ConcurrentHashMap原理深度解析
文章目录
前言
在Java中,ConcurrentHashMap(简称CHM)是一个线程安全的哈希表实现,它支持高并发场景下的读写操作。与HashMap和Hashtable不同,ConcurrentHashMap在设计和实现上做了大量的优化,以便于在保证线程安全的前提下提供更高的吞吐量和更低的延迟。本文将详细解析ConcurrentHashMap的原理、线程安全性的实现方式、扩容机制以及为什么选择这样的扩容策略,并结合源代码进行说明。本文基于jdk1.8的源码作为示例。
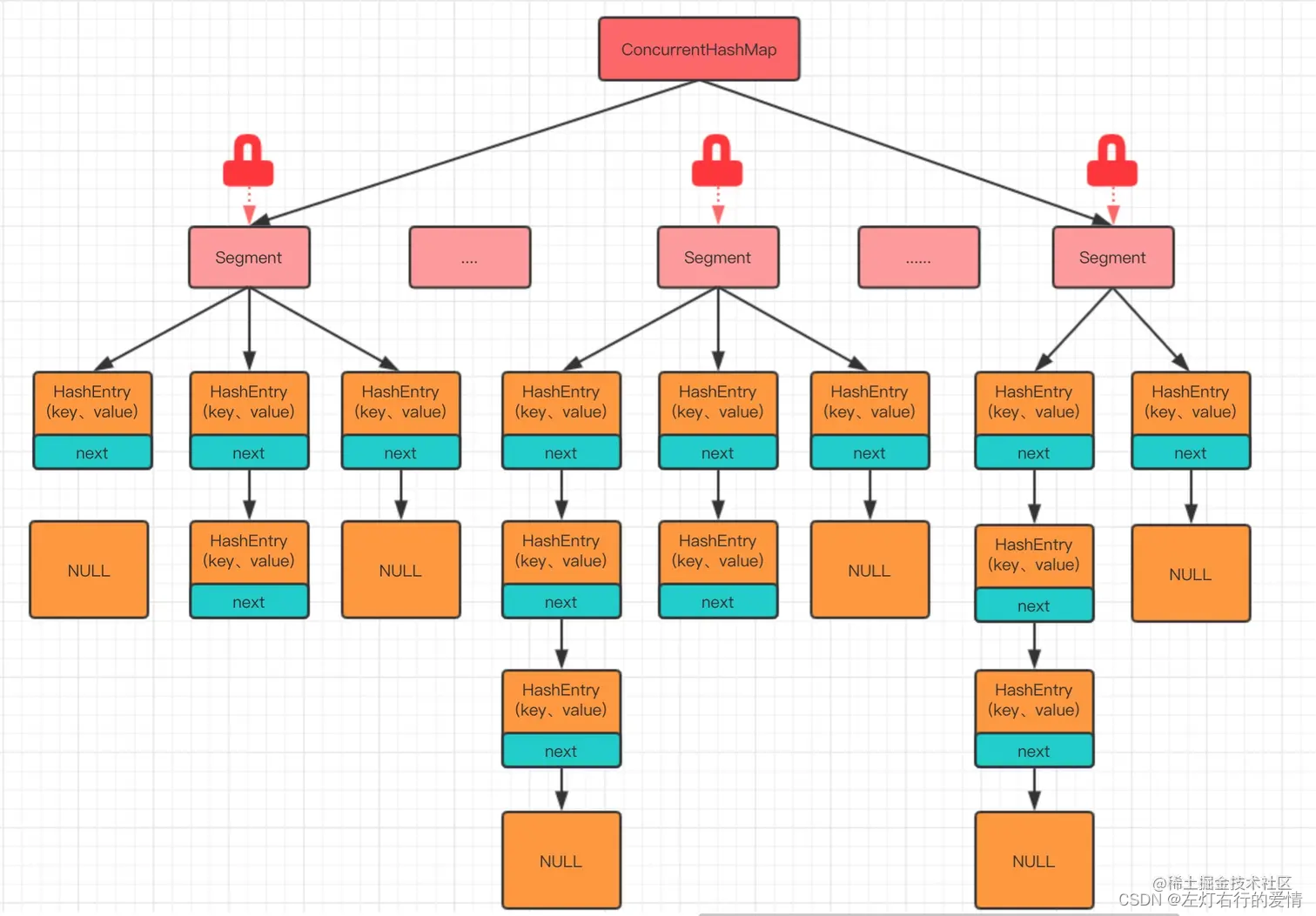
一、数据结构
ConcurrentHashMap内部将数据划分为多个段(Segment),每个段实际上是一个小的哈希表。在JDK 1.8及之后的版本中,这种分段锁的机制被移除,转而采用了一种基于Node数组、CAS操作和精细化的同步控制来实现线程安全。每个Node节点可能是链表或红黑树的节点,当链表长度过长时,会转换为红黑树以提高查询效率。
二、线程安全性的实现
1. Node数组
ConcurrentHashMap内部维护了一个Node数组,数组的每个位置称为一个桶(Bucket)。每个Node节点保存了键值对信息以及指向下一个节点的引用。
涉及源代码如下,Node是一个静态内部类,其中next字段存储的就是指向下一个节点的引用;table是Node数组的定义,存储map中的数据。
//node数组的定义
transient volatile Node<K,V>[] table;
//Node类的定义
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return val; }
public final int hashCode() { return key.hashCode() ^ val.hashCode(); }
public final String toString(){ return key + "=" + val; }
public final V setValue(V value) {
throw new UnsupportedOperationException();
}
public final boolean equals(Object o) {
Object k, v, u; Map.Entry<?,?> e;
return ((o instanceof Map.Entry) &&
(k = (e = (Map.Entry<?,?>)o).getKey()) != null &&
(v = e.getValue()) != null &&
(k == key || k.equals(key)) &&
(v == (u = val) || v.equals(u)));
}
/**
* Virtualized support for map.get(); overridden in subclasses.
*/
Node<K,V> find(int h, Object k) {
Node<K,V> e = this;
if (k != null) {
do {
K ek;
if (e.hash == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
} while ((e = e.next) != null);
}
return null;
}
}
2. 精细化的同步控制:
ConcurrentHashMap的线程安全策略是尽量减少锁的粒度,避免不必要的锁竞争,所以使用了精细化的同步控制来确保线程安全。例如,在添加、删除和更新节点时,它会使用锁或其他同步机制来确保操作的原子性。同时它只对某个桶进行加锁,而不是对整个哈希表加锁,这样多个线程可以并发地操作不同的桶,从而实现高效的并发性能。
1) CAS操作:
ConcurrentHashMap大量使用了Unsafe 类提供的CAS(Compare-and-Swap)操作来确保线程安全。CAS是一种无锁技术,它包含三个操作数——内存位置(V)、期望的原值(A)和新值(B)。当内存位置V的值等于A时,将V的值设置为B。否则,不执行任何操作。整个比较并替换的操作是一个原子操作。
涉及的相关代码如下,目前源码中不止示例代码,还有多处使用这个方式去处理。
// 引入Unsafe
private static final sun.misc.Unsafe U;
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}

2)Synchronized锁:
虽然ConcurrentHashMap主要依赖CAS实现无锁操作,但在某些关键路径上仍然使用了synchronized锁来保证操作的原子性。特别是在扩容和节点转移的过程中,会用到synchronized来确保线程安全。
源码解析略,看第三点。
3)精确控制相关解析的源码
下面代码是ConcurrentHashMap中的putVal的源码,在第一个循环中定义了一个Node<K,V> f,这个就是每一个节点的局部变量的引用,也就是每个桶,同时这个putVal方法中的if逻辑中四个节点都针对各自的情况做了不同的控制,前三个逻辑分支都是使用的unsafe提供的cas相关的方法来确保操作的原子性,然后像第四点的else中则是使用synchronized关键字来加锁,锁的则是单个的Node,没有针对整个hash表加锁,这样子就使得可以多个线程同时操作同一个ConcurrentHashMap对象中不同Node下的数据。
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
三、扩容机制
1. 扩容时机:
当ConcurrentHashMap中的元素数量超过当前数组长度的某个阈值(默认是数组长度的0.75倍)时,会触发扩容操作。扩容的目的是为了减少哈希冲突,提高查询效率。
添加元素时会判断是否需要扩容,主要可以查看这几个方法initTable、tryPresize、transfer等几个方法,主要的扩容逻辑就在resize方法中。
2. 扩容过程:
下面是高度简化后的resize扩容代码, JDK 1.8 的核心逻辑是创建新的哈希表,并将旧哈希表中的元素复制到新哈希表中(源代码中主要涉及tryPresize、transfer两个方法)。由于 ConcurrentHashMap 在 JDK 1.8 中进行了大量的优化,尤其是引入了红黑树来优化长链表的性能,因此 resize 方法也会涉及到红黑树的拆分与复制。
真实的 JDK 源代码会更加复杂,并包含更多的优化和错误处理。但是,它提供了对 resize 方法核心逻辑的一个大致了解:
- 尝试扩展:首先,方法会检查当前哈希表的大小。如果大小小于或等于64,它会尝试通过attemptExpansion方法进行扩展。这个扩展过程可能涉及到与其他线程的协调,以确保在并发环境下的线程安全。
- 创建新表:如果扩展成功或当前表的大小已经足够大,方法会创建一个新的哈希表,其大小是原表大小的两倍。这是为了应对未来可能的插入操作,同时减少哈希冲突,提高查找效率。
- 遍历旧表:接着,方法会遍历旧哈希表的每一个位置。对于每个位置上的节点,它会检查节点的类型。
- 处理树节点:如果节点是一个树节点(即由于链表过长而转换成的红黑树),方法会锁定这个树节点,并对其进行分裂。分裂后的两个子树会分别被放入新哈希表的对应位置。这种锁定和分裂的操作是为了确保在并发环境下对树结构的安全操作。
- 处理链表节点:如果节点是一个链表节点,方法会将其拆分为两个链表。一个链表包含原索引的节点,另一个链表包含原索引加上原表大小(n)的节点。这两个链表随后会被分别放入新哈希表的对应位置。
- 更新表格:完成所有节点的迁移后,方法会将新创建的哈希表设置为当前表,这样后续的插入、删除和查找操作都会在这个新表上进行。
- 更新控制参数:最后,方法会更新sizeCtl的值。这个值用于控制哈希表的扩容和可能的收缩行为,通常基于当前表的大小和加载因子来计算。
private final void resize() {
try {
// 获取当前表
Node<K,V>[] tab = table;
int n = tab.length;
if (n <= 64) {
// 尝试进行表格扩展,如果当前表的大小小于等于64,则通过CAS操作增加sizeCtl中的扩展标记
if (attemptExpansion(n) < 0)
return;
}
// 创建新的哈希表
Node<K,V>[] newTab = (Node<K,V>[])new Node<?,?>[n << 1];
// 复制元素到新表
int nh = 0;
for (int j = 0; j < n; ++j) {
Node<K,V> e;
if ((e = tabAt(tab, j)) == null)
continue;
if (e.hash == null) {
// 如果当前位置是树节点
TreeNode<K,V> p = (TreeNode<K,V>)e;
do {
TreeNode<K,V> q;
int ph;
if ((ph = p.hash) == MOVED) {
// 如果树节点已经在移动过程中,则跳过
j = (ph >>> 16) - 1;
continue;
}
else if (p.prev == null) {
// 锁定树节点并分裂
p.lock();
try {
// ... 分裂树的代码 ...
} finally {
p.unlock();
}
}
else {
// ... 辅助分裂树的代码 ...
}
} while ((p = (TreeNode<K,V>)p.next) != null);
}
else {
// 如果当前位置是链表节点
do {
Node<K,V> next = e.next;
if (next == null)
break;
if (e.hash == MOVED) {
// 如果链表节点已经在移动过程中,则跳过
j = (e.hash & HASH_BITS) - 1;
continue;
}
// 尝试将链表节点转移到新表
int rs = resizeStamp(n);
if (e.next == null) {
// 链表只有一个节点,直接复制
synchronized (e) {
if (tabAt(tab, j) == e) {
setTabAt(newTab, j, e);
setTabAt(newTab, j + n, null);
nh++;
}
}
}
else if (e.hash >= 0 &&
(rs >>> RESIZE_STAMP_SHIFT) != 0)
synchronized (e) {
// 链表有多个节点,并且处于扩容状态,进行链表的拆分和复制
if (tabAt(tab, j) == e) {
Node<K,V> p = e;
do {
Node<K,V> q = p.next;
setTabAt(newTab, j, p);
setTabAt(newTab, j + n, q);
setTabAt(tab, j, q);
p = q;
nh++;
} while (p != null && tabAt(tab, j) == e);
}
}
else {
// ... 辅助链表复制的代码 ...
}
} while ((e = next) != null);
}
}
// 设置新表为当前表
table = newTab;
sizeCtl = (int)((float)n * LOAD_FACTOR + 1.0f);
} finally {
// ... 清理工作 ...
}
}
四、总结
ConcurrentHashMap通过精细化的数据结构设计、CAS操作和同步控制,实现了高效的线程安全和并发性能。其扩容策略的选择也是经过精心考虑的,旨在平衡性能和资源消耗。
需要注意的是,ConcurrentHashMap的resize方法在实际JDK实现中会更加复杂,涉及更多的细节和并发控制机制,以确保在多线程环境下的正确性和性能。此外,由于JDK版本的不同,具体的实现细节也可能会有所变化。因此,为了获取最准确和详细的实现细节,建议直接查阅对应JDK版本的源代码。
在实际应用中,我们可以根据具体场景选择合适的ConcurrentHashMap配置参数,以获得最佳的性能表现。
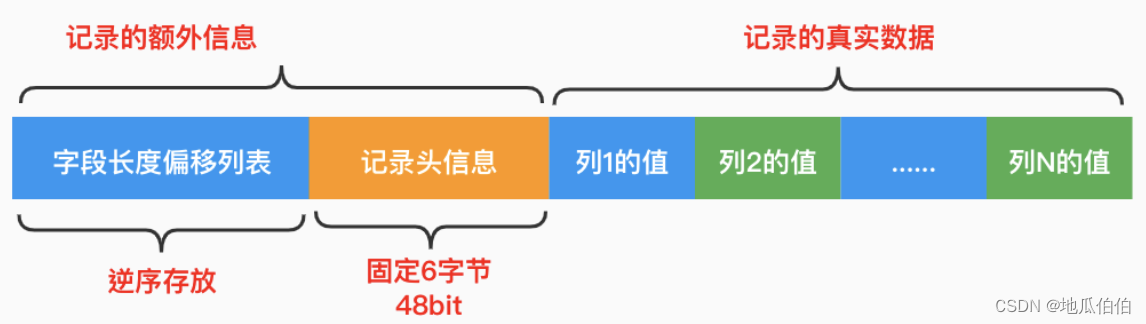



























![[ C++ ] STL---list的模拟实现](https://img-blog.csdnimg.cn/direct/a13e469e42b14b578977d629135031cf.png)