Oracle和Mysql数据库使用Where 1=1会使索引失效吗?
数据库版本
Oracle 19c
Mysql 8.0.27
索引分析
Oracle
索引分析命令
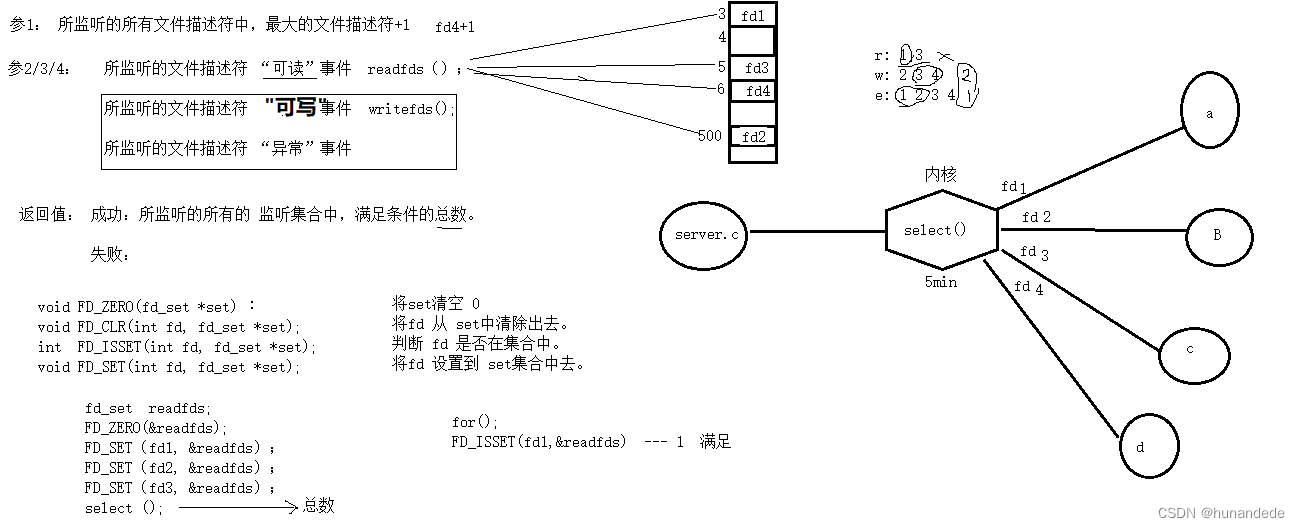
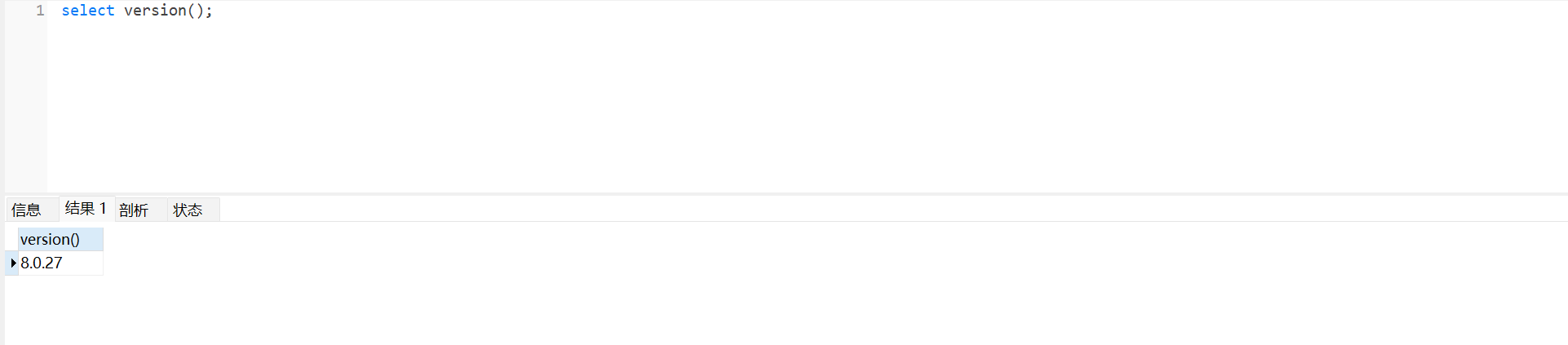
Oracle分析SQL执行计划命令:explain plan for select 1 from t, PL/SQL 工具可以使用F5快捷键。
所以不管是用F5方式还是explain plan for 方式,都有Operation参数,Operation表示sql执行过程,查看怎么执行的,有两个规则:
- 根据Operation缩进判断,缩进最多的最先执行;
- Operation缩进相同时,最上面的是最先执行的;
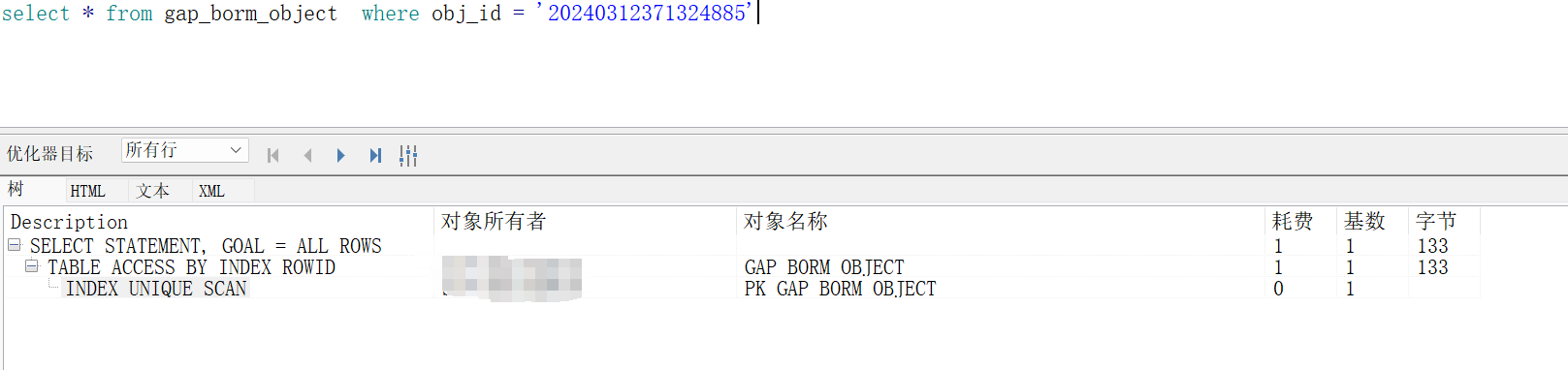
如图执行计划,根据规则,可以得出执行顺序:
INDEX UNIQUE SCAN->TABLE ACCESS BY INDEX ROWID
访问数据的方法
Oracle访问表中数据的方法有两种,一种是直接表中访问数据,另外一种是先访问索引,如果索引数据不符合目标SQL,就回表,符合就不回表,直接访问索引就可以。
Oracle直接访问表中数据的方法又分为两种:一种是全表扫描;另一种是ROWID扫描
直接访问表
全表扫描(TABLE ACCESS FULL)
全表扫描是Oracle直接访问数据的一种方法,全表扫描时从第一个区(EXTENT)的第一个块(BLOCK)开始扫描,一直扫描的到表的高水位线(High Water Mark),这个范围内的数据块都会扫描到
全表扫描是采用多数据块一起扫的,并不是一个个数据库扫的,然后我们经常说全表扫描慢是针对数据量很多的情况,数据量少的话,全表扫描并不慢的,不过随着数据量越多,高水位线也就越高,也就是说需要扫描的数据库越多,自然扫描所需要的IO越多,时间也越多
注意:数据量越多,全表扫描所需要的时间就越多,然后直接删了表数据呢?查询速度会变快?其实并不会的,因为即使我们删了数据,高位水线并不会改变,也就是同样需要扫描那么多数据块
ROWID扫描(TABLE ACCESS BY ROWID)
ROWID也就是表数据行所在的物理存储地址,所谓的ROWID扫描是通过ROWID所在的数据行记录去定位。ROWID是一个伪列,数据库里并没有这个列,它是数据库查询过程中获取的一个物理地址,用于表示数据对应的行数。
访问索引
访问索引(TABLE ACCESS BY INDEX SCAN)的情况就比较多了,可以分为:
- 索引唯一扫描(INDEX UNIQUE SCAN)
- 索引全扫描(INDEX FULL SCAN)
- 索引范围扫描(INDEX RANGE SCAN)
- 索引快速全扫描(INDEX FAST FULL SCAN)
- 索引跳跃式扫描(INDEX SKIP SCAN)
索引唯一扫描(INDEX UNIQUE SCAN)
索引唯一性扫描(INDEX UNIQUE SCAN)是针对唯一性索引(UNIQUE INDEX)来说的,也就是建立唯一性索引才能索引唯一性扫描,唯一性扫描,其结果集只会返回一条记录。
索引范围扫描(INDEX RANGE SCAN)
索引范围扫描(INDEX RANGE SCAN)索引范围扫描(INDEX RANGE SCAN)适用于所有类型的B树索引,一般不包括唯一性索引,因为唯一性索引走索引唯一性扫描。 当扫描的对象是非唯一性索引的情况,where谓词条件为Between、=、<、>等等的情况就是索引范围扫描,注意,可以是等值查询,也可以是范围查询。如果where条件里有一个索引键值列没限定为非空的,那就可以走索引范围扫描,如果改索引列是非空的,那就走索引全扫描
前面说了,同样的SQL建的索引不同,就可能是走索引唯一性扫描,也有可能走索引范围扫描。在同等的条件下,索引范围扫描所需要的逻辑读和索引唯一性扫描对比,逻辑读如何?索引范围扫描可能返回多条记录,所以优化器为了确认,肯定会多扫描,所以在同等条件,索引范围扫描所需要的逻辑读至少会比相应的唯一性扫描的逻辑读多1
索引全扫描(INDEX FULL SCAN)
索引全扫描(INDEX FULL SCAN)适用于所有类型的B树索引(包括唯一性索引和非唯一性索引)。
索引全扫描过程简述:索引全扫描是指扫描目标索引所有叶子块的索引行,但不意思着需要扫描所有的分支块,索引全扫描时只需要访问必要的分支块,然后定位到位于改索引最左边的叶子块的第一行索引行,就可以利用改索引叶子块之间的双向指针链表,从左往右依次顺序扫描所有的叶子块的索引行
索引快速全扫描(INDEX FAST FULL SCAN)
索引快速全扫描和索引全扫描很类似,也适用于所有类型的B树索引(包括唯一性索引和非唯一性索引)。和索引全扫描类似,也是扫描所有叶子块的索引行,这些都是索引快速全扫描和索引全扫描的相同点
索引快速全扫描和索引全扫描区别:
- 索引快速全扫描只适应于CBO(基于成本的优化器)
- 索引快速全扫描可以使用多块读,也可以并行执行
- 索引全扫描会按照叶子块排序返回,而索引快速全扫描则是按照索引段内存储块顺序返回
- 索引快速全扫描的执行结果不一定是有序的,而索引全扫描的执行结果是有序的,因为索引快速全扫描是根据索引行在磁盘的物理存储顺序来扫描的,不是根据索引行的逻辑顺序来扫描的
索引跳跃式扫描(INDEX SKIP SCAN)
索引跳跃式扫描(INDEX SKIP SCAN)适用于所有类型的复合B树索引(包括唯一性索引和非唯一性索引),索引跳跃式扫描可以使那些在where条件中没有目标索引的前导列指定查询条件但是有索引的非前导列指定查询条件的目标SQL依然可以使用跳跃索引
Mysql
Mysql分析SQL执行计划命令:explain select 1 from t
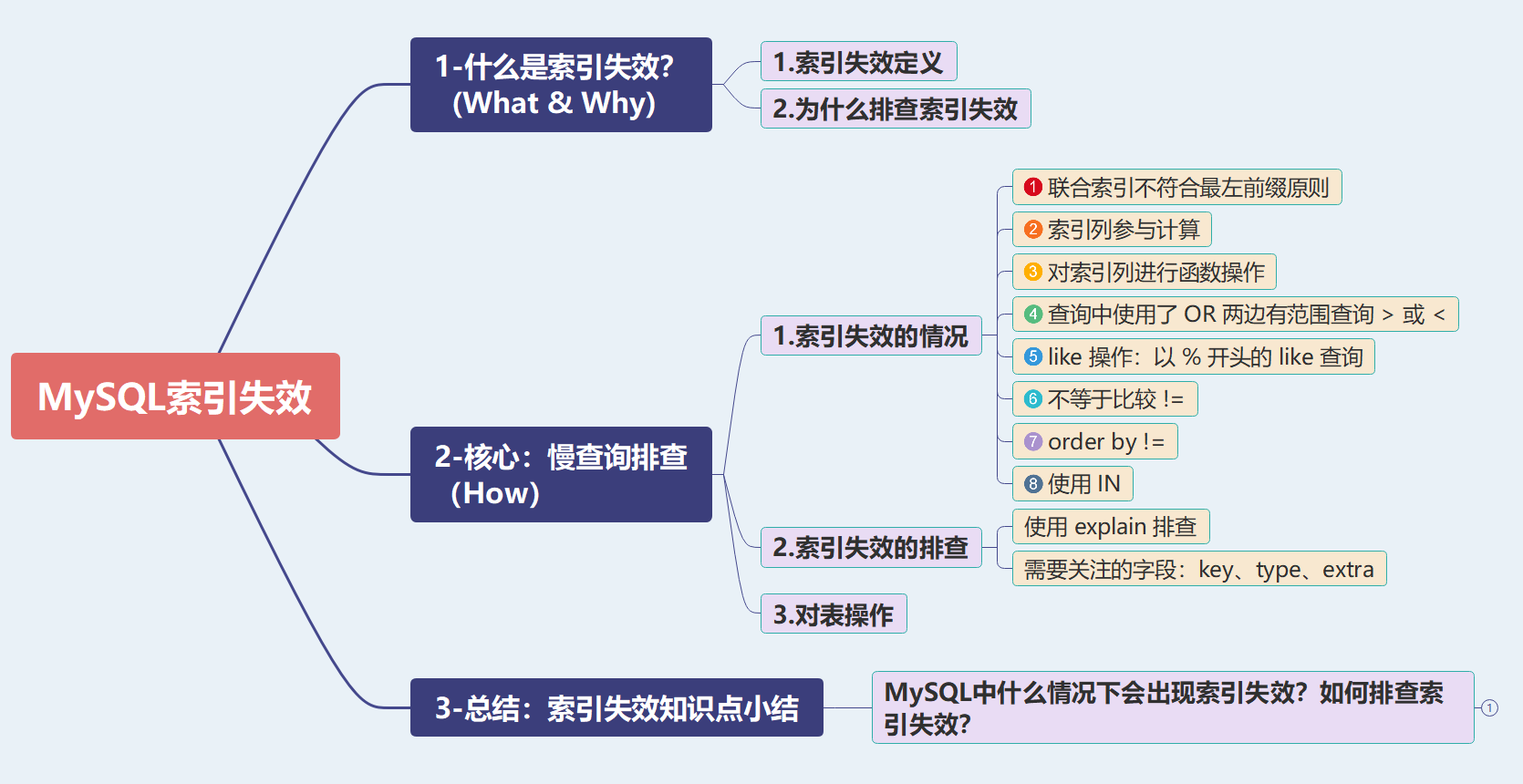
具体Mysql索引查看:程序员必须知道的MySQL优化篇 SQL优化(二)
论证
验证MySQL
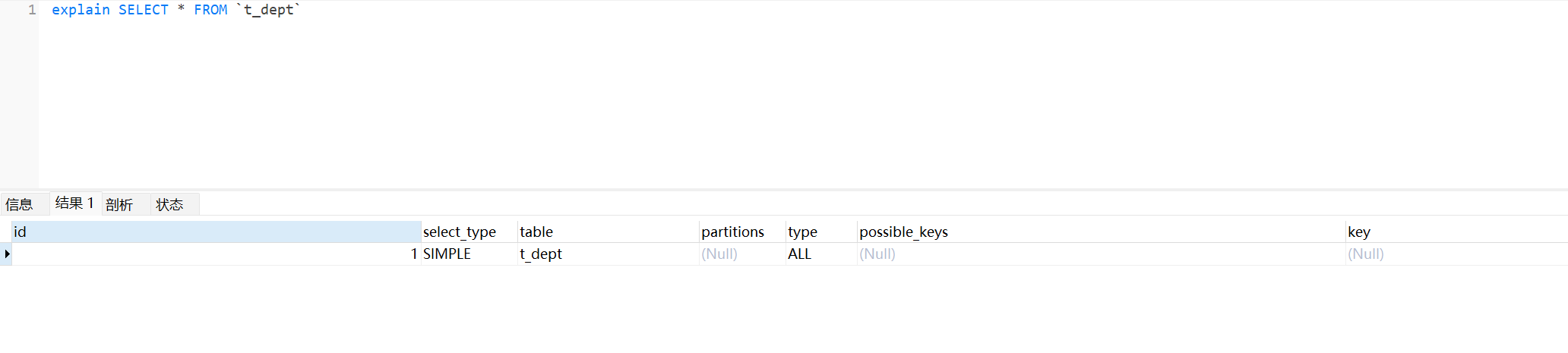
1、MySQL表 t_dept的主键DEPT_ID

2、添加where 1=1 验证,索引类型还是const,证明不影响

type 显示的是访问类型,是较为重要的一个指标,可取值为:
| type | 含义 |
|---|---|
| NULL | MySQL不访问任何表,索引,直接返回结果 |
| system | 表只有一行记录(等于系统表),这是const类型的特例,一般不会出现 |
| const | 表示通过索引一次就找到了,const 用于比较primary key 或者 unique 索引。因为只匹配一行数据,所以很快。如将主键置于where列表中,MySQL 就能将该查询转换为一个常亮。const于将 “主键” 或 “唯一” 索引的所有部分与常量值进行比较 |
| eq_ref | 类似ref,区别在于使用的是唯一索引,使用主键的关联查询,关联查询出的记录只有一条。常见于主键或唯一索引扫描 |
| ref | 非唯一性索引扫描,返回匹配某个单独值的所有行。本质上也是一种索引访问,返回所有匹配某个单独值的所有行(多个) |
| range | 只检索给定返回的行,使用一个索引来选择行。 where 之后出现 between , < , > , in 等操作。 |
| index | index 与 ALL的区别为 index 类型只是遍历了索引树, 通常比ALL 快, ALL 是遍历数据文件。 |
| all | 将遍历全表以找到匹配的行 |
结果值从最好到最坏以此是:
一般来说, 我们需要保证查询至少达到 range 级别, 最好达到ref 。
NULL > system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
system > const > eq_ref > ref > range > index > ALL
结论:where1=1不影响MySQL的SQL性能,也不会导致索引失效。因为SQL优化器已经将where1=1过滤了。
验证Oracle
1、Oracle表 gap_borm_object的主键obj_id
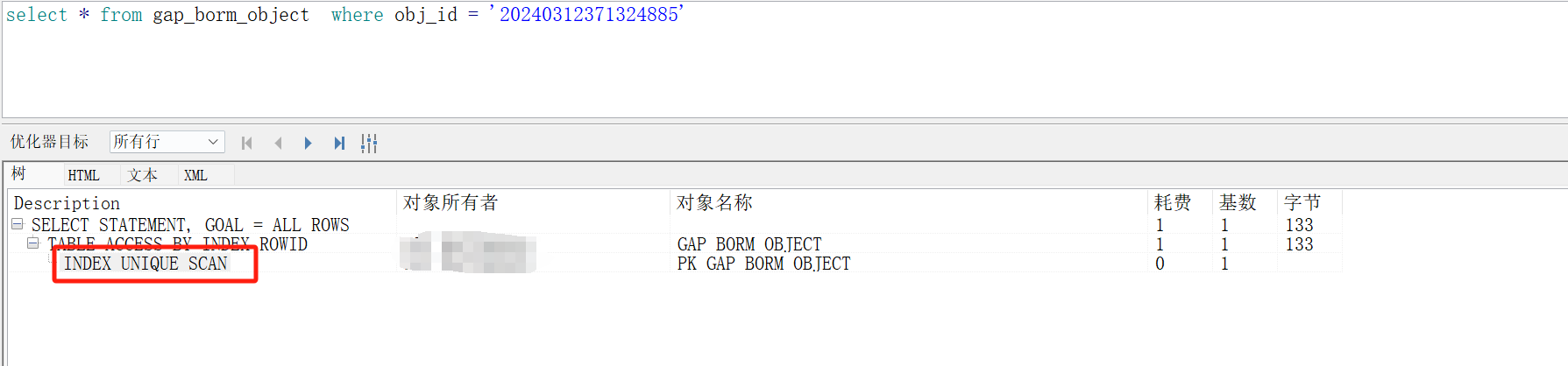
2、添加where 1=1 验证,发现还是走了索引查询
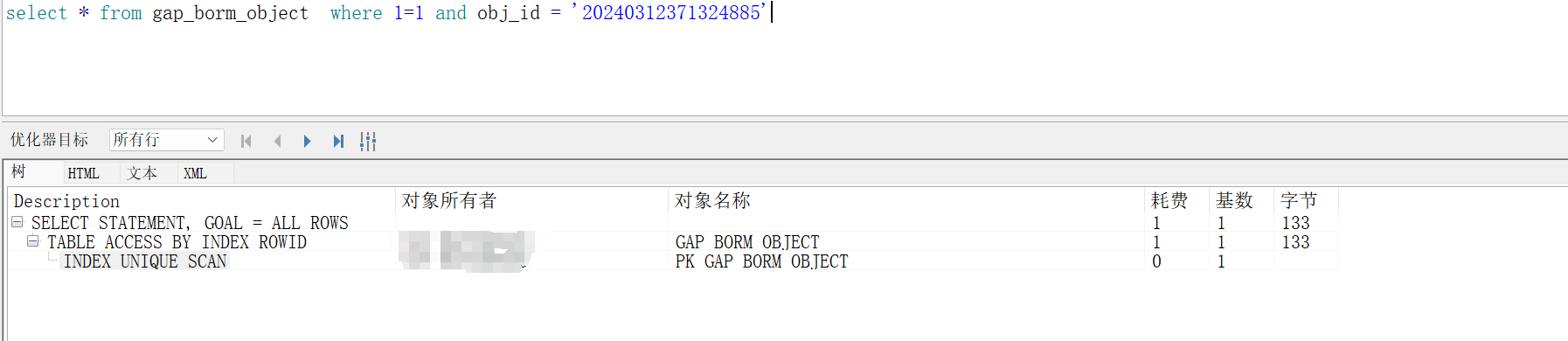
结论:where1=1同样也不影响Oracle的SQL性能,也不会导致索引失效。
我们回头再考虑一下为什么大家都在说“1=1”会影响SQL的性能,可能在很久之前的sql版本中,“1=1”确实
会影响到sql语句的索引优化过程,这是一个很严重的问题,所以大家都记得这个事,在后来sql将这个问题
给优化掉了,但是很多新人听老人仍在讲这个问题,所以就一直记得,新人变成老人后又给其他新人去说这个
问题,慢慢的大家都记得这个问题,但已经没有人去验证它的真假了。