在实际的生产中,在训练时面对的压力主要是模型太大,无法装载进一块GPU中。
举一个例子,一般来讲现代LLM训练采用的精度都是FP16或者BF16,采用这种精度来训练模型,如果1个模型参数,要占用2个字节,也就是16bit。
在上一章开头的7B案例已经讲过,如果对一个7B模型用BF16或者FP16来进行预训练那么现在市面上最高显存的GPU,如H100/80G也是无法进行装载的。因此由于这个物理上的硬件限制,在训练时我们都会进行模型并行化处理。
何为模型并行化,总体来说分为纵向和横向的模型并行化拆分,即:
流水线并行PP(Pipeline Parallelism)
Tensor并行TP (Tensor Parallelism)
流水线并行
流水线并行PP(Pipeline Parallelism),是一种最常用的并行方式,也是最初Deepspeed和Megatron等大模型训练框架都支持的一种并行方式。
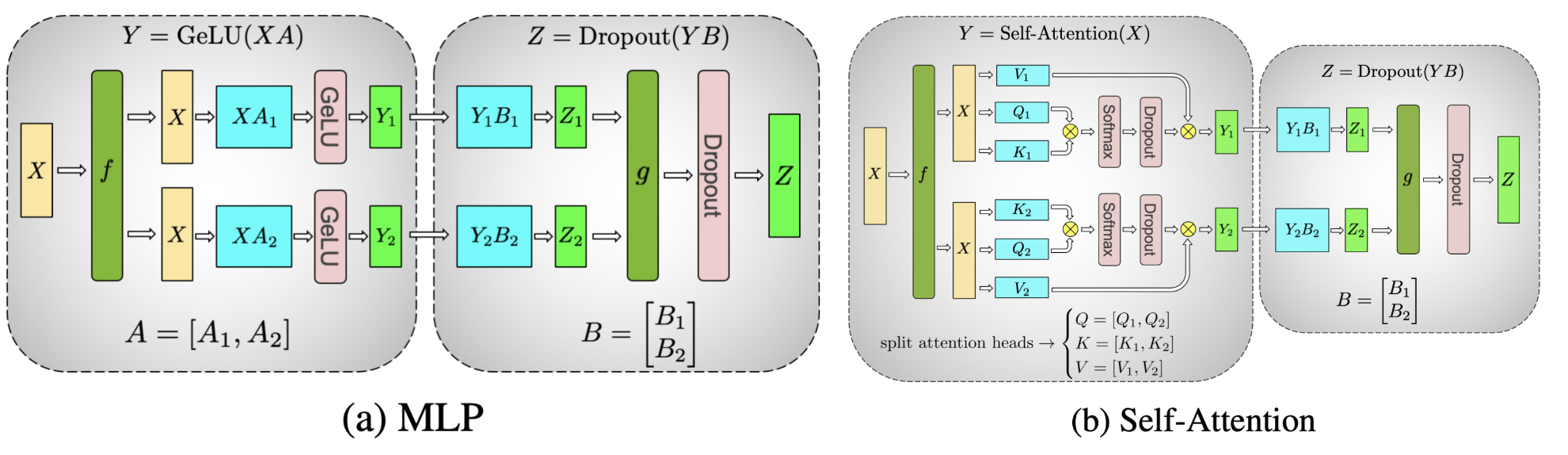
什么是流水线并行呢?简而言之是把一个参数量较大的模型按照不同的层进行划分,将多个模型的层尽可能均匀的分布在不同的GPU显存上,来起到装载更大模型的能力。
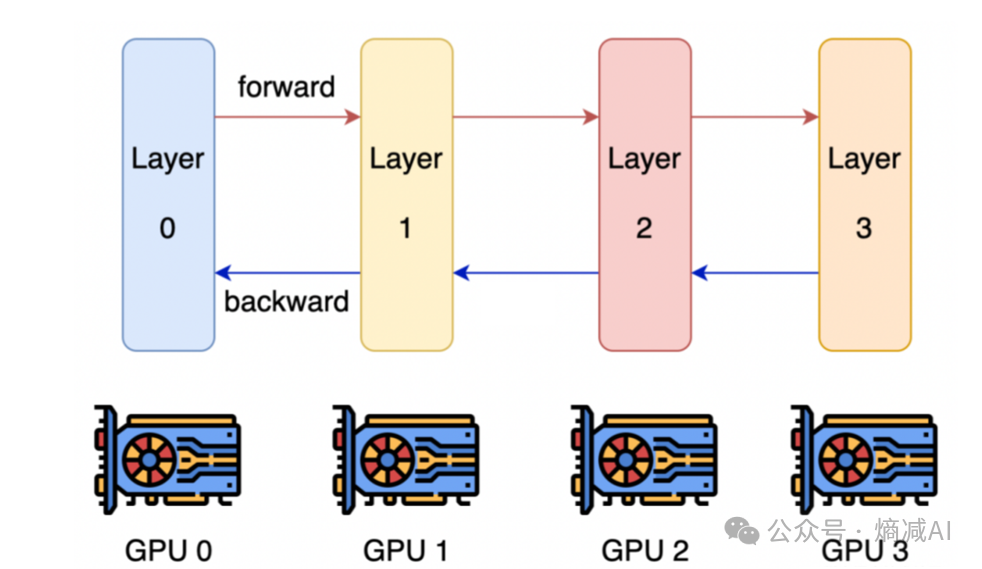
PP的通信和运行方式
如图所示,假设一个大模型有4层,采用PP的方式,可



















![[[音视频学习笔记]四、ACC格式及音频码流](https://img-blog.csdnimg.cn/direct/ca81d9513f86409c8ecb21b35f459a2c.png)