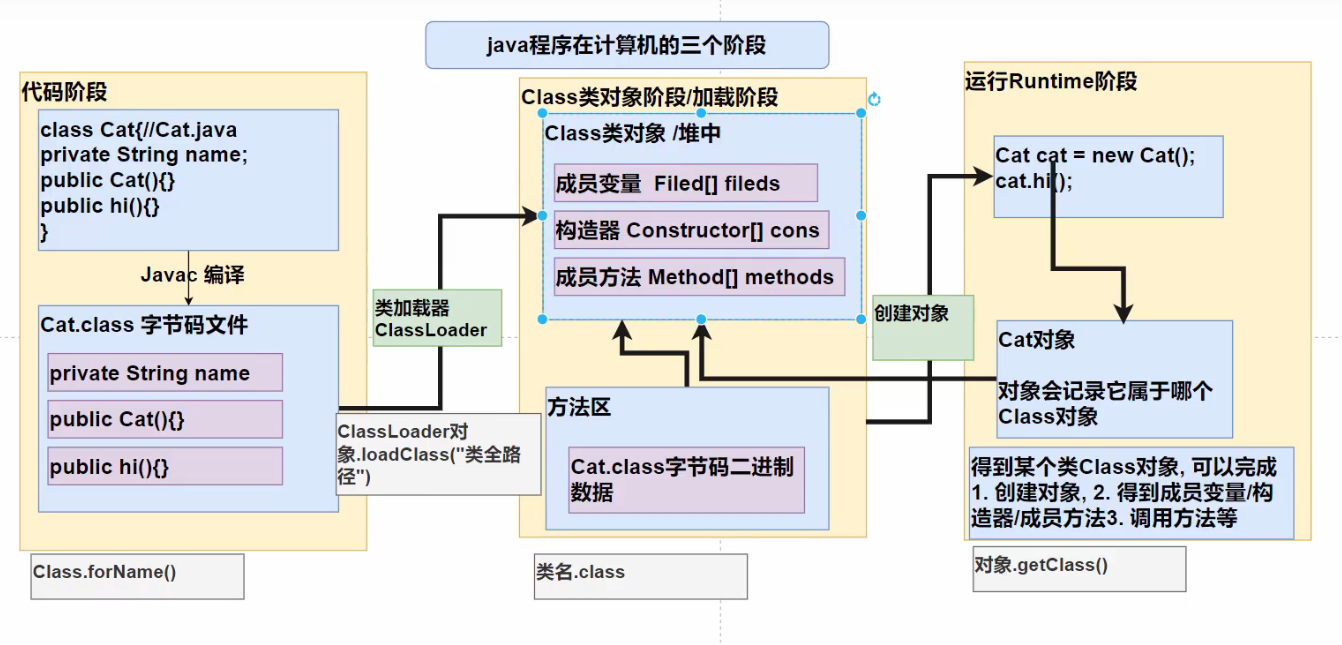
基本概念
概率论是数学的一个分支,它专注于分析和理解随机现象。通过概率论,我们可以量化不确定性,预测事件发生的可能性,并对复杂系统进行建模和分析。以下是一些概率论的基本概念和原理:
概率的定义
- 经典定义:当所有基本事件发生的可能性相同时,某事件发生的概率等于该事件所包含的基本事件数除以所有基本事件的总数。
- 频率定义:某事件发生的概率等于在大量重复试验中,该事件发生的次数占总试验次数的比例,当试验次数趋于无穷时,这个比例趋近于一个稳定值。
- 主观概率:基于个人信念或经验对事件发生可能性的度量。
随机变量
- 随机变量:在概率实验中,随机变量是一个可以取不同值的变量,其取值结果由随机过程决定。
- 离散随机变量:取值有限或可数无限集合的随机变量,例如掷骰子的结果。
- 连续随机变量:取值为连续区间的随机变量,例如某地区一天内的降雨量。
概率分布
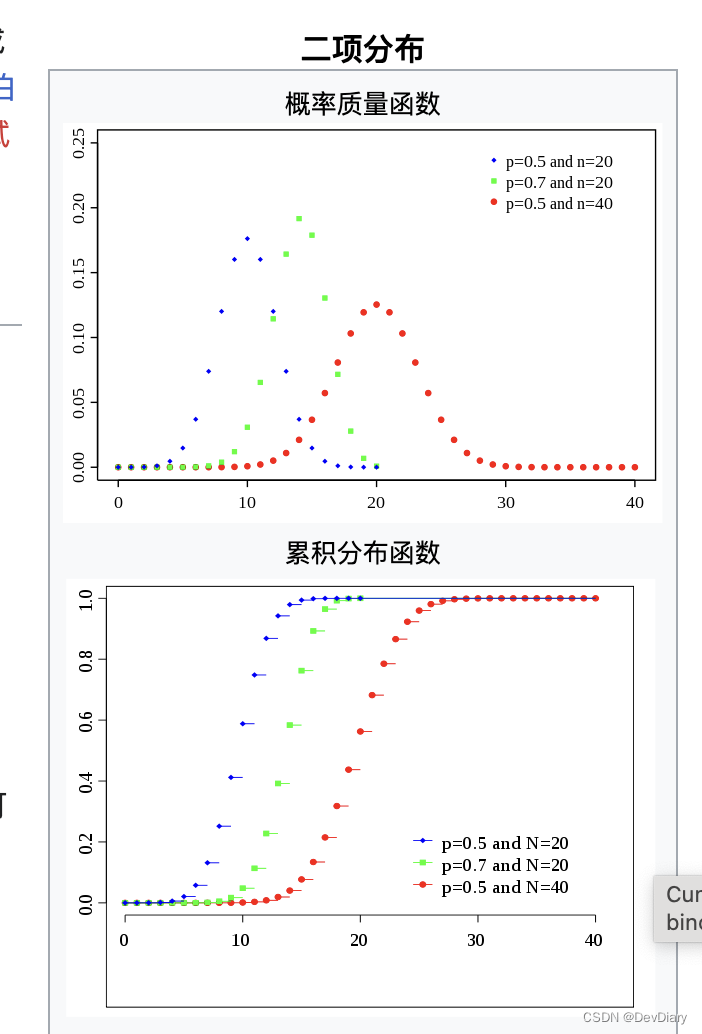
- 离散概率分布:描述离散随机变量的所有可能取值及其对应概率的函数。常见的离散概率分布有二项分布、泊松分布等。
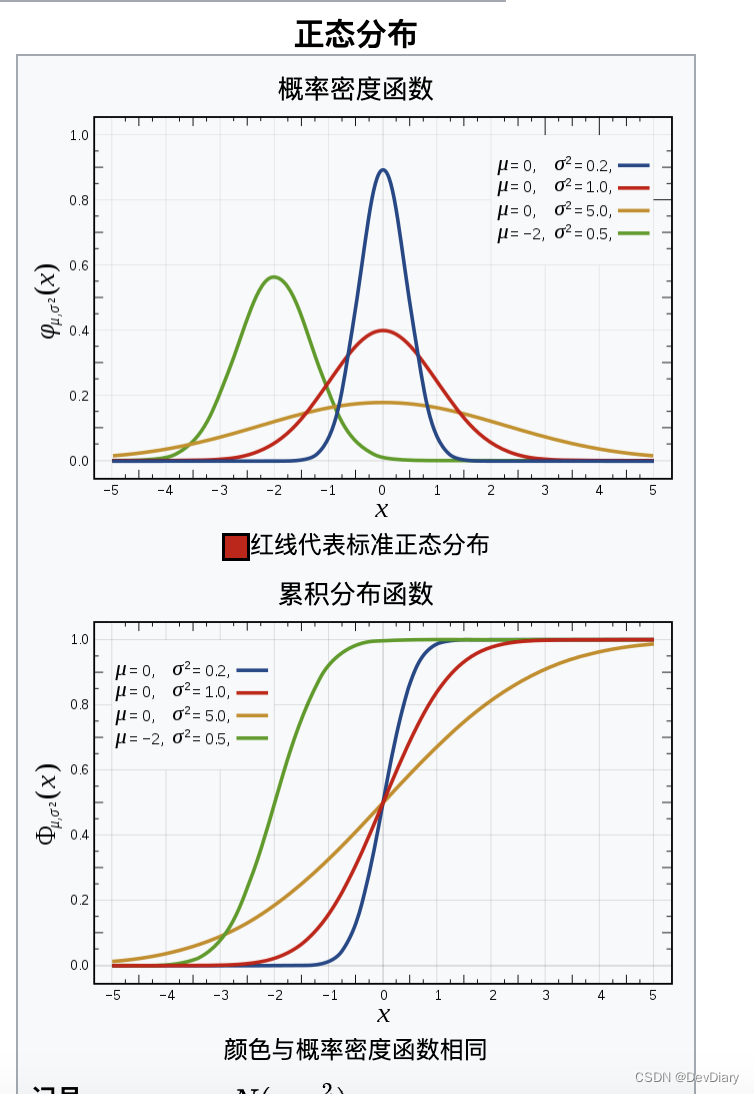
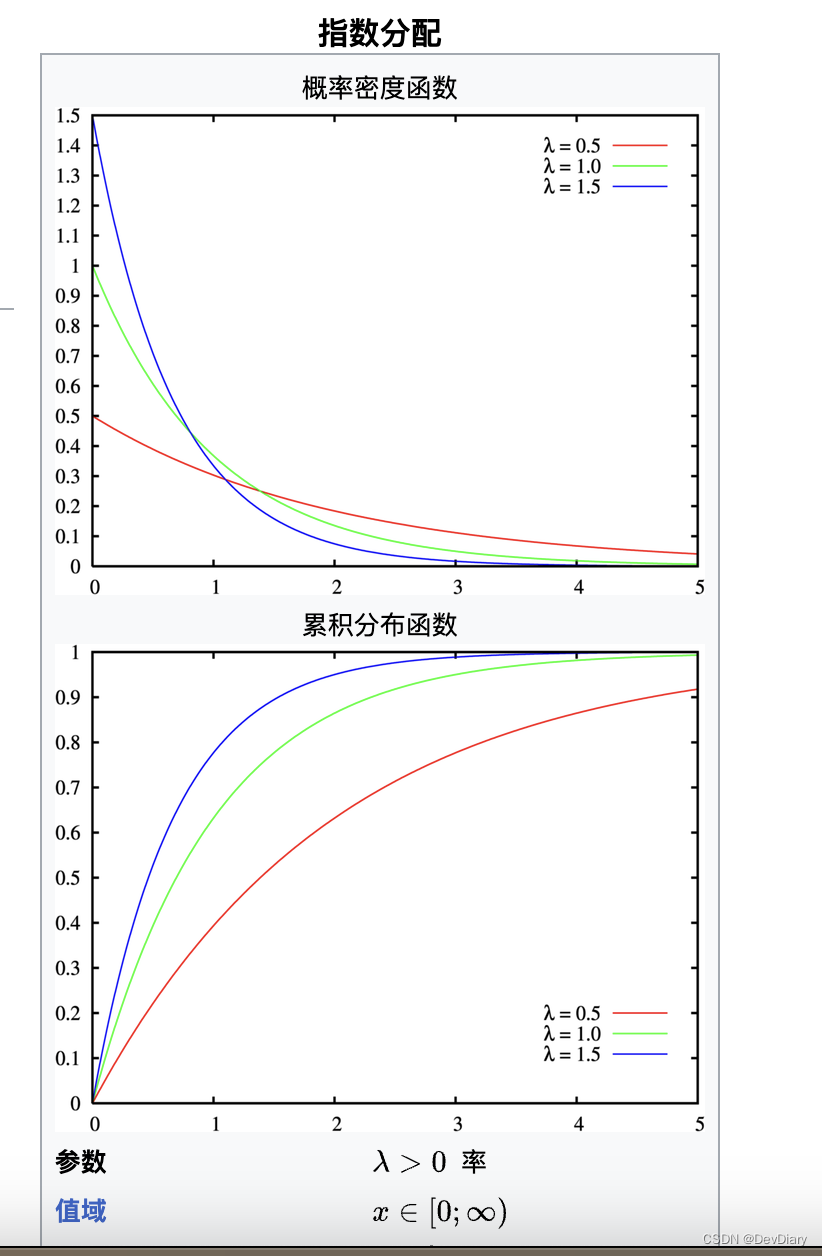
- 连续概率分布:描述连续随机变量的概率密度函数(PDF),用于计算变量在特定区间内取值的概率。常见的连续概率分布有正态分布(高斯分布)、指数分布等。
- 概率分布图形

概率的性质
- 加法规则:两个互斥事件A和B发生的概率等于各自发生的概率之和。
- 乘法规则:两个独立事件A和B同时发生的概率等于各自发生的概率的乘积。
- 条件概率:事件A在另一个事件B已经发生的条件下发生的概率,记为P(A∣B)。
期望和方差
- 期望(数学期望,均值):随机变量可能取值的加权平均,权重即为各值的概率。反映了随机变量取值的“中心”位置。
- 方差:衡量随机变量取值与其期望值之间差异的度量,反映了随机变量取值的“分散”程度。
大数定律和中心极限定理
- 大数定律:在重复独立试验中,随着试验次数的增加,样本均值以概率收敛于总体期望值。
- 中心极限定理:在适当条件下,大量独立同分布的随机变量之和,其归一化形式趋近于正态分布,无论原始随机变量的分布如何。
概率论为我们提供了一套强大的工具,使我们能够在不确定性中做出推断和决策。它在保险、金融、工程、科学研究等多个领域中都有着广泛的应用。
在AI中的应用
贝叶斯定理
在机器学习中,尤其是在贝叶斯网络和垃圾邮件过滤器等领域中,用于更新模型的信念或概率贝叶斯定理是概率论中的一个核心概念,它提供了一种在已知某些信息的情况下,如何更新或计算事件概率的方法。这一理论在人工智能(AI)尤其是在机器学习领域中有着广泛的应用,包括贝叶斯网络、垃圾邮件过滤、医学诊断、自然语言处理等多个方面。
贝叶斯定理的公式

在AI中的应用
贝叶斯网络
贝叶斯网络(也称为信念网络或贝叶斯模型)是一种表示变量间依赖关系的图形模型。通过贝叶斯定理,我们可以利用已知的某些变量的观测值来推断其他变量的概率。这在处理复杂系统中的不确定性时非常有用。
垃圾邮件过滤
垃圾邮件过滤器利用贝叶斯定理通过分析邮件内容来判断一封邮件是否为垃圾邮件。这涉及到计算给定邮件内容的条件下,邮件为垃圾邮件的概率,并根据这一概率来进行分类。
医学诊断
在医学诊断中,贝叶斯定理可以用来根据某些症状出现的条件下,计算患有某种疾病的概率。这对于基于症状和医学检测结果做出诊断决策非常有用。
自然语言处理
在自然语言处理(NLP)领域,贝叶斯定理常用于文本分类、情感分析等任务中,通过分析文本特征来计算文本属于某个类别的概率。
结论
贝叶斯定理通过结合先验知识和新的观测数据来更新我们对事件概率的估计,这在AI中尤其有价值,因为它允许模型不断学习和适应新信息。这种基于概率的推理方式为处理不确定性、做出预测和决策提供了强有力的工具。
概率分布(如二项分布、正态分布等)
概率分布在人工智能(AI)领域,尤其是在数据分析、假设测试和机器学习模型的建立中发挥着核心作用。它们提供了一种系统的方法来描述和预测数据中的不确定性和变异性。下面是一些具体的应用场景:
数据分析
在数据分析过程中,了解数据的分布是基本步骤之一。不同类型的数据可能遵循不同的概率分布,例如:
- 正态分布:许多自然和社会科学现象呈现正态分布(或接近正态分布),如人的身高、测量误差等。正态分布的性质和中心极限定理使得它在统计推断中非常重要。
- 二项分布:用于描述在固定次数的独立实验中,观察到某事件发生次数的分布,如抛硬币得到正面的次数。
通过识别数据遵循的概率分布,我们可以更好地理解数据的特性,进行适当的统计推断,并应用正确的统计方法进行分析。
假设测试
假设测试是统计学中用来判断数据是否支持某个假设的方法。许多假设测试方法都基于特定的概率分布假设,例如:
- t检验:在小样本情况下,比较两组数据的均值差异时,常假设数据遵循正态分布。
- 卡方检验:用于检验分类变量的观测频数与期望频数之间的差异,依赖于卡方分布。
概率分布是进行假设测试和统计推断的基础,它们帮助我们量化在假定背景下观测到数据的概率,从而做出是否拒绝原假设的决策。
机器学习模型的建立
概率分布在机器学习模型的设计和评估中扮演着重要角色。例如:
- 生成模型:如朴素贝叶斯分类器,直接基于训练数据的概率分布进行预测。它需要估计特征给定类别的条件概率分布。
- 回归分析:线性回归和逻辑回归等模型的建立和评估常常依赖于正态分布假设,通过最大似然估计等方法来估计模型参数。
- 深度学习:在训练深度学习模型时,初始化权重通常会采用服从特定概率分布的随机数(如正态分布或均匀分布),以帮助模型更好地收敛。
此外,概率分布还用于描述模型的不确定性、评估模型性能(如置信区间)和进行概率预测。
总之,概率分布是AI中理解数据、构建假设、设计和评估模型不可或缺的工具。它们使得我们能够在处理不确定性和变异性时做出基于概率的推理和决策。