注意:本文引用自专业人工智能社区Venus AI
更多AI知识请参考原站 ([www.aideeplearning.cn])
项目背景
在数据科学和机器学习的领域中,文本分析一直是一个引人注目的话题。这个项目的核心挑战是利用机器学习技术,根据文章或书籍的概要预测其类型。这不仅是一个技术挑战,涉及到复杂的文本处理和模式识别技术,而且还是一个应用挑战,探索如何在实际业务中利用这些技术。
数据集特征的详细介绍
- 数据丰富性:项目的数据集包含了成千上万本书籍的概要,提供了一个多样化的文本数据集来进行机器学习实验。
- 多维特征:除了基本信息如书名、作者和概要之外,数据集中还可能包括出版年份、ISBN、出版社、甚至书籍的物理尺寸等信息。这些特征提供了多维度的数据,有助于建立更准确的预测模型。
- 类型多样性:数据集中的书籍被分为多种类型,从而提供了一个广阔的分类范围,这对于构建分类算法来说是非常有价值的。
应用领域的扩展
- 出版业的革新:这个项目可以帮助出版商更精准地对书籍进行分类,从而优化其市场策略和读者定位。
- 电子商务的提升:在线书店和电子书平台可以利用这些算法来提高推荐系统的准确性,从而提高用户体验和销售效率。
- 学术研究的深化:对于从事文学研究的学者来说,这个项目提供了一种全新的文学作品分析方法,可以从数据科学的角度深入探索文本内容。
项目目标
- 模型构建:这个项目的主要目标是构建一个有效的机器学习模型,能够准确预测书籍的类型。本项目采用逻辑回归,贝叶斯和支持向量机进行模型训练和测试。
- 数据处理和特征工程:数据预处理是这个项目的关键部分,包括文本清洗、分词、向量化等步骤。此外,特征工程的目标是识别出哪些特征对于预测书籍类型最为重要。
- 模型评估:评估模型的准确性、泛化能力和效率是项目的关键。这涉及到使用各种评估指标,如准确率、召回率和F1得分,以及交叉验证等技术。
项目的科学计算库依赖
- matplotlib==3.7.1
- pandas==2.0.2
- scikit_learn==1.2.2
- seaborn==0.13.0
- sentence_transformers==2.2.2
项目的详细代码
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import cross_val_score使用 pandas 读取训练数据集
data = pd.read_csv('data.csv')print(data.columns)
data.shapeIndex(['index', 'title', 'genre', 'summary'], dtype='object')
(4657, 4)data.head()
data['genre'].value_counts().plot(kind='barh')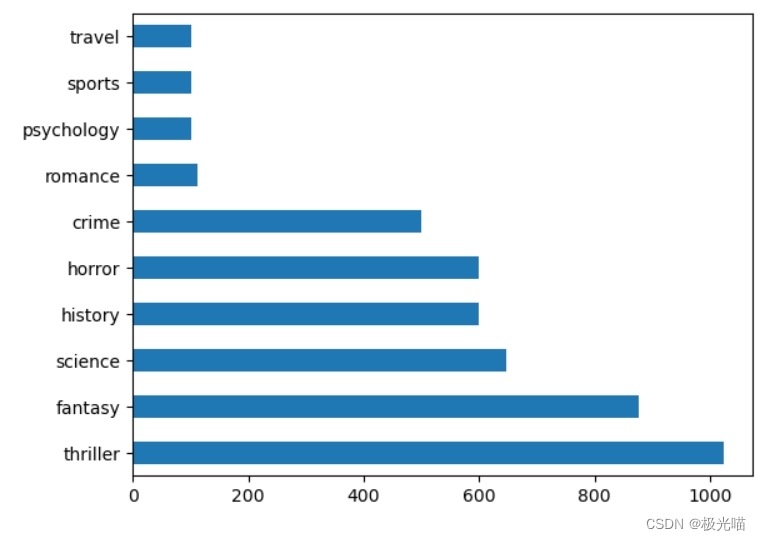
数据预处理
data['genre_id'] = data['genre'].factorize()[0]data['genre_id'].value_counts()5 1023 0 876 1 647 3 600 4 600 2 500 7 111 6 100 8 100 9 100 Name: genre_id, dtype: int64
data['summary'] = data['summary'].apply(lambda x: x.lower())data.head()
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-mpnet-base-v2')
def getEmbedding(sentence):
return model.encode(sentence).gitattributes: 0%| | 0.00/1.18k [00:00<?, ?B/s]
1_Pooling/config.json: 0%| | 0.00/190 [00:00<?, ?B/s]
README.md: 0%| | 0.00/10.6k [00:00<?, ?B/s]
config.json: 0%| | 0.00/571 [00:00<?, ?B/s]
config_sentence_transformers.json: 0%| | 0.00/116 [00:00<?, ?B/s]
data_config.json: 0%| | 0.00/39.3k [00:00<?, ?B/s]
pytorch_model.bin: 0%| | 0.00/438M [00:00<?, ?B/s]
sentence_bert_config.json: 0%| | 0.00/53.0 [00:00<?, ?B/s]
special_tokens_map.json: 0%| | 0.00/239 [00:00<?, ?B/s]
tokenizer.json: 0%| | 0.00/466k [00:00<?, ?B/s]
tokenizer_config.json: 0%| | 0.00/363 [00:00<?, ?B/s]
train_script.py: 0%| | 0.00/13.1k [00:00<?, ?B/s]
vocab.txt: 0%| | 0.00/232k [00:00<?, ?B/s]
modules.json: 0%| | 0.00/349 [00:00<?, ?B/s]
embeddings = data['summary'].apply(lambda x: getEmbedding(x))input_data = []
for item in embeddings:
input_data.append(item.tolist())使用 Tfidf 向量器与深度学习模型sentence embedding进行比较
from sklearn.feature_extraction.text import TfidfVectorizertfidf = TfidfVectorizer(sublinear_tf=True, min_df=5,
ngram_range=(1, 2),
stop_words='english')
# We transform each complaint into a vector
features = tfidf.fit_transform(data.summary).toarray()
labels = data.genre_id
print("Each of the %d synopsis is represented by %d features (TF-IDF score of unigrams and bigrams)"Each of the 4657 synopsis is represented by 20152 features (TF-IDF score of unigrams and bigrams)
Tfidf 和sentence embedding模型之间的精度比较
使用 Tfidf 向量器的文本嵌入:
models = [
RandomForestClassifier(n_estimators=100, max_depth=5, random_state=0),
LinearSVC(),
MultinomialNB(),
LogisticRegression(random_state=0),
]
# 5 Cross-validation
CV = 5
cv_df = pd.DataFrame(index=range(CV * len(models)))
entries = []
for model in models:
model_name = model.__class__.__name__
accuracies = cross_val_score(model, features, labels, scoring='accuracy', cv=CV)
for fold_idx, accuracy in enumerate(accuracies):
entries.append((model_name, fold_idx, accuracy))
cv_df_tfidf = pd.DataFrame(entries, columns=['model_name', 'fold_idx', 'accuracy'])cv_df_tfidf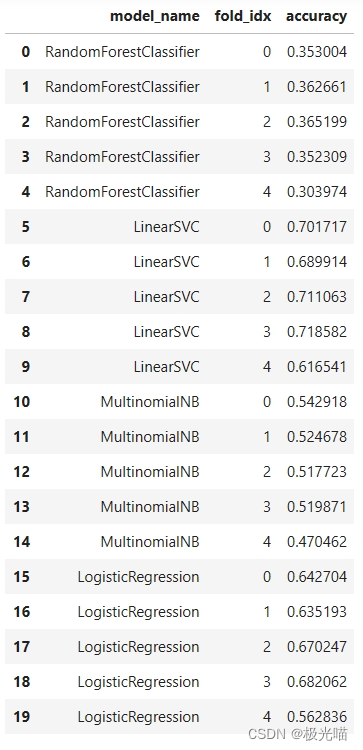
使用sentence embedding模型的文本嵌入
models = [
RandomForestClassifier(n_estimators=100, max_depth=5, random_state=0),
LinearSVC(),
LogisticRegression(random_state=0, max_iter=1000)
]
# 5 Cross-validation
CV = 5
cv_df = pd.DataFrame(index=range(CV * len(models)))
entries = []
for model in models:
model_name = model.__class__.__name__
accuracies = cross_val_score(model, input_data, data['genre'].factorize()[0], scoring='accuracy', cv=CV)
for fold_idx, accuracy in enumerate(accuracies):
entries.append((model_name, fold_idx, accuracy))
cv_df = pd.DataFrame(entries, columns=['model_name', 'fold_idx', 'accuracy'])cv_df
注:从上面的比较中我们可以看出,当使用sentence embedding生成的文本嵌入时,所有模型的准确率都更高。因此,我们将使用这些嵌入词进行进一步的模型训练
此外,与其他模型相比,LinearSVC 的准确率最高。因此,让我们使用 LinearSVC 来训练我们的基因预测模型吧
模型训练
from sklearn.metrics import classification_report, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as snsX_train, X_test, y_train, y_test = train_test_split(input_data,
labels,
test_size=0.25,
random_state=1)
model = LinearSVC()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# Classification report
print('\t\t\t\t\tCLASSIFICATIION METRICS\n')
print(classification_report(y_test, y_pred,
target_names= data['genre'].unique())) CLASSIFICATIION METRICS
precision recall f1-score support
fantasy 0.77 0.77 0.77 233
science 0.74 0.72 0.73 167
crime 0.66 0.59 0.62 126
history 0.76 0.77 0.76 145
horror 0.66 0.59 0.62 132
thriller 0.67 0.79 0.72 247
psychology 0.79 0.76 0.78 25
romance 0.63 0.34 0.44 35
sports 0.86 0.83 0.85 30
travel 0.89 1.00 0.94 25
accuracy 0.72 1165
macro avg 0.74 0.72 0.72 1165
weighted avg 0.72 0.72 0.72 1165
genre_id_df = data[['genre', 'genre_id']].drop_duplicates()conf_mat = confusion_matrix(y_test, y_pred)
fig, ax = plt.subplots(figsize=(8,8))
sns.heatmap(conf_mat, annot=True, cmap="Blues", fmt='d',
xticklabels=genre_id_df.genre.values,
yticklabels=genre_id_df.genre.values)
plt.ylabel('Actual')
plt.xlabel('Predicted')
plt.title("CONFUSION MATRIX - LinearSVC\n", size=16);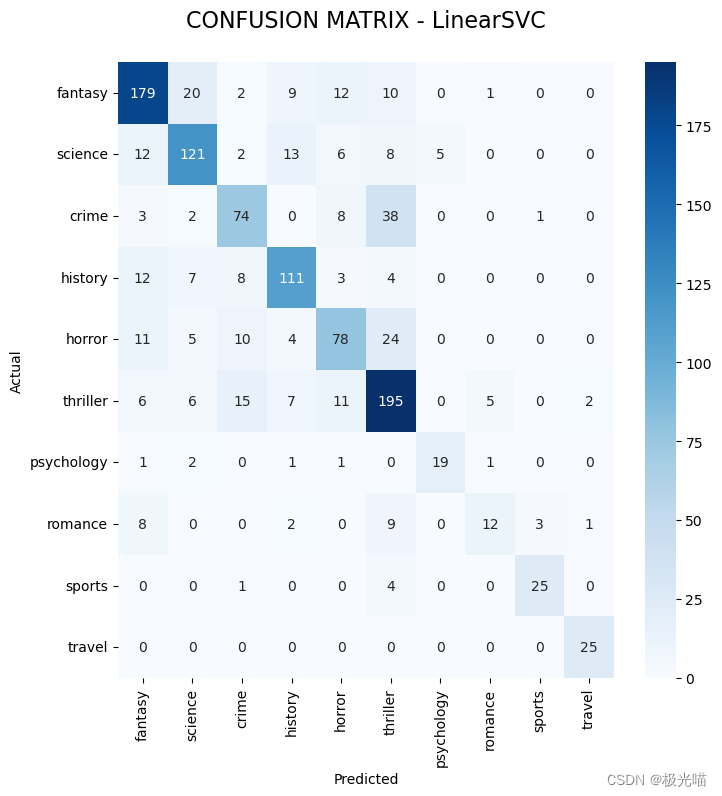
保持embedding向量为文件
import picklewith open('embeddings.pkl', 'wb') as file:
pickle.dump(embeddings, file)with open('embeddings.pkl', 'rb') as file:
embeddings = pickle.load(file)进行预测
from sentence_transformers import SentenceTransformer
# Initialize the SentenceTransformer model
model = SentenceTransformer('all-mpnet-base-v2')
def getEmbedding(sentence):
# Generate and return the embedding for the provided sentence
return model.encode(sentence)
# Example usage
test_summary = "Teenager Max McGrath (Ben Winchell) discovers that his body can generate the most powerful energy in the universe. Steel (Josh Brener) is a funny, slightly rebellious, techno-organic extraterrestrial who wants to utilize Max's skills. When the two meet, they combine together to become Max Steel, a superhero with unmatched strength on Earth. They soon learn to rely on each other when Max Steel must square off against an unstoppable enemy from another galaxy."
test_summary_embed = getEmbedding(test_summary)
X_train, X_test, y_train, y_test = train_test_split(input_data, data['genre'],
test_size=0.25,
random_state = 0)
trained_model = LinearSVC().fit(X_train, y_train)print(trained_model.predict([test_summary_embed]))['science']




















![uniapp运行项目到微信小程序报错——未找到[“sitemapLocation“]](https://img-blog.csdnimg.cn/direct/d670e1dfc189487a8eec4dc6f5efb370.png#pic_center)