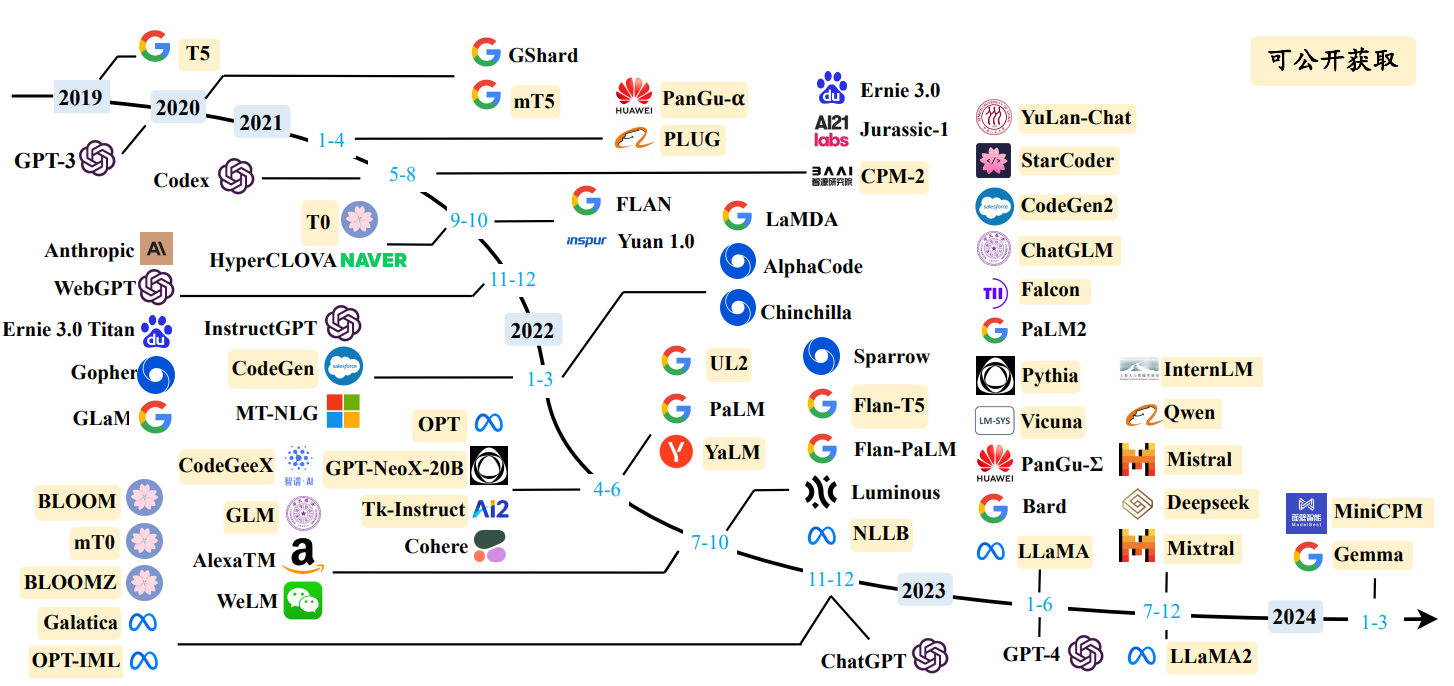
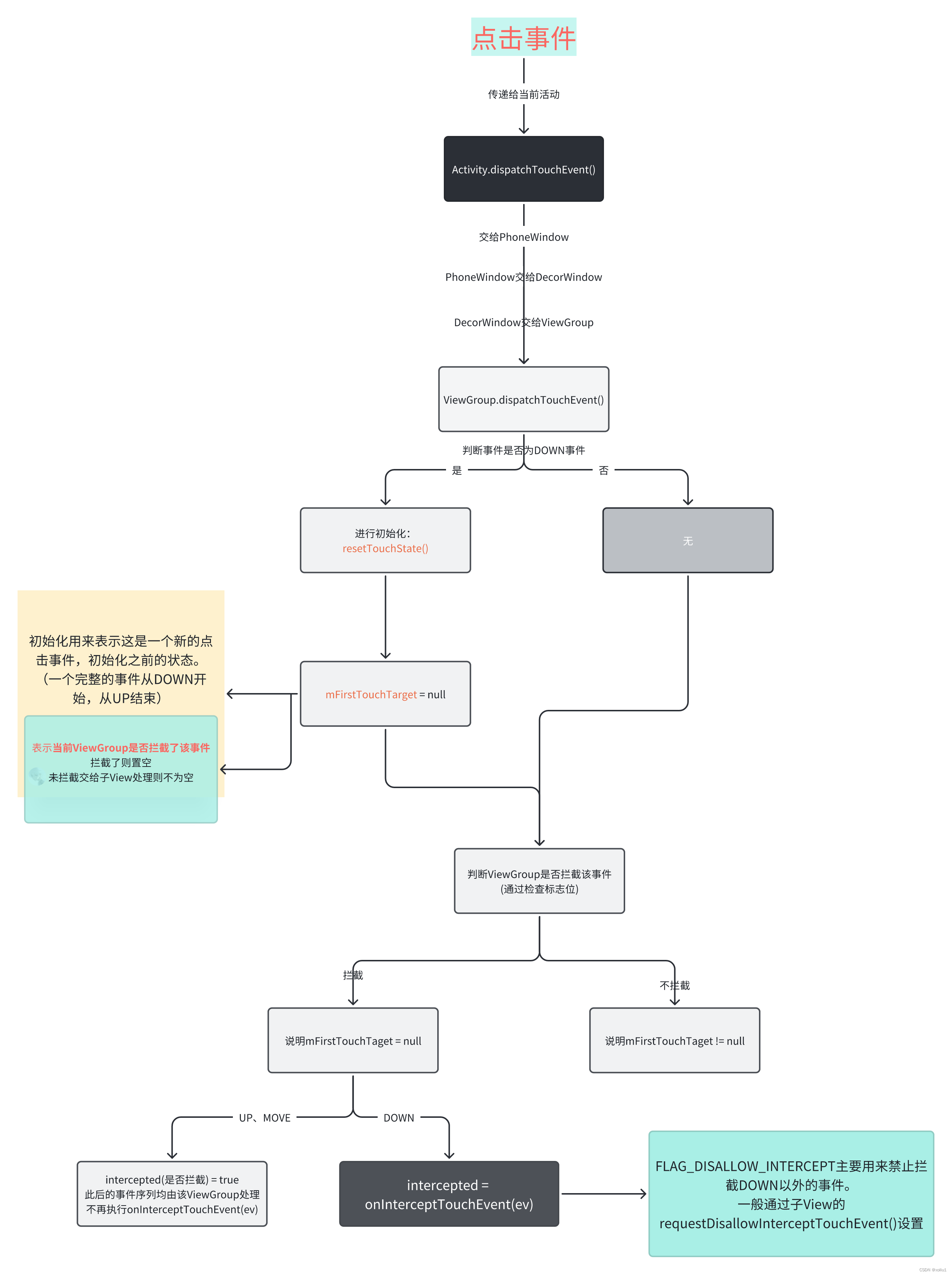
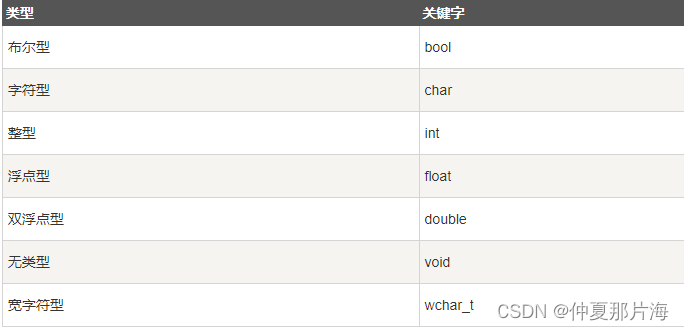
模型的参数数量通常被视为模型能力的一个重要指标,更多的参数意味着模型有更大的能力来学习、存储和泛化不同类型的数据。
以下是这种关系的几个关键点:
学习能力:参数数量越多,模型学习复杂模式的能力通常越强。这意味着大模型能够理解和生成更复杂的文本,更准确地执行特定任务。
泛化能力:尽管大模型在特定任务上的表现可能更好,但它们也有过度拟合的风险,特别是在训练数据有限的情况下。然而,实践中发现,通过适当的训练技巧和正则化方法,大模型往往能在多个任务上泛化得更好。
细节处理能力:具有更多参数的模型能够捕捉到数据中的更细微的差异和模式,这可以增强模型在语言理解、翻译、文本生成等方面的性能。
知识存储:大模型可以被看作是拥有更大的“知识库”,能够存储更多的事实、概念和世界知识。这使得它们在回答问题、撰写内容等需要广泛知识的任务上表现得更好。
适应性:大模型因其庞大的参数规模,有时可以更容易地适应新任务,无需从头开始训练。通过微调,即在特定任务的数据上进行少量的额外训练,这些模型可以快速适应并表现出色。
然而,参数数量的增加也伴随着计算资源的显著增加。这包括训练时所需的计算能力、训练过程中消耗的能源以及模型推理时的延迟。因此,在设计和部署大语言模型时,需要权衡模型性能和计算成本之间的关系。