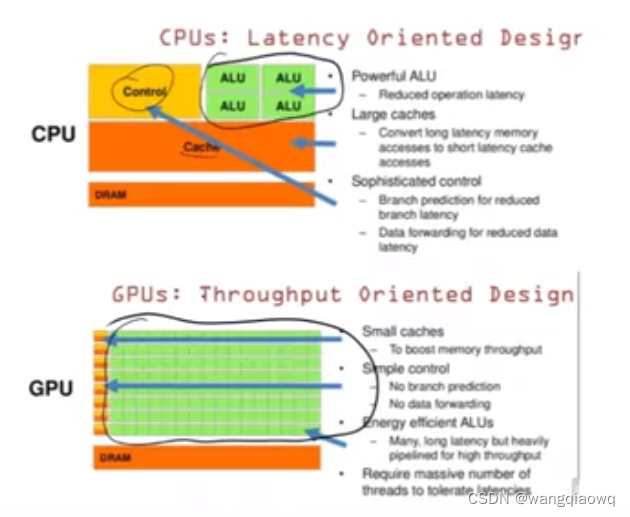
龙年春节期间Sora的推出让大模型又火了一把,作为重要的技术方向,很多同学都希望能够深入掌握大模型的相关技术,经常有人问如何学习大模型技术?有哪些材料可以参考?这里笔者将收藏夹里面的地址整理了一下,并加上了笔者的一些思考,供大家参考。
基础原理学习
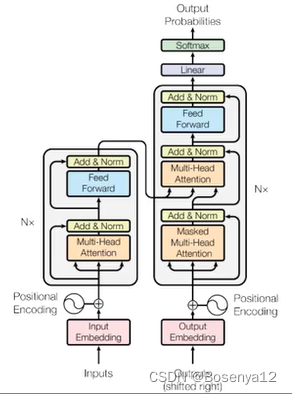
Google的Transformer模型论文《Attention Is All You Need》发表于2017年,其实已经相当长的时间了,这几年累积下来讲Transformer模型的文档非常多,比较通俗易懂的文章推荐如下:
- 超详细图解Self-Attention,Transformer模型与传统的CNN、RNN、Seq2Seq等神经网络模型最核心的点就是引入了自注意力机制,本篇知乎文章对理解什么是自注意力机制非常有帮助。
- The Illustrated Transformer(图解Transformer),CSDN一篇文章,是国外一篇讲解Transformer整体架构的博文的翻译版,里面对每个Transformer架构的每个模块都展开通过图形示例等方式进行了讲解,搞懂这些环节基本可以理解Transformer用到的关键技术。
- 手写AI-逐行手写GPT模型,这个是Bilibili上的一个培训视频(虽然免费的课程并不完整,但是够用了),讲解了从零开始手写一个GPT的实现,通过代码讲解可以更进一步了解GPT模型的技术原理是如何真正运行起来的,能够真正理解整个过程。
这几份材料从细节到整体,从原理到实现,覆盖比较全面,精读之后对GPT模型的原理基础会有一个比较深入的认识。
个人学习心得:
Transformer架构的理解
自注意力机制可以将上下文信息压缩到每个token的向量中,实现带上下文的并行计算,使得大规模参数和数据堆叠成为了可能,而海量参数和数据带来的推理能力涌现是这次大模型技术的爆发点。
目前大部分材料讲解都是Encoder-Decoder架构,也就是论文上讲的架构,而目前我们经常用的大模型一般都是Decoder-Only的架构(除了ChatGLM之外),所以如果想了解Decoder-Only的实现可以参考mingpt等开源代码,只有300行。
文档都有一定的滞后性,一些新的机制可以对照着看torch的源码或者transformer的源码,很多时候理论研究半天不如看几行代码理解的透彻,对于我们来说没有必要把论文的公式都搞明白。
两点疑问和思考
问题1:模型各层计算时都是[ batch_size, sequence_length, hidden_size]这样的三维矩阵,如何从这个矩阵中取出预测的下一个字符的?
我们都知道Transformer在输出时是一个字符一个字符输出的,并不能一次预测一段内容,但是我们计算矩阵实际上是三维的,这个对应关系如何?没有看到这方面的解释,从代码logits[:,-1,:].max(dim=1)[1]可以看到,实际在推理输出时,只使用了最后一个字符对应的那行向量来进行输出,从中选出最大值并将这个值映射到字典表。从理论上猜测,下一个输出字符与最后一个字符的关联是最紧密的,而其他字符都通过注意力机制某种程度上在这组向量中都是有表达的。
问题2:大模型的推理参数temperature,为何一个简单的除法就可以实现了?
看到temperature参数的实现代码:logits = logits[:, -1, :] / temperature感觉有点奇怪,为何对所有的向量直接做一个除法就可以改变模型输出的风格?(保守 VS 激进),其实这个与top_p参数有关系( top_p是累计概率,找N个候选达到总体概率超过top_p的值就结束),所以当temperature对向量成比例的放大,选到的候选单词就少,反之就会越多,通过这种方式来影响整体输出。这也是为什么temperature和top_p参数通常只调一个。
大咖观点学习
如果觉得技术原理太枯燥了,简单了解一下也行,并不会影响我们使用大模型,因为即使看懂了代码,大模型还是一个黑盒,哪些场景能够实现,哪些场景不能够实现也需要测试才能得到结论。当然如果我们仅仅从自己的经验中去学习那就太局限了,我们可以听听业界大佬的见解,他们见多识广,有很多思路可以学习。
注解:周鸿祎的两篇观点分享,一篇是2023年7月份,一篇是2023年12月份,周教主虽然言语比较犀利但是接地气,直白易懂。
注解:比较完整的关于ChatGPT的分析,信息量挺大,也很全面
百川智能王小川:大模型创业100天,我确认找到了属于我的「无人区」
注解:可能是王小川对行业发展的一些观察、经验和思考。这些笔记和真话涵盖了技术发展、应用场景、商业模式、市场动态、未来预测和创业心得。
总结一下,将两篇文章放在一起,一个火山、一个冰川,对照阅读。
大咖们的观点各有千秋,大模型到底是否是奇点的开始可能还需要争论一段时间,我个人的看法是:
- 大模型相对以前的小模型来说是个跨越,在通用性、质量上都有变革性的提升
- 大模型在知识压缩、存储、召回上实现了突破,实现了通过自然语言来检索海量知识
- 但是从应用场景来看,大模型并没有比小模型扩展出太多的范围,与小模型一样,依然缺乏场景和数据
- 目前语言模型的提升应该进入了瓶颈期,现在开始向MOE和多模态方向的探索
其他学习资料
Lora是一种高效参数微调(PEFT)方法,也是目前最流行的模型训练微调方法,很好的平衡了效率和质量,这篇文章虽然是英文,但是是科普性的,简单易读,能够比较透彻的理解Lora、QLora等技术原理。
LLM大语言模型之Generate/Inference(生成/推理)中参数与解码策略原理及其代码实现
我们在使用OpenAI的接口调用大模型的时候,有很多参数,比如temperature、top_p、top_k、repeat_penality等,我们除了不断优化Prompt之外,这些参数也应该仔细加以考虑以更匹配我们的场景。
RAG方向建议大家直接看llama.index这个开源社区,有文档和代码,很清晰
Prompt工程的通用框架以及案例解析:模型本身智能才是关键,Prompt仅用做锦上添花
Prompt工程相关,是否需要仔细写Prompt?是的,能起决定性作用么?不一定。
学习笔记总结
Transformer 是一种基于自注意力机制的深度学习模型,广泛用于自然语言处理、计算机视觉和音频处理等领域。以下是一些 Transformer 学习笔记:
- Transformer 模型由两部分组成:编码器和解码器。编码器将输入序列编码成一个连续的向量,解码器则根据编码器的输出和已经生成的目标序列来生成下一个目标token。
- 自注意力机制是 Transformer 模型的核心。它允许模型在处理每个token时,查看序列中的所有其他token,并利用它们的信息来计算注意力权重。这些权重用于加权输入序列中的所有token,生成一个加权的表示,作为下一个token的输入。
- Transformer 模型使用了一种名为位置编码的技术,将序列中每个token的位置信息编码为它们的位置向量。这些位置向量被添加到token的嵌入向量中,使模型能够理解序列中token的顺序。
- Transformer 模型使用了一种名为多头注意力机制的技术,它将输入序列分成多个头,每个头计算不同的注意力权重。这有助于模型在处理每个token时,从不同的角度获取输入序列的信息,提高模型的表现。
- Transformer 模型使用了一种名为前馈神经网络的技术,它将编码器和解码器中的每个层都连接起来。前馈神经网络有助于模型在处理每个token时,更好地学习非线性变换,提高模型的表现。
- Transformer 模型的训练过程可以使用多种技术,如学习率衰减、数据增强和正则化等。这些技术有助于模型在训练过程中避免过拟合,提高模型的泛化能力。
Transformer 是一种强大的深度学习模型,具有很多优点,如并行计算能力、良好的表现和泛化能力等。但是,它也有一些缺点,如计算成本高、训练时间长等。在实际应用中,需要根据具体任务和数据集选择合适的模型和训练技术。
学习体会
两点体会分享:
- 数字世界变化越来越快,必须得卷,也要相信世界真的在变化,可以根据自己的喜好去刷最新的论文,或者去刷开源社区,与外部对齐认知。
- 习惯往往制约了我们拥抱变化的能力,而开放的交流和不保留的分享其实是一种学习、成长的新方式。