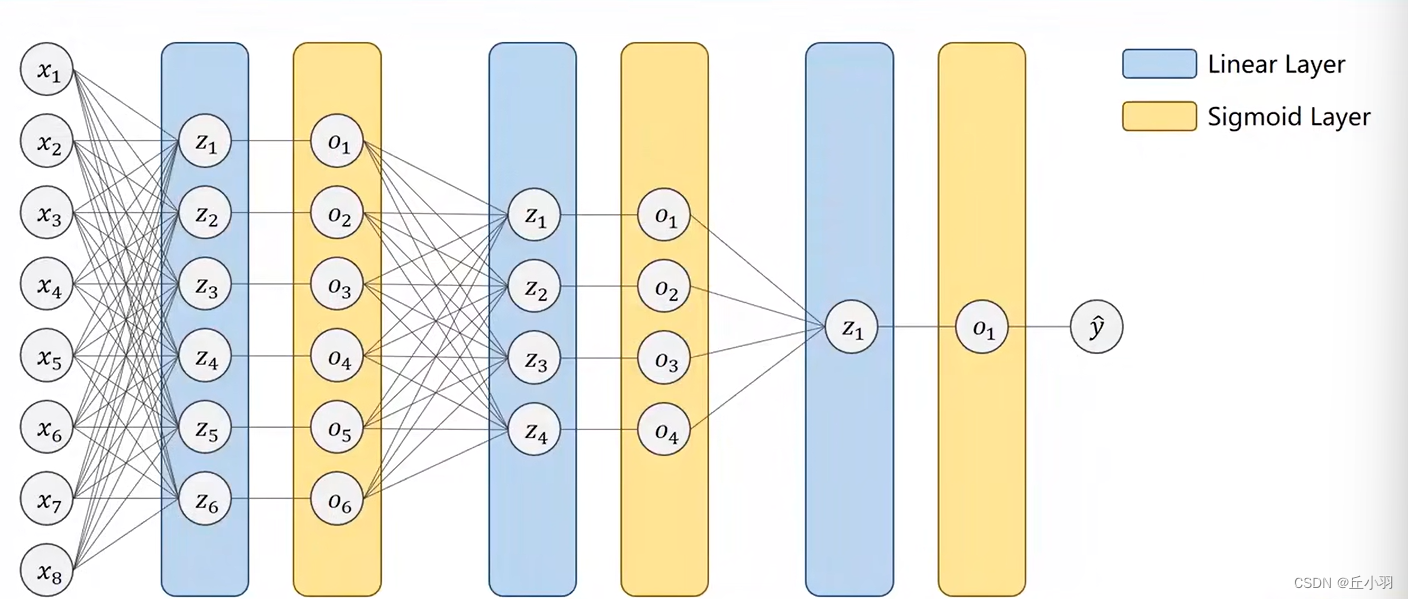
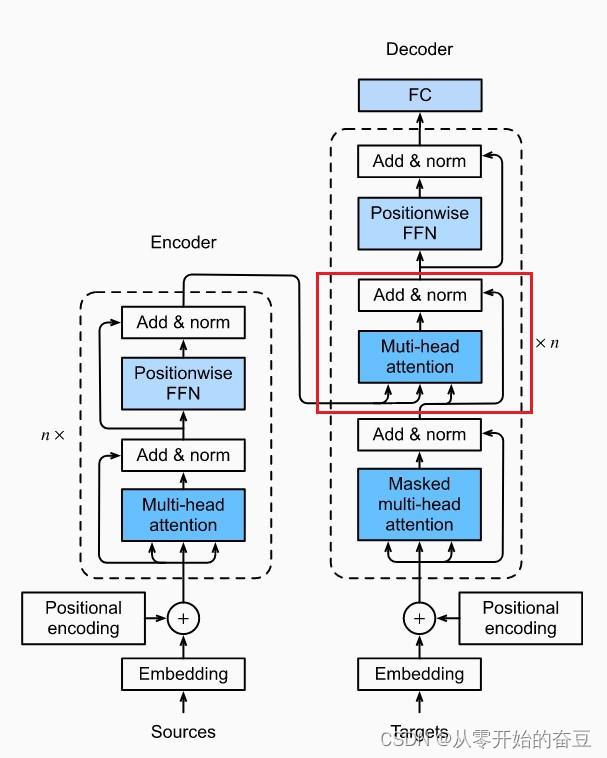
transformer的原理部分在前面基本已经介绍完了,接下来就是代码部分,因为transformer可以做的任务有很多,文本的分类、时序预测、NER、文本生成、翻译等,其相关代码也会有些不同,所以会分别进行介绍
但是对于不同的任务其流程是一样的,所以一些重复的步骤就不过多解释了。
1、 前期准备
数据和之前LSTM是一样的,同时我们还使用上次训练好的词嵌入模型
以下是代码
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import numpy as np
from gensim.models import KeyedVectors
from sklearn.model_selection import train_test_split
import pandas as pd
import jieba
import re
from sklearn.preprocessing import LabelEncoder
# 加载数据
file_path = './data/news.csv'
data = pd.read_csv(file_path)
# 显示数据的前几行
data.head()
# 文本清洗和分词函数
def clean_and_cut(text):
# 删除特殊字符和数字
text = re.sub(r'[^a-zA-Z\u4e00-\u9fff]', '', text)
# 使用jieba进行分词
words = jieba.cut(text)
return ' '.join(words)
X_train_cut = data["text"].apply(clean_and_cut)
# 显示处理后的文本
data.head()
# 将标签转换为数值形式
label_encoder = LabelEncoder()
data["label"] = label_encoder.fit_transform(data["label"])
# 加载保存的word vectors
loaded_wv = KeyedVectors.load('word_vector', mmap='r')
class Word2VecDataset(Dataset):
def __init__(self, texts, labels, word2vec, max_len=100):
self.texts = texts
self.labels = labels
self.word2vec = word2vec
self.max_len = max_len
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = self.texts[idx]
label = self.labels[idx]
embeds = [self.word2vec[word] if word in self.word2vec else np.zeros(self.word2vec.vector_size) for word in text]
if len(embeds) > self.max_len:
embeds = embeds[:self.max_len]
else:
embeds += [np.zeros(self.word2vec.vector_size) for _ in range(self.max_len - len(embeds))]
return torch.tensor(embeds, dtype=torch.float), torch.tensor(label, dtype=torch.long)
# texts和labels是数据集中的文本和标签列表
texts = X_train_cut.tolist()
labels = data['label'].tolist()
# 划分数据集
train_texts, test_texts, train_labels, test_labels = train_test_split(texts, labels, test_size=0.2)
2、位置编码和主模型
import math
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=100):
super(PositionalEncoding, self).__init__()
# 创建一个位置编码矩阵
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0) # (1, max_len, d_model)
self.register_buffer('pe', pe)
def forward(self, x):
# x: (batch_size, max_len, d_model)
x = x + self.pe.expand(x.size(0), -1, -1)
return x
2.1 PositionalEncoding 类
这个类用于创建和提供位置编码。位置编码是 Transformer 模型中用于注入序列中单词的位置信息的机制。这种位置信息对于模型理解单词的顺序很重要。
初始化方法 __init__
d_model:模型的维度,也是词嵌入的维度。max_len:序列的最大长度。pe:位置编码矩阵,大小为(1, max_len, d_model)。这个矩阵被注册为一个缓冲区,这意味着它会被保存和加载与模型的其他参数一起。
前向传播方法 forward
- 输入
x的形状是(batch_size, max_len, d_model)。 self.pe.expand(x.size(0), -1, -1):这个操作将位置编码矩阵扩展为(batch_size, max_len, d_model),以便它可以与输入数据相加。- 最后,将扩展后的位置编码矩阵加到输入数据上,并返回结果。
#修改Transformer模型以添加位置编码
class TransformerClassifierWithPE(nn.Module):
def __init__(self, num_classes, d_model=100, nhead=2, num_layers=2, dim_feedforward=2048, dropout=0.1):
super(TransformerClassifierWithPE, self).__init__()
# 位置编码
self.pos_encoder = PositionalEncoding(d_model)
# Transformer编码器层
encoder_layers = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead, dim_feedforward=dim_feedforward, dropout=dropout)
self.transformer_encoder = nn.TransformerEncoder(encoder_layers, num_layers=num_layers)
# 分类器
self.classifier = nn.Linear(d_model, num_classes)
def forward(self, x):
# x: (batch_size, max_len, d_model)
x = self.pos_encoder(x)
x = x.permute(1, 0, 2) # (max_len, batch_size, d_model)
x = self.transformer_encoder(x) # (max_len, batch_size, d_model)
x = x.mean(dim=0) # (batch_size, d_model)
x = self.classifier(x) # (batch_size, num_classes)
return x
2.2 TransformerClassifierWithPE 类
这个类定义了一个带有位置编码的 Transformer 分类器模型。
初始化方法 __init__
num_classes:分类任务的类别数量。d_model:模型的维度,也是词嵌入的维度。nhead:多头注意力的头数。num_layers:Transformer 编码器层的数量。dim_feedforward:前馈网络中的隐藏层维度。dropout:Dropout 的概率。pos_encoder:PositionalEncoding 实例,用于位置编码。transformer_encoder:Transformer 编码器,由多个 TransformerEncoderLayer 组成。classifier:线性分类器,用于生成最终的分类结果。
前向传播方法 forward
- 输入
x的形状是(batch_size, max_len, d_model)。 - 首先,使用
self.pos_encoder(x)获取位置编码后的输入。 - 然后,将输入的维度从
(batch_size, max_len, d_model)转换为(max_len, batch_size, d_model),这是因为 PyTorch 的 Transformer 编码器期望的输入维度是这样的。 - 接下来,通过
self.transformer_encoder(x)应用 Transformer 编码器。 - 然后,使用
x.mean(dim=0)获取每个序列的平均表示。 - 最后,通过
self.classifier(x)应用线性分类器,得到最终的分类结果。
这个模型可以用于文本分类任务,其中输入是文本序列的词嵌入表示。
3、训练模型
# 模型参数
d_model = 512
nhead = 8
num_encoder_layers = 3
dim_feedforward = 2048
num_classes = len(data.label.unique()) # 假设label_dict是我们的标签字典
max_len = 256
model = TransformerClassifierWithPE( d_model=d_model, nhead=nhead, num_layers=num_encoder_layers, dim_feedforward=dim_feedforward, num_classes=num_classes, max_len=max_len,dropout=0.1)
-----------------------------
TransformerModel(
(pos_encoder): PositionalEncoding()
(transformer_encoder): TransformerEncoder(
(layers): ModuleList(
(0-2): 3 x TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(linear1): Linear(in_features=512, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=512, bias=True)
(norm1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
)
)
(decoder): Linear(in_features=512, out_features=10, bias=True)
)
# 训练模型
num_epochs = 20
for epoch in range(num_epochs):
for inputs, labels in train_loader:
# 清除梯度
optimizer.zero_grad()
# 前向传播
outputs = model(inputs)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}')
# 在测试集上评估模型
model.eval()
with torch.no_grad():
correct = 0
total = 0
for inputs, labels in test_loader:
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the model on the test set: {100 * correct / total}%')