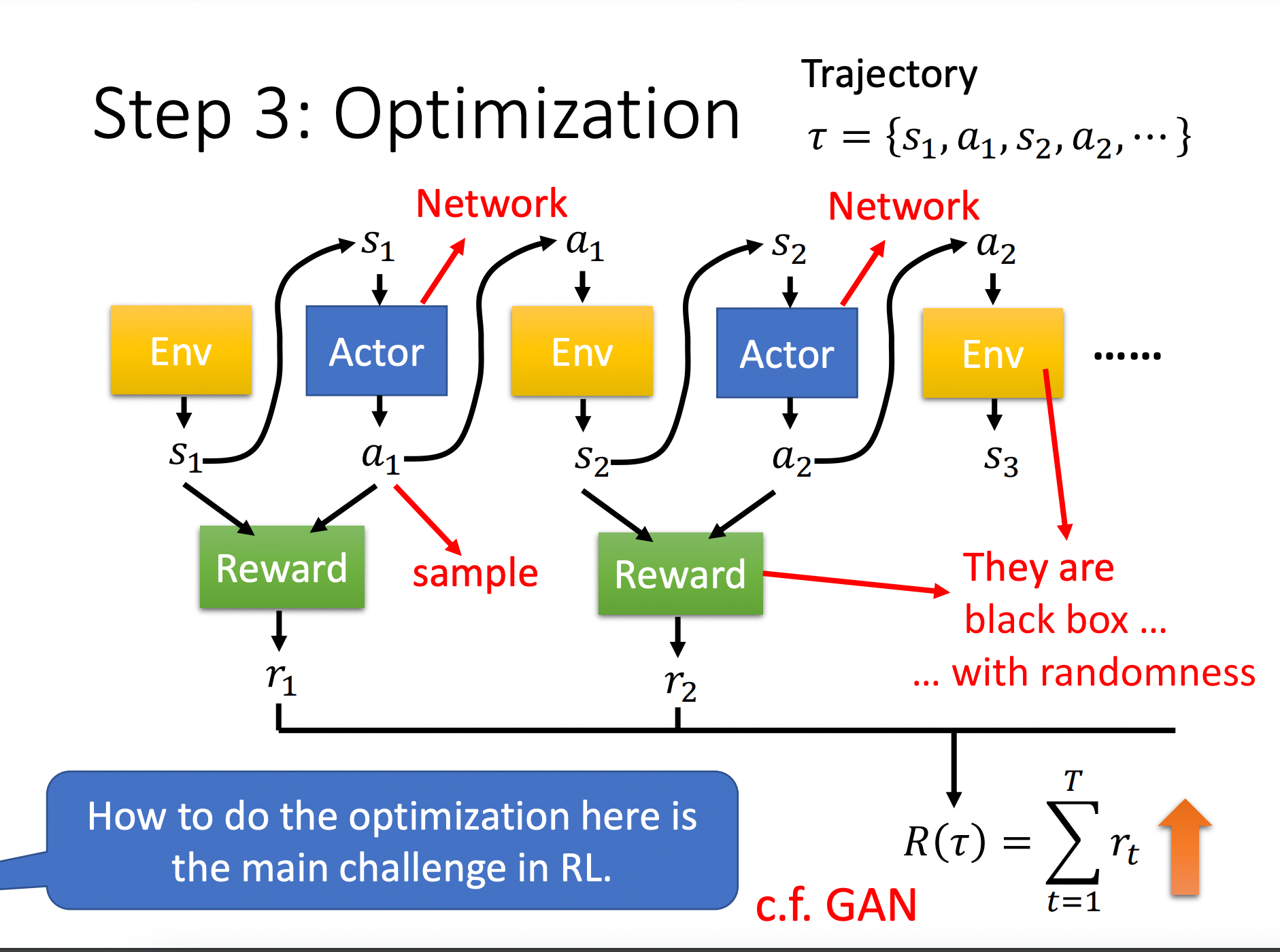
我们从另一个角度来理解以下这个过程。
开始时,智能体(上图蓝色方块)看到环境Env(黄色方块)产生的第一个状态 s 1 s_1 s1,然后它输出动作 a 1 a_1 a1。动作 a 1 a_1 a1变成了环境的输入,环境产生状态 s 2 s_2 s2。以此类推,整个过程会一直进行下去直到满足游戏终止的条件。
所产生的这些状态和动作的序列 τ = { s 1 , a 1 , s 2 , a 2 , ⋯ } \tau = \{s_1,a_1,s_2,a_2,\cdots\} τ={s1,a1,s2,a2,⋯}称为轨迹(Trajectory)。
在智能体和环境互动的过程中,它会得到奖励(绿色方块),它也是一个函数,比如输入 s 1 , a 1 s_1,a_1 s1,a1会输出奖励 r 1 r_1 r1;输入 s 2 , a 2 s_2,a_2 s2,a2会输出奖励 r 2 r_2 r2。
对所有的这些奖励求和就得到了上面介绍的回报。
那么可以这么思考这个优化问题,我们需要找到一组网络(代表智能体)的参数,它能最大化这个回报。
强化学习是很难训练的,在于:
- 智能体网络的输出(动作)带有随机性(一般是通过采样产生动作);
- 环境一般是黑盒子,我们无法知道环境改变状态的原理;
- 如果环境是确定的、已知的,那么就不需要强化学习来解决它了。
- 奖励机制其实就是一套规则,也不是网络;
- 环境和奖励也具有随机性;
因此常规的机器学习算法(梯度下降)是很难求解RL问题的。
下面我们来看如何求解RL问题的算法,即策略梯度。首先从考虑如何控制你的智能体开始。
如何控制你的智能体
首先我们来思考一个问题,当智能体(也就是这里的Actor,我们用网络来拟合)看到某个状态 S S S,我们如何控制它采取什么样的动作呢?

假设此时状态 S S S对应的正确动作为Left,那么借鉴监督学习的思想,我们把动作转换为one-hot向量,然后通过交叉熵来优化这个网络的参数 θ \theta θ。
如果我们想要智能体不要采取某个动作,那么可以在交叉熵前面加个负号(定义为损失),即交叉熵越小反而损失越大,来阻止智能体采取某个动作。
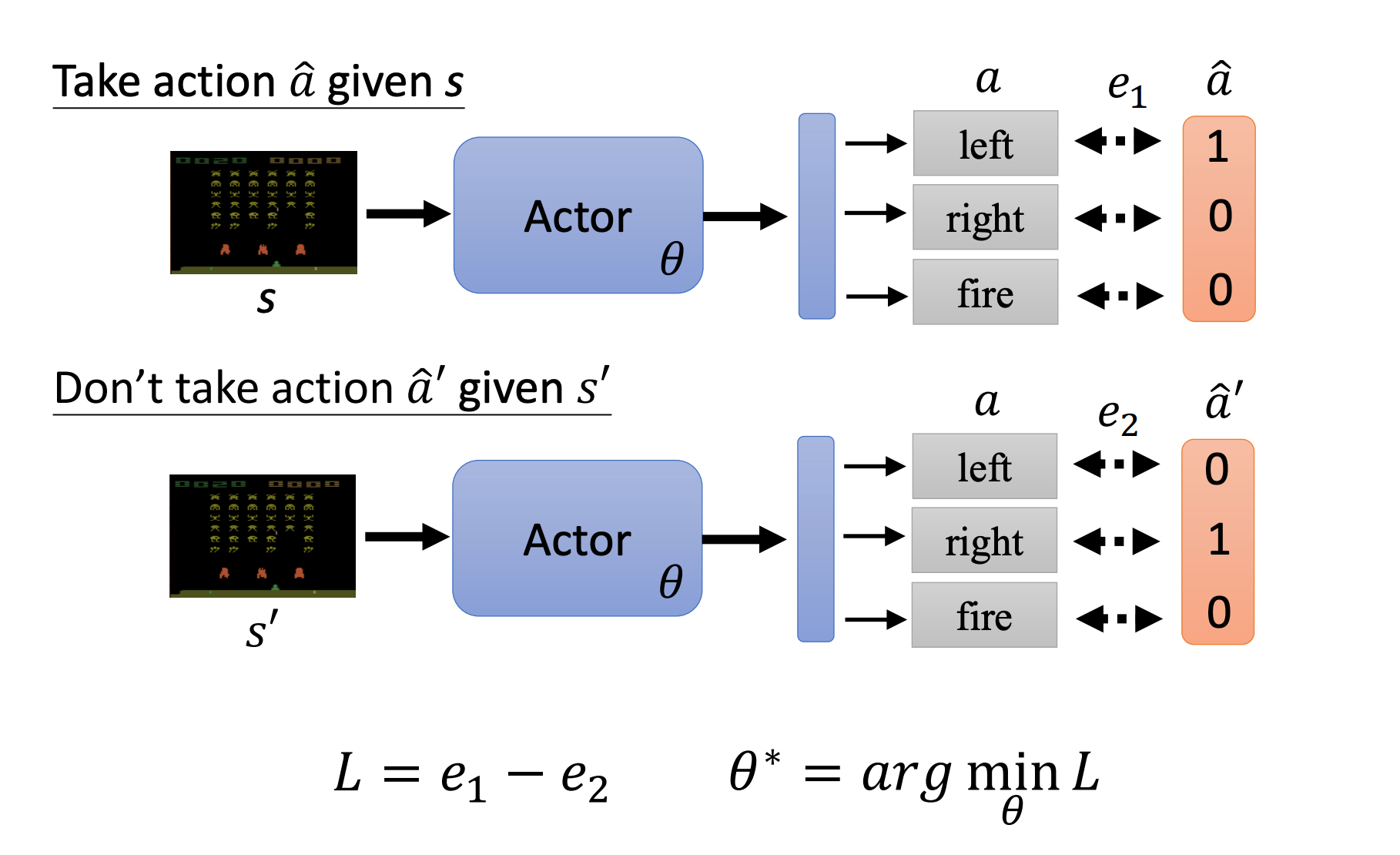
如果想要智能体在看到 s s s的时候采取 a ^ \hat a a^,看到 s ′ s^\prime s′时不需要采取 a ^ ′ \hat a^\prime a^′
即前者的交叉熵为 e 1 e_1 e1,后者的交叉熵为 e 2 e_2 e2,那么我们改变后者的符号后把它们加起来得到两件事一起的损失: L = e 1 − e 2 L=e_1 - e_2 L=e1−e2。
然后找到一组参数来最小化这个损失 L L L即可。
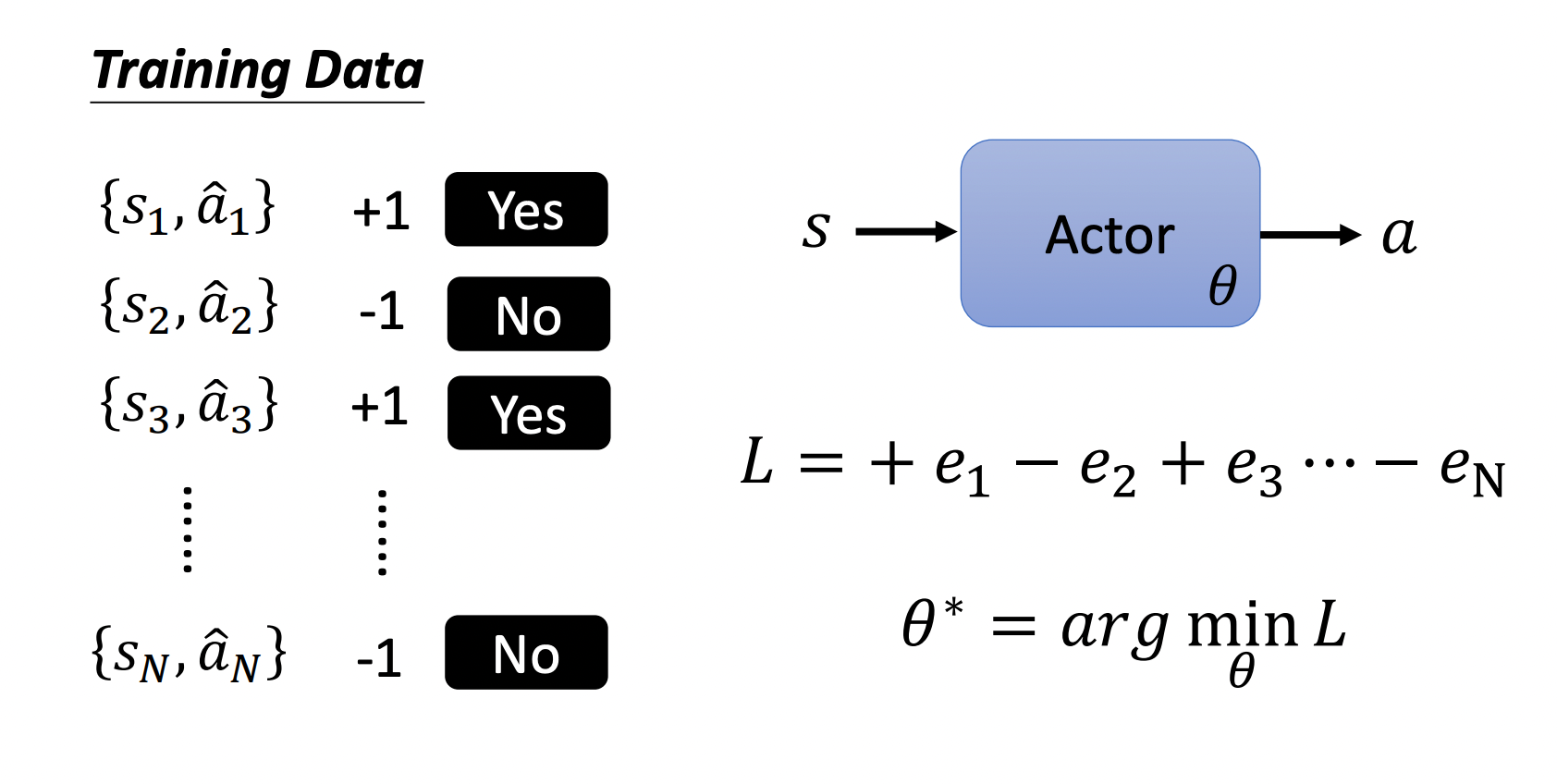
所以要训练一个智能体,我们需要收集一些训练数据,如果希望在某个状态下采取某个动作则给它一个正的符号 + 1 +1 +1;如果不希望采取某个动作则给个负符号 − 1 -1 −1。
分别计算这些样本对应的交叉熵,并乘上对应的符号,最后全部加起来就是我们的损失 L L L,训练的目标是最下化这个损失 L L L。
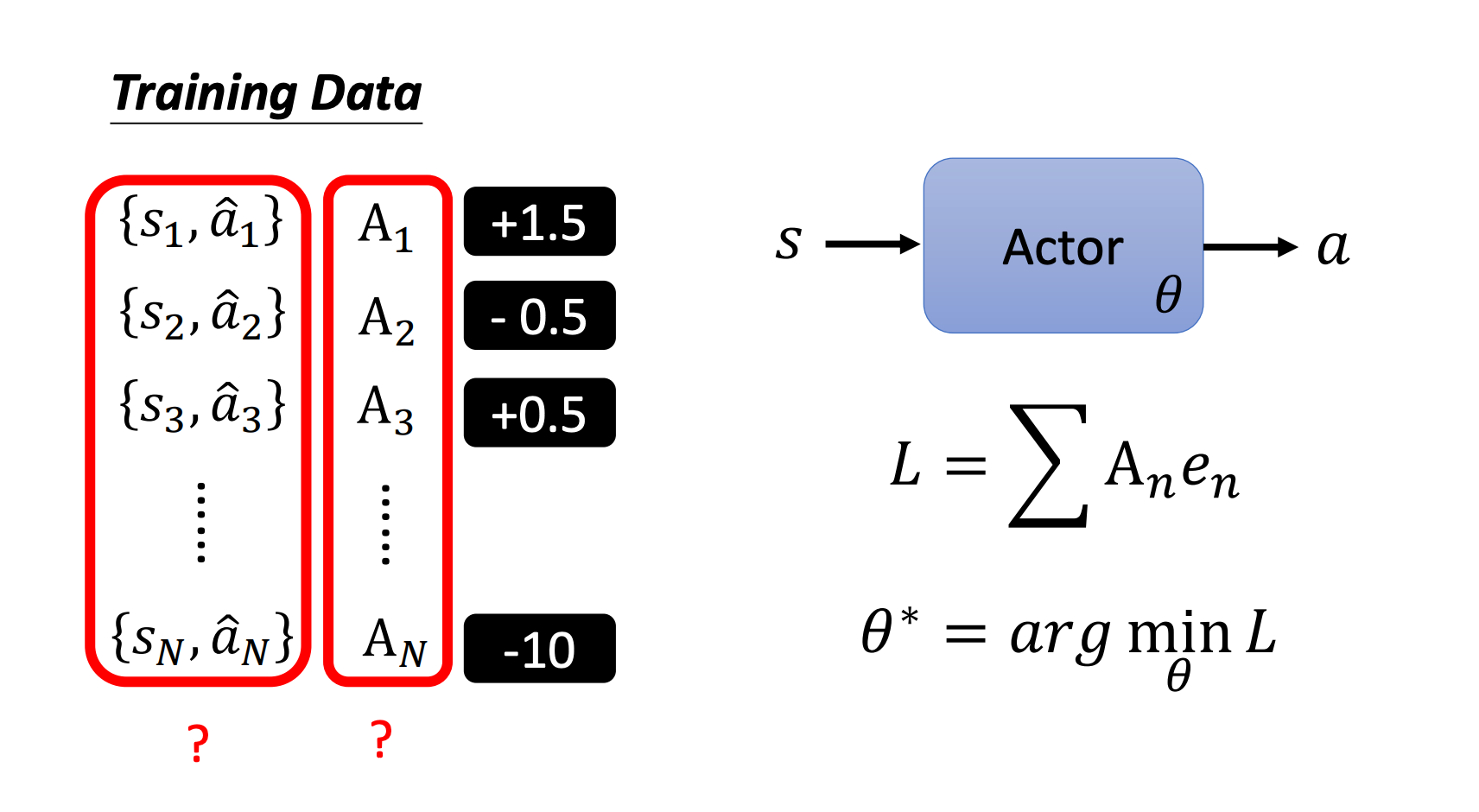
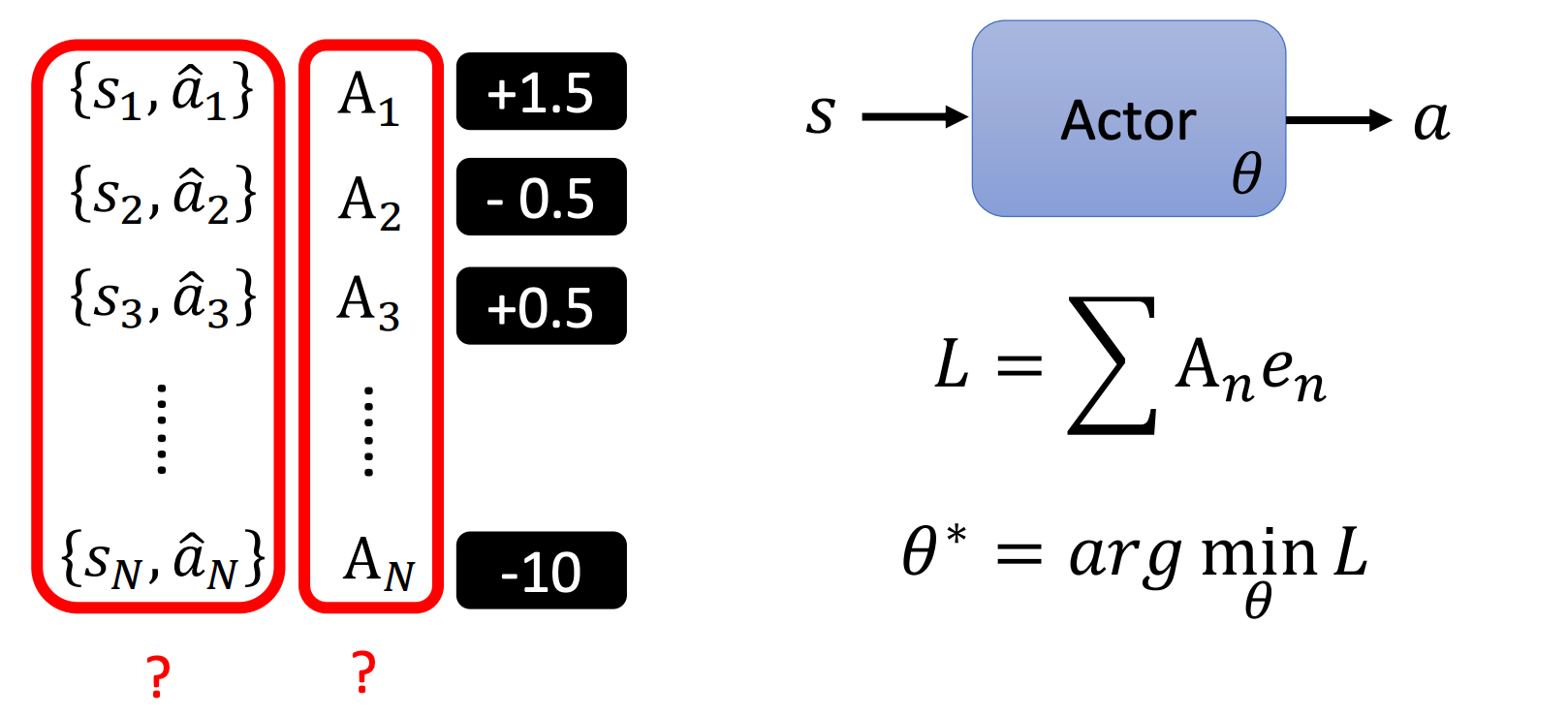
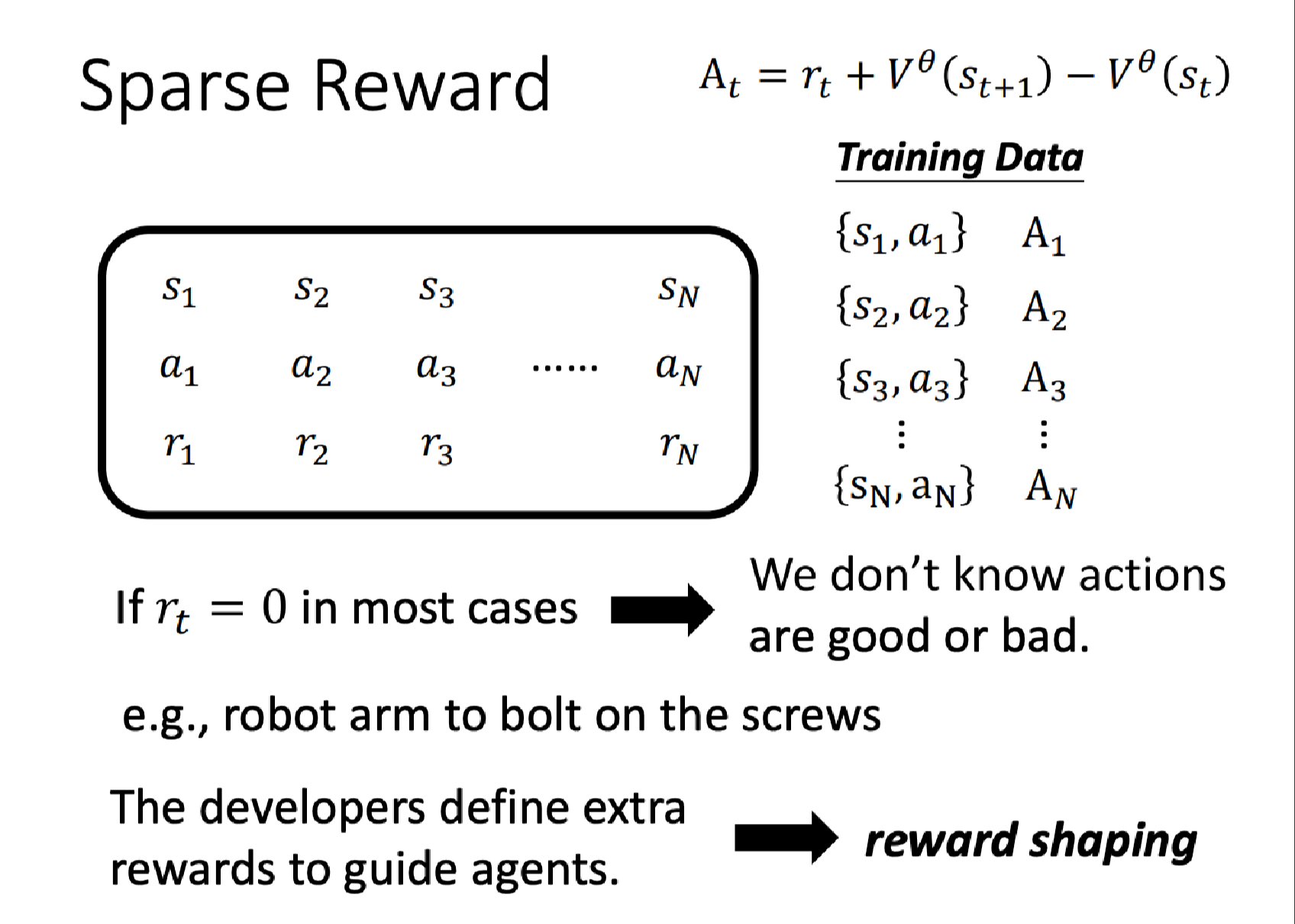
我们还可以更进一步,每个动作不止是好或不好(想要执行/不想执行),改成每个状态和动作对有一个对应的分数,这个分数代表我们多希望智能体在看到这个状态的时候执行对应的动作。
比如 { s 1 , a ^ 1 } \{s_1,\hat a_1\} {s1,a^1}对应的分数为 1.5 1.5 1.5,我们就比较希望智能体在看到 s 1 s_1 s1的时候执行动作 a ^ 1 \hat a_1 a^1。
对于这 N N N个样本,我们分别用 A 1 , ⋯ , A N A_1,\cdots,A_N A1,⋯,AN来表示它们对应的分数,那么损失可以定义为:
L = ∑ A n e n L = \sum A_n e_n L=∑Anen
这里的 e e e表示交叉熵,我们的目标是找到 θ ∗ = arg min θ L \theta^* = \arg \min_\theta L θ∗=argminθL
那么此时有两个问题:
- 如何定义这些分数
- 如何采样这些状态和动作对
(且听下文分解)




![[PyTorch][chapter 2][<span style='color:red;'>李</span><span style='color:red;'>宏</span><span style='color:red;'>毅</span><span style='color:red;'>深度</span><span style='color:red;'>学习</span>-Regression]](https://img-blog.csdnimg.cn/8fb0d0058b864981becfb8399072d552.png)
















![[GYCTF2020]Ezsqli ---不会编程的崽](https://img-blog.csdnimg.cn/direct/f25c85b6340e4f94b931b8bf2213c7c7.png)