数字化时代,大数据信息的收集和应用逐步普及,离不开网络爬虫的广泛应用。由于数据和信息市场的不断扩大,需要大规模的网络爬虫来应对大规模的数据信息采集。在此过程中需要注意哪些问题?
1、先检查是否有API,API是网站提供官方数据信息的接口。主流电商平台API接口数据采集,注册KEY测试。
如通过调用API收集数据信息,在网站允许的范围内收集数据,既不存在道德法律风险,也不存在故意设置网站的障碍;但调用API界面的访问受网站的控制,网站可用于收费和限制访问上限。二、数据信息的结构分析与数据信息存储。
2、Web爬行器需要特别清楚地显示哪些字段是需要的。
字段可以在网页上存在,也可以基于网页中现有字段进行进一步计算。以下是如何生成表格,如何连接多个表格,等等。需要注意的是,确定字段链接时,不要只看一小部分的网页,因为一个网页可能会缺少其他类网页的字段,这可能是由于网站的问题,也可能是由于用户行为的不同,只有更多地浏览一些网页,才能综合提取关键字段。
对大型的网络爬虫来说,除了要收集数据信息之外,还要存储其它重要的中间数据信息(如网页ID或url),以免每次都重新抓取id。
3、数据流量分析。
如果页面要进行批量爬行,请看其入口的位置,这是基于采集范围而定的。站点页面一般是以树型结构为主,可以以根节点为切入点,逐层进入。识别出信息流的机制后,下一个单独的网页,然后把这个模式复制到整个页面。
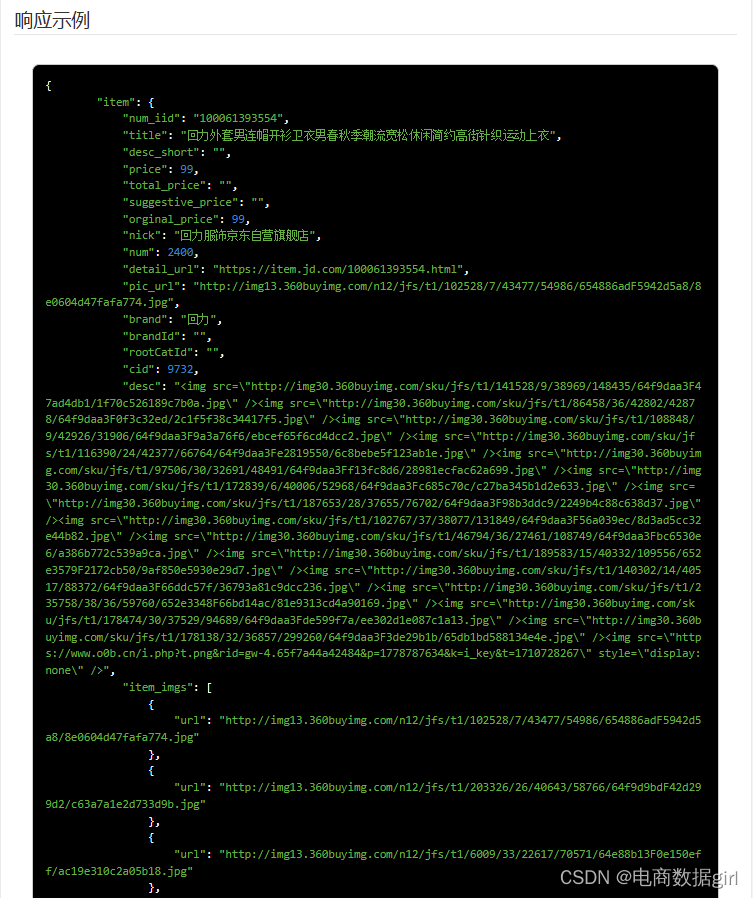
京东获得JD商品详情 API 返回值说明
公共参数
| 名称 | 类型 | 必须 | 描述 |
|---|---|---|---|
| key | String | 是 | 调用key(必须以GET方式拼接在URL中) |
| secret | String | 是 | 调用密钥 |
| api_name | String | 是 | API接口名称(包括在请求地址中)[item_search,item_get,item_search_shop等] |
| cache | String | 否 | [yes,no]默认yes,将调用缓存的数据,速度比较快 |
| result_type | String | 否 | [json,jsonu,xml,serialize,var_export]返回数据格式,默认为json,jsonu输出的内容中文可以直接阅读 |
| lang | String | 否 | [cn,en,ru]翻译语言,默认cn简体中文 |
| version | String | 否 | API版本 |
请求参数
请求参数:num_iid=10335871600
参数说明:num_iid:JD商品ID
响应参数
Version: Date:
| 名称 | 类型 | 必须 | 示例值 | 描述 |
|---|---|---|---|---|
item |
item[] | 0 | 获得JD商品详情 |


























![[python]bar_chart_race绘制动态条形图](https://img-blog.csdnimg.cn/img_convert/bcf7fcee63853f021a49bbf3d4f30b7c.png)