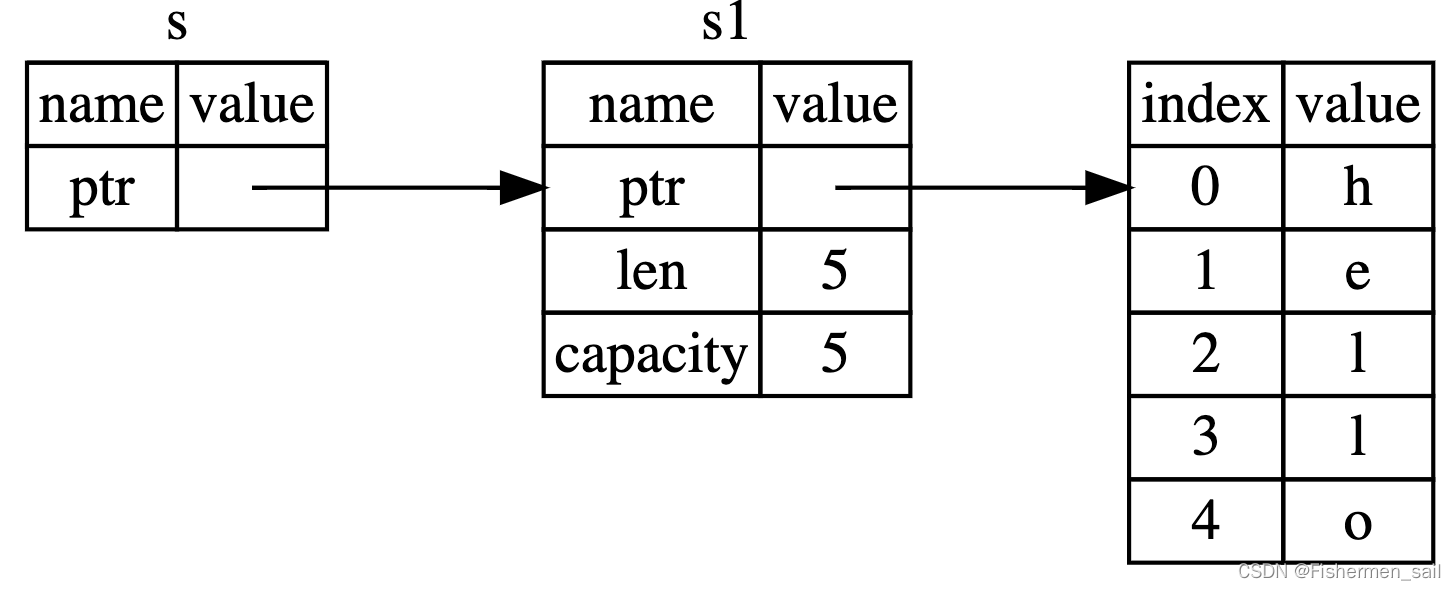
8 集合
Rust 标准库中包含一系列被称为 集合(collections)的非常有用的数据结构。大部分其他数
据类型都代表一个特定的值,不过集合可以包含多个值。不同于内建的数组和元组类型,这些
集合指向的数据是储存在堆上的,这意味着数据的数量不必在编译时就已知,并且还可以随着
程序的运行增长或缩小。
常见的三种集合:
vector允许我们一个挨着一个地储存一系列数量可变的值字符串(string)是字符的集合。我们之前见过 String 类型哈希 map(hash map)允许我们将值与一个特定的键(key)相关联。这是一个叫做 map的更通用的数据结构的特定实现。
8.1 Vector
vector 允许我们在一个单独的数据结构中储存多于一个的值,它在内存中彼此相邻地排列所有的值。vector 只能储存相同类型的值。
fn main() {
// 1.新建一个空vector
let _v1: Vec<i32> = Vec::new();
// 2.新建一个包含初值的 vector
let _v2 = vec![1, 2, 3];
// 3.使用 push 方法向 vector 增加值
let mut _v3: Vec<i32> = Vec::new();
_v3.push(3);
_v3.push(4);
_v3.push(5);
// 4. 读取vector元素
let v = vec![1, 2, 3, 4, 5];
let third: &i32 = &v[2];
println!("Third element is {third}");
let third: Option<&i32> = v.get(2);
match third {
Some(i) => println!("Third element is {i}"),
None => println!("There is no third element")
}
// let not_exist: Option<&i32> = &v[100]; 索引越界,程序会异常
// 当 get 方法被传递了一个数组外的索引时,它不会 panic 而是返回 None
//当偶尔出现超过 vector 范围的访问属于正常情况的时候可以考虑使用它
let not_exist: Option<&i32> = v.get(100);
match not_exist {
Some(i) => println!("Third element is {i}"),
None => println!("There is no third element")
}
}
当我们获取了 vector 的第一个元素的不可变引用并尝试在 vector 末尾增加一个元素的时候,如果尝试在函数的后面引用这个元素是行不通的:
fn main() {
let mut v = vec![1, 2, 3, 4, 5];
let first = &v[0];
v.push(6);
println!("The first element is: {first}");
}
不能这么做的原因是由于 vector 的工作方式:在 vector 的结尾增加新元素时,在没有足够空间将所有元素依次相邻存放的情况下,可能会要求分配新内存并将老的元素拷贝到新的空间中。这时,第一个元素的引用就指向了被释放的内存。借用规则阻止程序陷入这种状况。
遍历 vector 中的元素
fn main() {
let mut v = vec![100, 32, 22];
for x in &v { // x是v中元素的不可变引用
println!("{x}");
}
// 为了修改可变引用所指向的值
// 在使用 += 运算符之前必须使用解引用运算符(* )获取 x 中的值
for x in &mut v { // x是v中元素的可变引用
*x += 50;
}
for x in v { // 遍历完 v 中元素的所有权就被转移了
println!("{x}");
}
println!("{}", v[0]); // error
// 但是数组这样是可以的,因为使用 for 循环来遍历一个数组时,在底层它隐式地创建并接着消费了一个迭代器
let a = [11, 22, 33, 44, 55];
for x in a { // x是a中元素的不可变引用
println!("{x}");
}
println!("{}", a[0]);
}
使用枚举来储存多种类型
定义一个枚举,以便能在 vector 中存放不同类型的数据
enum SpreadsheetCell {
Int(i32),
Float(f64),
Text(String),
}
fn main() {
let _row = vec![
SpreadsheetCell::Int(3),
SpreadsheetCell::Text(String::from("blue")),
SpreadsheetCell::Float(10.12),
];
}
类似于任何其他的 struct ,vector 在其离开作用域时会被释放,所有其内容也会被丢弃,这意味着这里它包含的整数将被清理。
fn main() {
{
let v = vec![1, 2, 3, 4];
// do stuff with v
} // <- v goes out of scope and is freed here
}
}
8.2 String
rust 的核心语言层面,只有一个字符串类型:字符串 slice str 即 &str
字符串切片:对存储在其他地方、UTF-8 编码的字符串的引用
- 字符串字面值:存储在二进制文件中,也是字符串切片
String 类型:
- 来自 标准库 而不是核心语言
- 可增长、可修改、可拥有
- UTF-8 编码
通常说的字符串是 String 和 &str
其他类型的字符串
rust 的标准库里还包含了很多其他的字符串类型,例如:OsString,OsStr,CString,Cstr
上述以 String 结尾的类型:通常可获得所有权的;以 Str 结尾的类型:通常是指可借用的
String 的使用
fn main() {
// 1.新建 String
let data = "initial contents";
let _s = data.to_string();
let _s = "initial conents".to_string();
let _s = String::from("initial contents");
// 2.更新字符串
let mut s = String::from("foo");
s.push_str("tball "); // 向 String 附加字符串 slice
s.push('A'); // push只能添加一个字符
println!("{s}");
// 3.拼接字符串(+)
/* + 运算符,使用了类似 fn add(self, s: &str) -> String {...} 的方法
s1作为self的参数,而s2是 &String(String引用)类型,并不是参数里的 &str 类型
这里编译通过的原因是:Rust 使用了一个被成为 Deref 强制转换的技术,将 &String 强转成 &str
因为add没有获取参数的所有权,因此 s2 在操作后仍然是有效的
*/
let s1 = String::from("Hello, ");
let s2 = String::from("world!");
let s3 = s1 + &s2; // 注意 s1 被移动了,不再拥有所有权,不能继续使用
// 相加过程:获取 s1 的所有权,附加上从 s2 中拷贝的内容,并返回结果的所有权,这个实现比拷贝要更高效
// println!("{s1}"); error
println!("{s2}"); // Ok
println!("{s3}");
// 级联多个字符串
let str1 = String::from("tic");
let str2 = String::from("tac");
let str3 = String::from("toe");
let _str = str1.clone() + "-" + &str2 + "-" + &str3;
println!("{_str}");
// 宏format! 使用引用所以不会获取任何参数的所有权
let _str: String = format!("{str1}-{str2}-{str3}");
println!("{_str}");
}
字符串索引与字符串在内部表现
rust 中是无法对字符串进行索引的
let s1 = String::from("hello"); // 4个字节
let h = s1[0]; // Error
内部表现
String 是一个 Vec<u8> 的封装。
let hello = String::from("Здравствуйте"); // 24个字节
对于这样一个字符串,它的字节数是 24,也就是一个字符占用了2个字节,因此无法按照统一的方式对所有字符串进行读取,为了避免返回意外的值并造成不能立刻发现的 bug,Rust 根本不会编译这些代码,并在开发过程中及早杜绝了误会的发生。
字节、标量值和字形簇
Rust 有三种看待字符串的方式:
- 字节
- 标量值
- 字形簇(最接近所谓的 “字母”)
fn main() {
let s = "नमस्ते";
for x in s.bytes() { // 字节的形式
println!("{}", x);
}
for x in s.chars() { // unicode 标量的形式
println!("{}", x);
}
}
rust 不允许对 String 进行索引的最后一个原因:
- 索引操作应消耗一个常量时间 (O(1))
- String 无法保证:需要遍历所有内存,来确定有多少个合法的字符
字符串 slice
索引字符串在rust中是不被允许的,因为字符串索引应该返回的类型是不明确的:字节值、字符、字形簇或者字符串 slice。因此,如果你真的希望使用索引创建字符串 slice 时,Rust 会要求你更明确一些。为了更明确索引并表明你需要一个字符串 slice,相比使用 [] 和单个值的索引,可以使用 [] 和一个 range 来创建含特定字节的字符串 slice:
fn main() {
let hello = "Здравствуйте";
let s = &hello[0..4];
}
这里,s 会是一个 &str ,它包含字符串的头四个字节。早些时候,我们提到了这些字母都是两个字节长的,所以这意味着 s 将会是 “Зд”。
如果获取 &hello[0..1] 会发生什么呢?答案是:Rust 在运行时会 panic,就跟访问 vector中的无效索引时一样。
遍历字符串的方法
操作字符串每一部分的最好的方法是明确表示需要字符还是字节。对于单独的 Unicode 标量值使用 chars() 方法。
// unicode 标量形式
for c in "Зд".chars() {
println!("{c}");
}
/*
З
д
*/
// 字节形式
for b in "Зд".bytes() {
println!("{b}");
}
/*
208
151
208
180
*/
8.3 HashMap
哈希映射:HashMap<K, V>,它存储了从 K 类型键到 V 类型值之间的映射
关系。哈希映射在内部实现中使用了哈希函数 ,这同时决定了它在内存中存储键值对的方式。
use std::collections::HashMap; // 使用use将HashMap从标准库的集合部分引入当前作用域
fn main() {
// 1. 创建一个新的HashMap
let mut scores: HashMap<String, u8> = HashMap::new();
// 如果有insert添加元素的语句,那么上边可以不显示地指定类型,否则必须指定
scores.insert(String::from("Bob"), 90);
scores.insert(String::from("Lucy"), 89);
// 2. 使用 collect 方法创建 HashMap
let terms = vec![String::from("Blue"), String::from("Black")];
let initial_score = vec![90, 99];
let _scores: HashMap<_,_> = // collect可以作用于许多不同的数据结构, 因此这里的显示指定不能省略
terms.iter().zip(initial_score.iter()).collect();
}
HashMap 和所有权
- 对于实现了
Copy trait的类型(例如 i32),值会被复制到 HashMap 中 - 对于拥有所有权的值(例如 String),值会被移动,所有权会转移给 HashMap
use std::collections::HashMap; // 使用use将HashMap从标准库的集合部分引入当前作用域
fn main() {
let field_name = String::from("Favorite color");
let field_value = String::from("Blue");
let mut map = HashMap::new();
map.insert(field_name, field_value);// filed_name和field_value从这一刻开始失效
println!("{field_name}"); // Error
map.insert(&field_name, &field_value);// 插入值的引用,不会转移所有权
println!("{field_name} {field_value}"); // Ok
}
访问 HashMap 中的值
使用 get 方法,取出 K 对应的 V
- 参数:K
- 返回:Option<&V>
use std::collections::HashMap;
fn main() {
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
let team_name = String::from("Blue");
// 返回 Option 类型
let score: Option<&i32> = scores.get(&team_name);
// 如果有值,就用match取出
match score {
Some(i) => println!("{i}"),
None => println!("not exits"),
};
}
遍历 HashMap
use std::collections::HashMap;
fn main() {
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
for (k, v) in &scores { // 不加&,元素所有权会被转移,或者用iter()方法
println!("{k} {v}");
}
}
更新 HashMap
split_whitespace 是一个用于字符串处理的方法,它可以将字符串按空白字符(空格、制表符、换行符等)分割成一个个单词(或者单词片段)并返回一个迭代器。
这个方法属于 str 类型的方法,因此可以直接在字符串上调用。它不会修改原始字符串,而是返回一个迭代器,这个迭代器会产生原始字符串中每个单词(或者单词片段)的引用。
use std::collections::HashMap;
fn main() {
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
// 1.覆盖旧值,即替换现有的V
scores.insert(String::from("Blue"), 25);
println!("{:?}", scores);
// 2.如果不存在则插入,保留现有的 V,忽略新的 V
// Entry的or_insert方法被定义为返回一个Entry键所指向值的可变引用
// 假如这个值不存在,就将参数作为新值插入哈希映射中,并把这个新值的可变引用返回。
scores.entry(String::from("Yellow")).or_insert(50); // 不存在Yellow,会插入
scores.entry(String::from("Blue")).or_insert(50); // 已经存在Bule,不会插入
println!("{:?}", scores);
// 3.基于旧值来更新值
let text = "hello world wonderful world";
let mut map = HashMap::new();
for word in text.split_whitespace() {
// 方法or_insert实际上为我们传入的键返回了一个指向关联值的可变引用(&mut V)
// 这个可变引用进而被存储到变量count上
let count: &mut i32 = map.entry(word).or_insert(0);
// 为了对这个值进行赋值操作,我们必须首先使用星号(*)来对count进行解引用
*count += 1;
}
println!("{:?}", map);
}
9 rust 错误处理
大部分情况下:在编译时提示错误,并处理
错误的分类:
- 可恢复:例如文件未找到,可再次尝试
- 不可恢复:bug,例如访问的索引超出范围
Rust 没有类似异常的机制
- 可恢复错误:
Rreult<T,E> - 不可恢复错误:中止运行的
panic!宏
不可恢复错误与panic!
程序会在 panic! 宏执行时打印出一段错误提示信息,展开并清理当前的
调用栈,然后退出程序。
panic中的栈展开与终止
程序展开调用栈(默认,工作量大):
- rust 沿着调用栈往回走
- 清理每个遇到的函数中的数据
立即中止调用栈:
- 不需要清理,直接停止程序
- 内存需要 os 进行清理
假如项目需要使最终二进制包尽可能小,可以在 Cargo.toml 文件中的 [profile] 区域添加 panic = 'abort' 来将 panic 的默认行为从展开切换为终止。
// 在发布模式中使用终止模式,在配置文件中加入
[profile.release]
panic = 'abort'
可恢复错误与 Result
Result,处理可能出现错误的操作的一种标准方式,是一个枚举类型
这里的 T 和 E 是泛型参数
enum Result<T,E> {
Ok(T), // 操作成功时,Ok变体返回的数据类型是T
Err(E), // 操作失败时,Err变体返回的数据类型是E
}
打开文件的例子
// 和 Option 一样,Result 及其变体也是由 prelude 带入作用域,因此不需要显示声明
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let open_result = File::open("hello.txt");
let open_result = match open_result {
Ok(file) => file,
Err(error) => match error.kind() {
ErrorKind::NotFound => match File::create("hello.txt") {
Ok(fc) => fc,
Err(e) => panic!("Error opening the file: {:?}", e),
}
other_error => panic!("Error opening the file: {:?}", other_error),
},
};
}
unwrap 和 expect
unwrap
- 当 Result 的返回值是 Ok 变体,unwrap 就会返回 Ok 内部的值
- 当 Result 的返回值是 Err 变体,unwrap 则会替我们调用
panic!宏。
let open_result = File::open("hello.txt").unwrap(); // 无法自定义错误信息
expect
与 unwrap 类似,但是可以指定 panic! 附带的错误信息
let open_result = File::open("hello.txt").exoect("打开文件失败");
传播错误
当编写的函数中包含了一些可能会执行失败的调用时,除了可以在函数中处理这个错误,还可以将这个错误返回给调用者,让他们决定应该如何做进一步处理。这个过程也被称作传播错误,在调用代码时它给了用户更多的控制能力。与编写代码时的上下文环境相比,调用者可能会拥有更多的信息和逻辑来决定应该如何处理错误。
use std::fs::File;
use std::io::{self, Read};
fn read_username_from_file() -> Result<String, io::Error> {
let f: Result<File, io::Error> = File::open("hello.txt");
let mut f: File = match f {
Ok(file) => file,
Err(e) => return Err(e),
};
let mut s = String::new();
match f.read_to_string(&mut s) {
Ok(_) => Ok(s),
Err(e) => Err(e),
} // 函数返回此match表达式的值
}
fn main() {
let _ = read_username_from_file();
}
传播错误的快捷方式:? 运算符,只能用于返回类型为 Result 类型的函数
use std::fs::File;
use std::io::{self, Read};
fn read_username_from_file() -> Result<String, io::Error> {
// 使用 ? 运算符,当Err发生时,会return Err,否则会返回读取的 File
// 因此这里的 f 不需要使用 Result 类型
let mut f: File = File::open("hello.txt")?;
let mut s: String = String::new();
f.read_to_string(&mut s)?;
Ok(s)
}
fn main() {
let _ = read_username_from_file();
}
? 与 from 函数
Trait std::convert::From 上的 from 函数:用于错误之间的转换
被 ? 运算符所接收的错误值,会隐式地被 from 函数处理。当 ? 调用 from 函数时,?所接收的错误类型会被转化为当前函数返回类型所定义的错误类型。当一个函数拥有不同的失败原因,却使用了统一的错误返回类型来同时进行表达时,这个功能会十分有用。前提是每个错误类型都实现了转换为返回错误类型的 from 函数,这时 ? 运算符就会自动帮我们处理所有的转换过程。
举例来说,假设我们有一个函数 fn foo() -> Result<i32, CustomError>,而在其中调用了一个可能返回 Result<i32, OtherError> 类型的函数,并使用了 ?运算符来处理错误。如果 OtherError 类型可以转换为 CustomError 类型,那么编译器将会自动调用 From 实现来进行转换,从而使得 Result<i32, OtherError> 类型的错误被转换为 Result<i32, CustomError> 类型。
链式调用
错误处理的开销通常不是程序性能的瓶颈,链式调用一般只会影响代码可读性
fn read_username_from_file() -> Result<String, io::Error> {
let mut s = String::new();
File::open("hello.txt")?.read_to_string(&mut s)?;
Ok(s)
}
何时使用 panic!
总体原则
- 在定义一个可能失败的函数时,优先考虑返回
Result - 否则就
panic!(认为自己可以代替调用者决定某种情形是不可恢复的)
场景建议
- 用户调用你的代码,传入无意义的参数值:
panic! - 调用外部不可控代码,返回非法状态,你无法修复:
panic! - 当你的代码对值进行操作,首先应该验证这些值:
panic! - 如果失败是可预期的:
Result,例如解析字符串成数字
创建自定义类型来进行有效性验证
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
// 对数据范围进行验证
if value < 1 || value > 100 {
panic!("Guess value must between 1 and 100");
}
Guess {value}
}
// 读取接口 (getter)
pub fn value(&self) -> i32 {
self.value
}
}
10.1 泛型
结构体
struct Point<T, U> { // 使用两个参数,x和y的类型可以相同,也可以不同
x: T,
y: U,
}
fn main() {
let both_integer = Point { x: 5, y: 10 };
let both_float = Point { x: 1.0, y: 4.0 };
let integer_and_float = Point { x: 5, y: 4.0 };
}
Option<T> 枚举
enum Option<T> { // 一个泛型参数
Some(T),
None,
}
Result<T, E> 枚举
enum Result<T, E> {
Ok(T),
Err(E),
}
方法定义中的泛型
例1:
struct Point<T> {
x: T,
y: T,
}
// 参数 T 放在impl后边,表示在类型 T 上实现方法
impl<T> Point<T> {
// get_x方法是针对所有T类型都可以调用的
fn get_x(&self) -> &T { // 第一个参数为self,因此是方法
&self.x
}
}
// 具体类型不需要在 impl 后声明
impl Point<f32> {
// 而distance_from_origin()方法只有参数为 f32 时才能调用
fn distance_from_origin(&self) -> f32 {
(self.x.powi(2) + self.y.powi(2)).sqrt()
}
}
fn main() {
let p = Point { x: 5, y: 10 };
println!("p.x = {}", p.get_x());
let p2: Point<f32> = Point{ x: 5.0, y : 12.0};
let dis = p2.distance_from_origin();
println!("{dis}")
}
例2:
struct Point<T> {
x: T,
y: T,
}
impl<T> Point<T> {
// get_x方法是针对所有T类型都可以调用的
fn get_x(&self) -> &T {
&self.x
}
}
impl Point<f32> {
// 而distance_from_origin()方法只有参数为f32时才能调用
fn distance_from_origin(&self) -> f32 {
(self.x.powi(2) + self.y.powi(2)).sqrt()
}
}
fn main() {
let p = Point { x: 5, y: 10 };
println!("p.x = {}", p.get_x());
let p2: Point<f32> = Point{ x: 5.0, y : 12.0};
let dis = p2.distance_from_origin();
println!("distance_from_origin = {dis}");
}
泛型代码的性能
Rust 通过在编译时进行泛型代码的 单态化(monomorphization)来保证效率。单态化是一个通过填充编译时使用的具体类型,将通用代码转换为特定代码的过程。编译器寻找所有泛型代码被调用的位置并使用泛型代码针对具体类型生成代码。
例:
let integer = Some(5);
let float = Some(5.0);
当 Rust 编译这些代码的时候,它会进行单态化。编译器会读取传递给 Option<T> 的值并发现有两种 Option<T> :一个对应 i32 另一个对应 f64 。为此,它会将泛型定义 Option<T> 展开为两个针对 i32 和 f64 的定义,接着将泛型定义替换为这两个具体的定义。
enum Option_i32 {
Some(i32),
None,
}
enum Option_f64 {
Some(f64),
None,
}
fn main() {
let integer = Option_i32::Some(5);
let float = Option_f64::Some(5.0);
}
使用泛型没有运行时开销,当代码运行时,它的执行效率就跟好像手写每个具体定义的重复代码一样。这个单态化过程正是 Rust 泛型在运行时极其高效的原因。
10.2 Trait
- Trait 告诉 rust 编译器:某种类型具有哪些并且可以与其他类型共享的功能
- Trait:抽象的定义共享行为
- Trait bounds(约束):泛型类型参数指定为实现了特定行为的类型
- Trait 与其他语言的接口(interface)类似,但有些区别。
定义一个 Trait
Trait 的定义:把方法签名放在一起,来定义实现某种目的所必需的一组行为
- 关键字:trait
- 只有方法签名,没有具体实现
- trait 可以有多个方法:每个方法签名占一行,以
;结尾 - 实现该 trait 的类型必须提供具体的方法实现
文件名:src/lib.rs
pub trait Summary {
fn summarize(&self) -> String;
}
为类型实现 trait
文件名:src/lib.rs
// 声明为 pub,以便依赖这个 crate 的 crate 也可以使用这个 trait
pub trait Summary {
// summarize 函数在Summary Trait中是一个关联函数,在NewsArticle类型上实现后,它是一个方法
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
// 在NewsArticle类型上实现Summary这个trait
// trait 类型 T
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct Tweet {
pub username: String,
pub content: String,
pub reply: bool,
pub retweet: bool,
}
// 在Tweet类型上实现Summary这个trait
impl Summary for Tweet {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
文件名:main.rs
use _013_generics::Summary;
use _013_generics::Tweet;
fn main() {
let tweet = Tweet {
username: String::from("horse_ebooks"),
content: String::from("of course, as you probably already know"),
reply: false,
retweet: false,
};
println!("1 new tweet: {}", tweet.summarize());
}
实现 trait 的约束
可以在某个类型上实现某个 trait 的前提条件是:这个类型或这个 trait 是在本地 crate 里定义的(属于当前的 crate)。例如,可以为 _013_generics crate 的自定义类型 Tweet 实现如标准库中的Display trait,这是因为 Tweet 类型位于 _013_generics crate 本地的作用域中。类似地,也可以在 _013_generics crate 中为 Vec<T> 实现 Summary ,这是因为 Summary trait 位于 _013_generics crate 本地作用域中。
无法为外部类型来实现外部的 trait,例如,不能在 _013_generics crate 中为 Vec<T> 实现 Display trait。这是因为 Display 和 Vec<T> 都定义于标准库中,它们并不位于 _013_generics crate 本地作用域中。这个限制是被称为 相干性(coherence)的程序属性的一部分,或者更具体的说是 孤儿规则(orphan rule),其得名于不存在父类型。这条规则确保了其他人编写的代码不会破坏你代码,反之亦然。没有这条规则的话,两个 crate 可以分别对相同类型实现相同的 trait,而 Rust 将无从得知应该使用哪一个实现。
默认实现
有时为 trait 中的某些或全部方法提供默认的行为,而不是在每个类型的每个实现中都定义自
己的行为是很有用的。这样当为某个特定类型实现 trait 时,可以选择保留或重载每个方法的
默认行为。
文件名:src/lib.rs
// 声明为 pub,以便依赖这个 crate 的 crate 也可以使用这个 trait
pub trait Summary {
// 为 Summary trait 的 summarize 方法指定一个默认的字符串值
fn summarize(&self) -> String {
String::from("(Read more...)")
}
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
// 对 NewsArticle 实例使用默认实现,指定一个空的 impl 块即可
impl Summary for NewsArticle {}
pub struct Tweet {
pub username: String,
pub content: String,
pub reply: bool,
pub retweet: bool,
}
// 在Tweet类型上自定义实现Summary这个trait,默认实现的重写实现
// 虽然定义trait时创建了默认实现,自定义该trait仍可以使用
impl Summary for Tweet {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
文件名:src/main.rs
use _013_generics::{self, NewsArticle, Summary, Tweet};
fn main() {
let article = NewsArticle {
headline: String::from("Penguins win the Stanley Cup Championship!"),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"The Pittsburgh Penguins once again are the best \
hockey team in the NHL."),
};
println!("New article available! {}", article.summarize());
println!("-----------------");
let tweet = Tweet {
username: String::from("horse_ebooks"),
content: String::from("of course, as you probably already know"),
reply: false,
retweet: false,
};
println!("1 new tweet: {}", tweet.summarize());
}
默认实现允许调用相同 trait 中的其他方法,哪怕这些方法没有默认实现。为了使用这个版本的 Summary ,只需在实现 trait 时定义 summarize_author 即可
文件名:src/lib.rs
pub trait Summary {
fn summarize_author(&self) -> String;
// summarize_author并没有进行默认实现,但是在summarize里可以直接调用
fn summarize(&self) -> String {
format!("(Read more from {}...)", self.summarize_author())
}
}
pub struct Tweet {
pub username: String,
pub content: String,
pub reply: bool,
pub retweet: bool,
}
// 自定义实现summarize_author即可
impl Summary for Tweet {
fn summarize_author(&self) -> String {
format!("@{}", self.username)
}
}
文件名:src/main.rs
use _013_generics::{self, Summary, Tweet};
fn main() {
let tweet = Tweet {
username: String::from("horse_ebooks"),
content: String::from("of course, as you probably already know"),
reply: false,
retweet: false,
};
println!("1 new tweet: {}", tweet.summarize());
}
trait 作为参数
impl Trait 语法:适用于简单情况
// 定义Summary trait
pub trait Summary {
}
// 定义结构体并实现自定义Summary trait
pub struct NewsArticle {
}
impl Summary for NewsArticle {
}
pub struct Tweet {
}
impl Summary for Tweet {
}
// 实现了Summary这个Trait的类型才可以作为参数
// 1.impl Trait 语法
pub fn notify1(item: &impl Summary) {
println!("Breaking news! {}", item.summarize());
}
// 2.Trait Bound 语法
pub fn notify2<T: Summary>(item: &T) {
println!("Breaking news! {}", item.summarize());
}
// 实际上,impl trait 语法是 trait bound 的语法糖
// 约束参数类型拥有更多的 trait,使用 + 运算符即可
pub fn notify3(item: &(impl Summary + Display)) {
println!("Breaking news! {}", item.summarize());
}
pub fn notify4<T: Summary + Display>(item: &T) {
println!("Breaking news! {}", item.summarize());
}
// Trait bound 使用 where 子句
// 不使用 where
pub fn some_function1<T: Display + Summary, U: Clone + Debug>(t: &T, u: &U) -> String {
format!("Breaking news! {}", t.summarize())
}
// 使用 where
pub fn some_function2<T, U>(t: &T, u: &U) -> String
where
T: Display + Summary,
U: Clone + Debug,
{
format!("Breaking news! {}", t.summarize())
}
实现 largest 函数
使用 trait 编写求最大值的函数,约束类型拥有 PartialOrd trait,这样就能进行比较
关键词:切片 slice,解引用的使用,
// largest 函数的参数类型是 &[T],也就是说它接受一个切片(slice),而不是一个 Vec
// 编译后,参数变成 list: &[String]
fn largest<T: PartialOrd>(list: &[T]) -> &T {
let mut max_word: &T = &list[0];
// item应该是 &T类型,在本测试用例中即为 &String
for item in list.iter() {
if *item > *max_word {// item解引用后为 T 类型,本例中即为 String
max_word = item; // 将max_word这个借用更新为指向新的数据item
}
}
max_word
}
fn main() {
let str_list: Vec<String> = vec![String::from("hello"), String::from("world")];
let result = largest(&str_list);
println!("the largest word is {}", result);
}
trait 作为返回类型
返回值类型指定为 impl Summary
fn returns_summarizable() -> impl Summary {
Tweet {
username: String::from("horse_ebooks"),
content: String::from( "of course, as you probably already know, people"),
reply: false,
retweet: false,
}
}
注意:impl Trait 只能返回确定的一种类型,返回可能不同类型的代码会报错。也就是说:如果在 returns_summarizable() 函数中,编写的代码既可能返回 Tweet 也可能返回 NewsArticle ,这时是无法编译通过的。
使用 trait bound 有条件地实现方法
在使用泛型类型参数的 impl 块上使用 Trait bound,可以约束具有特定 trait 的类型才能拥有某些方法
use std::fmt::Display;
struct Pair<T> {
x: T,
y: T,
}
// 无论Pair<T>是什么类型,都实现了 new 这个关联函数
impl<T> Pair<T> {
fn new(x: T, y: T) -> Self {
Self { x, y }
}
}
// 针对Pair<T>,对 T 约束trait,必须同时实现了Display + PartialOrd两个trait
// 满足条件的类型 Pair<T>,才拥有方法 cmp_display
impl<T: Display + PartialOrd> Pair<T> {
fn cmp_display(&self) {
if self.x >= self.y {
println!("The largest member is x = {}", self.x);
} else {
println!("The largest member is y = {}", self.y);
}
}
}
约束类型具有某些 trait,才能拥有实现的 trait,这叫 覆盖实现(blanket implementations)
// 对拥有 Display trait 的类型,实现 ToString trait
impl<T: Display> ToString for T {
// --snip--
}
10.3 生命周期
生命周期的主要目标是避免悬垂引用(dangling references)。
fn main() {
let r;
{
let x = 5;
r = &x;
} // r 引用的值在尝试使用之前就离开了作用域
println!("r: {}", r);
}
上述代码是无法编译通过的
Rust 编译器有一个 借用检查器(borrow checker),它比较作用域来确保所有的借用都是有效的。
fn main() {
let r; // ---------+-- 'a
// |
{ // |
let x = 5; // -+-- 'b |
r = &x; // | |
} // -+ |
// |
println!("r: {}", r); // |
} // ---------+
r 和 x 的生命周期注解,分别叫做 'a 和 'b,可以看出被引用的对象比它的引用者存在的时间更短。
生命周期的标注
- 生命周期的标注不会改变引用生命周期长度
- 当指定了泛型生命周期参数,函数可以接收带有任何生命周期的引用
- 生命周期的标注:描述了多个引用的生命周期间的关系,但不影响生命周期
语法:
- 以
'开头,通常全小写且非常短,例如'a - 在引用的
&符号后 - 使用空格将标注和引用类型分开
例子:
&i32 // 没有生命周期参数的引用
&'a i32 // 带有显式生命周期的引用
&'a mut i32 // 带有显式生命周期的可变引用
单个的生命周期注解本身没有多少意义,因为生命周期注解告诉 Rust 多个引用的泛型生命周
期参数如何相互联系的。
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {}", result);
}
// 在函数名后使用<>标注生命周期
// 这表示参数x,y和返回值,这些引用都有相同的生命周期
// 进行生命周期标注,并没有改变任何传入值或返回值的生命周期,而是指出任何不满足这个约束条件的值都将被借用检查器拒绝
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}
通过传递拥有不同具体生命周期的引用来限制 longest 函数的使用:
'a 的实际含义是 longest 函数返回的引用的生命周期与函数参数所引用的值的生命周期的较小者一致
fn main() {
let string1 = String::from("long string is long");
let result;
{
let string2 = String::from("xyz");
result = longest(string1.as_str(), string2.as_str());
}// string2在此处失效,而result是与传入参数生命周期较小者保持一致,因此result也在此处失效
println!("The longest string is {}", result);
}
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}
深入理解生命周期
如果返回值固定为 x,那么就不需要指定参数 y 的生命周期了
fn longest<'a>(x: &'a str, y: &str) -> &'a str {
x
}
当从函数返回一个引用,返回值的生命周期需要与一个参数的生命周期相匹配。如果返回的引用 没有指向任何一个参数,那么唯一的可能就是它指向一个函数内部创建的值。然而它将会是一个悬垂引用,因为它将会在函数结束时离开作用域。
fn longest<'a>(x: &str, y: &str) -> &'a str {
let result = String::from("really long string");
result.as_str()
}
// longest 函数的结尾将离开作用域并被清理,而我们尝试从函数返回一个 result 的引用
//无法指定生命周期参数来改变悬垂引用,而且 Rust 也不允许我们创建一个悬垂引用
// 这时我们可以直接返回这个值,把所有权移交给函数的调用者
fn longest<'a>(x: &str, y: &str) -> String {
let result = String::from("really long string");
result
}
综上,生命周期语法是用于将函数的多个参数与其返回值的生命周期进行关联的。一旦它们形成了某种关联,Rust 就有了足够的信息来允许内存安全的操作并阻止会产生悬垂指针亦或是违反内存安全的行为。
结构体定义中的生命周期标注
Struct 里可包括:
- 自持有的类型(i32,String…)
- 引用:需要在每个引用上添加生命周期的标注
struct ImportantExcerpt<'a> {
part: &'a str,
}
fn main() {
let novel = String::from("Call me Ishmael. Some years ago...");
let first_sentence = novel.split('.').next().expect("Could not find a '.'");
// first_sentence 这个被引用者的生命周期可以覆盖 i 这个结构体的生命周期,因此编译可以通过
let i = ImportantExcerpt {
part: first_sentence,
};
}
生命周期的省略
这个函数没有声明生命周期,但编译能通过,这是因为 rust 编译器考虑了一些特殊场景,这些场景是可预测的并且遵循几个明确的模式。如此借用检查器在这些情况下就能推断出生命周期而不再强制程序员显式的增加注解。
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
生命周期省略规则不会提供完整的推断:
- 如果应用规则后,引用的生命周期仍然模糊不清
->编译错误 - 解决办法:手动添加生命周期标注,表面引用间的相互关系
输入、输出生命周期
输入生命周期:在函数/方法的参数中
输出生命周期:在函数/方法的返回值中
生命周期省略的三个规则
- 规则 1:每个引用类型的参数都有自己的生命周期(函数有几个引用参数就有几个生命周期)
- 规则 2:如果只有 1 个输入生命周期参数,那么该生命周期被赋给所有的输出生命周期参数
- 规则 3:如果有多个输入生命周期参数,但其中一个是
&self或&mut self(是方法),那么self的生命周期会给赋给所有的输出生命周期参数
编译器使用 3 个规则在没有显示标注生命周期的情况下,来确定引用的生命周期
- 规则 1 应用于输入生命周期
- 规则 2、3 应用与输出生命周期
- 如果编译器应用完 3 个规则之后,仍然有无法确定生命周期的引用
->就会报错 - 这些规则适用于 fn 定义和 impl 块
方法定义中的生命周期标注
在 struct 上使用生命周期实现方法,语法和泛型参数的语法一样
在哪声明和使用生命周期参数,依赖于:生命周期参数是否和字段、方法的参数或返回值有关
struct 字段的生命周期名:
- 在 impl 后声明
- 在 struct 名后使用
- 这些生命周期是 struct 类型一部分
impl 块内的方法签名中:
- 引用必须绑定于 struct 字段引用的生命周期,或者引用是独立的也可以
- 生命周期的省略规则经常使得方法中的生命周期标注不是必须的
struct ImporExcerpt<'a> {
part: &'a str,
}
impl<'a> ImportantExcerpt<'a> {
// 根据第一条省略规则,我们可以不用为方法中的self引用标注生命周期
fn level(&self) -> i32 {
3
}
// 这里有两个输入生命周期,所以Rust通过应用第一条生命周期省略规则给了&self和announcement各自的生命周期
// 由于其中一个参数是&self,返回类型被赋予了&self的生命周期
// 因此所有的生命周期就都被计算出来了
fn announce_and_return_part(&self, announcement: &str) -> &str {
println!("Attention please: {}", announcement);
self.part
}
}
静态生命周期
'static 是一个特殊的生命周期:整个程序的持续时间。
例如:所有的字符串字面值都拥有 'static 生命周期
let s: &'static str = "I have a static lifetime.";
为引用指定 'static 生命周期前要三思:是否需要引用在程序整个生命周期内都存活。
use std::fmt::Display;
fn longest_with_an_announcement<'a, T>(x: &'a str, y: &'a str, ann: T) -> &'a str
where T: Display
{
println!("Announcement! {}", ann);
if x.len() > y.len() {
x
} else {
y
}
}
11 自动化测试
// 创建一个新的库项目 adder
cargo new adder --lib
// 运行测试
cargo test
// 0 measured 统计是针对性能测试的;0 filtered out 是指没有过略掉任何测试
使用 assert! 宏检查测试结果
assert! 宏来自标准库,用来确定某个状态是否为 true;测定为 false 时,调用 panic!
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*; // 使用 super 允许我们引用父模块中的已知项
#[test]
fn larger_can_hold_smaller() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
}
assert_eq! 和 assert_ne! 俩个宏分别用来判断两个参数是否相等 或 不等,相当于用 assert! 宏加 == 或 != 来判断,使用这两个宏的好处是:断言失败时,自动打印出两个参数的值,这也要求了参数必须实现了 PartalEq 和 Debug Traits (所有基本类型和标准库里大部分都实现了)
可以传递一个可选的失败信息参数,可以在测试失败时将自定义失败信息一同打印出来。
验证代码发生错误,should_panic
发生 panic 时,测试通过,否则测试不通过
expect 函数用来具会确保错误信息中包含其提供的文本
pub struct Guess {
value: i32,
}
// --snip--
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!(
"Guess value must be greater than or equal to 1, got {}.", value);
} else if value > 100 {
panic!(
"Guess value must be less than or equal to 100, got {}.", value);
}
Guess { value }
}
}
# [cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "less than or equal to 100")]
// 发生 panic 时,错误信息必须包含该字符串,才能算通过测试
fn greater_than_100() {
Guess::new(200);
}
}
使用 Result<T, E>
无需 panic,使用 Result<T, E> 作为返回类型编写测试:Ok 测试通过,Err 测试失败
#[cfg(test)]
mod tests {
#[test]
fn it_works() -> Result<(), String> {
if 2 + 2 == 4 {
Ok(())
} else {
Err(String::from("two plus two does not equal four"))
}
}
}
因为使用 Result 无需发生 panic,因此此时不要使用 #[should_panic]
控制测试如何运行
改变 cargo test 的行为:添加命令行参数
默认行为:并行运行所有测试,不显示所有输出
命令行参数:
针对 cargo test 的参数,紧跟在 cargo test 后
针对 测试可执行程序:放在 -- 后
cargo test --help :提示 cargo test 的有关参数
cargo test -- --help :提示在分隔符后能够使用的有关参数
cargo test -- --test-threads=1:将测试线程设置为 1 ,告诉程序不要使用任何并行机制。在有共享的状态时,测试就不会潜在的相互干扰。
默认情况下,当测试通过时,Rust 的测试库会截获打印到标准输出的所有内容。如果测试失败了,则会看到所有标准输出和其他错误信息。但是如果我们也想看到成功时的输出,就可以使用下边的命令:
cargo test -- --show-output :显示成功测试的输出
指定只运行某个测试
pub fn add_two(a: i32) -> i32 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn add_two_and_two() {
assert_eq!(4, add_two(2));
}
#[test]
fn add_three_and_two() {
assert_eq!(5, add_two(3));
}
#[test]
fn one_hundred() {
assert_eq!(102, add_two(100));
}
}
只运行名为 one_hundred 的测试
cargo test one_hundred
// test tests::one_hundred ... ok
只运行 tests 模块里的测试
cargo test tests
/*
test tests::add_three_and_two ... ok
test tests::add_two_and_two ... ok
test tests::one_hundred ... ok
*/
运行 add 开头的测试
cargo test add
/*
test tests::add_three_and_two ... ok
test tests::add_two_and_two ... ok
*/
忽略某些测试
给要忽略的测试加上 ignore 属性
#[test]
#[ignore]
fn add_three_and_two() {
assert_eq!(5, add_two(3));
}
// 执行 cargo test
/*
test tests::add_three_and_two ... ignored
test tests::add_two_and_two ... ok
test tests::one_hundred ... ok
*/
执行完这些测试,又想执行具有 ignore 属性的测试,注意是命令行里的参数是 ignored 而不是 ·ignore
cargo test -- --ignored
测试的分类
- 单元测试
-
- 小、专注
-
- 一次对一个模块进行隔离的测试
-
- 可测试 private 接口
- 集成测试
-
- 在库外部。和其他外部代码一样使用你的代码
-
- 只能使用 public 接口
-
- 可能在每个测试中使用到多个模块
单元测试
测试模块和 #[cfg(test)]
#[cfg(test)] 注解告诉 Rust 只在执行 cargo test 时才编译和运行 tests 模块的测试代码,而在运行 cargo build 时不这么做
集成测试在不同的目录,它不需要 #[cfg(test)] 标注
cfg: configuration (配置)
- 告诉 rust 下面的条目只有在指定的配置选项下才被包含
- 配置选项 test:由 rust 提供,用来编译和运行测试。
集成测试
在 rust 中,集成测试完全位于被测试库的外部,目的是测试被测试库的多个部分是否能正确的一起工作,集成测试的覆盖率很重要。
tests 目录
为了编写集成测试,需要在项目根目录创建一个 tests 目录,与 src 同级。Cargo 知道如何去寻找这个目录中的集成测试文件。接着可以随意在这个目录中创建任意多的测试文件,Cargo 会将每一个文件当作单独的 crate 来编译。只有调用 cargo test 命令时,才会编译 tests 目录下的文件。
运行指定的集成测试
- 运行一个特定的集成测试:cargo test 函数名
- 运行某个测试文件内的所有测试:cargo test --test 文件名
集成测试的子模块
直接在 tests 目录下创建 common.rs 会导致被 rust 认为是测试代码,tests 目录中的子目录不会被作为单独的 crate 编译或作为一个测试结果部分出现在测试输出中。一旦拥有了 tests/common/mod.rs,就可以将其作为模块以便在任何集成测试文件中使用。
二进制 crate 的集成测试
如果项目是二进制 crate 并且只包含 src/main.rs 而没有 src/lib.rs
- 不能在 tests 目录创建集成测试
- 无法把
src/main.rs的函数导入作用域,因为只有库 crate 才会向其他crate 暴露了可供调用和使用的函数 - 二进制 crate 意味着单独运行
这就是许多 Rust 二进制项目使用一个简单的 src/main.rs 调用 src/lib.rs 中的逻辑的原因之一。因为通过这种结构,集成测试 就可以 通过 extern crate 测试库 crate 中的主要功能了,而如果这些重要的功能没有问题的话,src/main.rs 中的少量代码也就会正常工作且不需要测试。
12 项目实例:命令行程序
重构改进模块性和错误处理
为了改善我们的程序这里有四个问题需要修复,而且它们都与程序的组织方式和如何处理潜在错误有关。
- 第一,main 现在进行了两个任务:它解析了参数并打开了文件。对于一个这样的小函数,这并不是一个大问题。然而如果 main 中的功能持续增加,main 函数处理的独立任务也会增加。当函数承担了更多责任,它就更难以推导,更难以测试,并且更难以在不破坏其他部分的情况下做出修改。最好能分离出功能以便每个函数就负责一个任务。
- 这同时也关系到第二个问题:query 和 file_path 是程序中的配置变量,而像 contents 则用来执行程序逻辑。随着 main 函数的增长,就需要引入更多的变量到作用域中,而当作用域中有更多的变量时,将更难以追踪每个变量的目的。最好能将配置变量组织进一个结构,这样就能使它们的目的更明确了。
- 第三个问题是如果打开文件失败我们使用 expect 来打印出错误信息,不过这个错误信息只是说 Should have been able to read the file 。读取文件失败的原因有多种:例如文件不存在,或者没有打开此文件的权限。目前,无论处于何种情况,我们只是打印出“文件读取出现错误”的信息,这并没有给予使用者具体的信息!
- 第四,我们不停地使用 expect 来处理不同的错误,如果用户没有指定足够的参数来运行程序,他们会从 Rust 得到 index out of bounds 错误,而这并不能明确地解释问题。如果所有的错误处理都位于一处,这样将来的维护者在需要修改错误处理逻辑时就只需要考虑这一处代码。将所有的错误处理都放在一处也有助于确保我们打印的错误信息对终端用户来说是有意义的。
让我们通过重构项目来解决这些问题。
二进制项目关注点分离的指导性原则
- 将程序拆分成
main.rs和lib.rs并将程序的业务逻辑放入lib.rs中。 - 当命令行解析逻辑比较少时,可以保留在
main.rs中。 - 当命令行解析开始变得复杂时,也同样将其从
main.rs提取到lib.rs中。
程序已经编写了测试代码,并添加了大小写敏感的环境变量检测代码
文件名: src/main.rs
use std::env;// 一般只引入至父模块即可,使用时,env::args()
use std::process;
use _010_miniGrep::Config;
use _010_miniGrep::run;
fn main() {
// 使用collect函数产生集合,但需要显示指明变量的集合类型,这里为Vec<String>
let args: Vec<String> = env::args().collect();
// env::args()函数无法处理非法的unicode字符,可以使用args_os()
// println!("{:?}", args); // 打印输入的参数列表
let config = Config::new(&args).unwrap_or_else(|err| {
// 标准错误输出函数,会将错误输出到终端上,而不是output.txt文件里,这样就将错误和输出分开了
eprintln!("Problem parsing arguments: {}", err);
process::exit(1);
});
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
文件名: src/lib.rs
use std::error::Error;
use std::fs;// 处理文件相关的事务
use std::env;
// ()表示空元组,什么都不返回
// 否则返回一个实现了 error 这个trait的类型,可以理解为 “任何类型的错误”
pub fn run(config: Config) -> Result<(), Box<dyn Error> > {
// 使用 ? 运算符传播错误,当Err发生时,会return Err,否则会返回()空元组
let contents = fs::read_to_string(config.filename)?;
let res = if config.case_sensitive {
search_case_sensitive(&config.query, &contents)
} else {
search_case_insensitive(&config.query, &contents)
};
for line in res {
println!("{line}");
}
Ok(())
}
// 改进模块
pub struct Config {
pub query: String,
pub filename: String,
pub case_sensitive: bool,
}
impl Config {
pub fn new(args: &[String]) -> Result<Config, &'static str> {
// 这里的 args 是指向 Vec<String> 的切片
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let filename = args[2].clone();
// env::var()函数检测环境变量,并返回result<>,调用 is_err() 检查该环境变量是否被设置
// 如果没有被设置,就是err,函数即为返回true,true 对应的是调用 case_sensitive
let case_sensitive = env::var("CASE_INSENSITIVE").is_err();
Ok(Config {query, filename, case_sensitive})
}
}
// 使用search在contents中寻找包含duct字符串的行,并返回所有行
pub fn search_case_sensitive<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut res = Vec::new();
for line in contents.lines() {
if line.contains(query) {
res.push(line);
}
}
res
}
pub fn search_case_insensitive<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut res = Vec::new();
let query = query.to_lowercase();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
res.push(line);
}
}
res
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search_case_sensitive(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUst";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents));
}
}
// 进行测试
cargo run to poem.txt
/* 输出
Are you nobody, too?
How dreary to be somebody!
*/
// 设置环境变量存在,实际上代码的逻辑是:检测到此环境变量存在,就会认为大小写不敏感
$env:CASE_INSENSITIVE=1
// 进行测试
cargo run to poem.txt
/* 输出
Are you nobody, too?
How dreary to be somebody!
To tell your name the livelong day
To an admiring bog!
*/
// 将环境变量移除
Remove-Item Env:\CASE_INSENSITIVE