目录
二、 为什么要学习 Spring Cloud Balancer ?
三、 Spring Cloud LoadBalancer 内置的两种负载均衡策略
六、Spring Cloud LoadBalancer 中的缓存机制
6.1 Spring Cloud LoadBalancer 中缓存机制的一些特性
一、什么是LoadBalancer?
LoadBalancer(负载均衡器)是一种网络设备或软件机制,用于分发传入的网络流量负载(请求)到多个后端目标服务器上,从而实现系统资源的均衡利用和提高系统的可用性和性能。
1.1 负载均衡的分类
负载均衡分为服务器端的负载均衡和客户端的负载均衡。
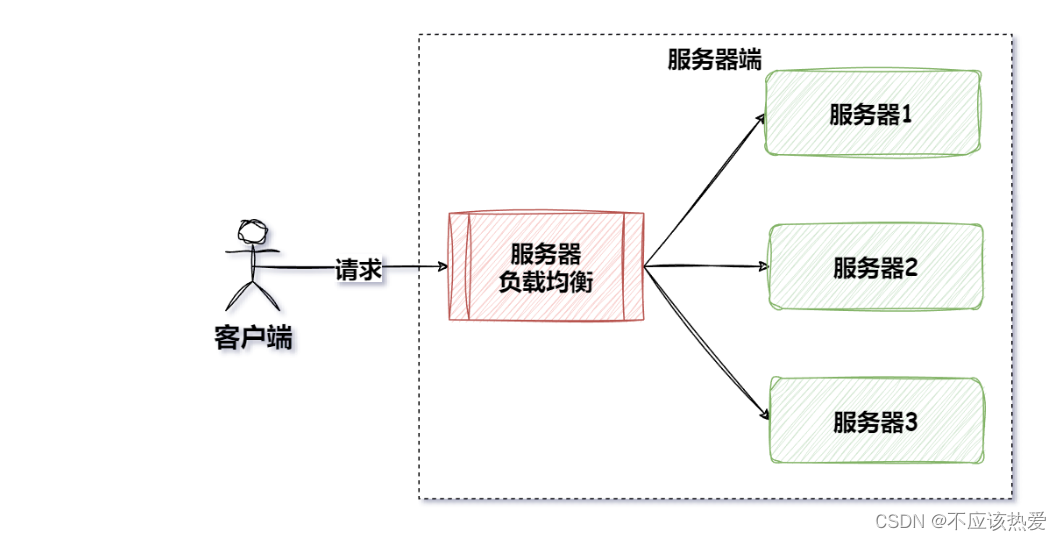
1、服务器端的负载均衡指的是存放在服务器端的负载均衡器,例如Nginx,F5等。
这里面的Nginx是属于反向代理的。何为反向代理?
反向代理其实就是位于服务端的一种代理模式,日常使用的比如airdrome这种,就是正向代理,其是在客户端运行的。
2、客户端负载均衡指的是嵌套在客户端的负载均衡器,例如Ribbon、SpringCloudLoadBalancer。
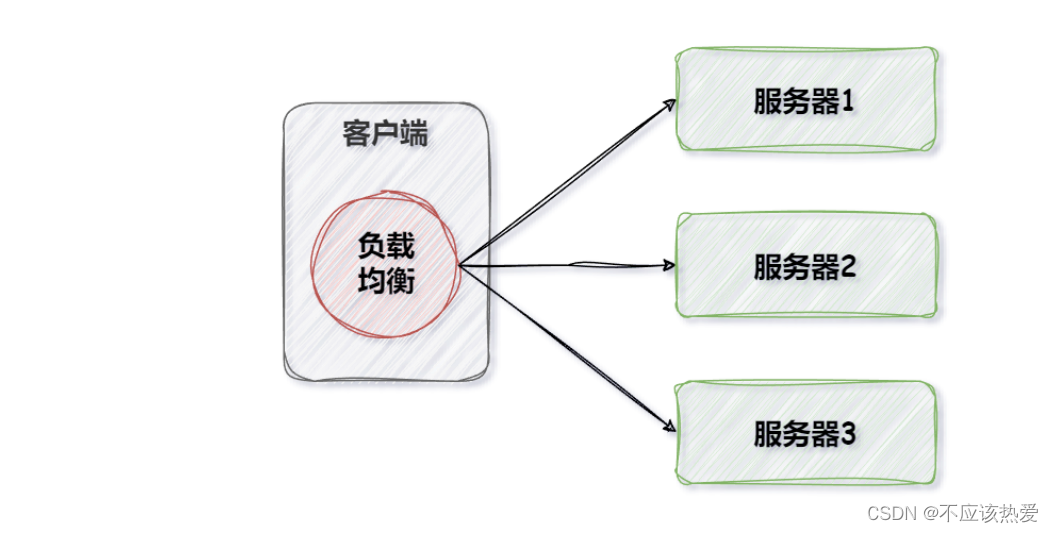
通常来说,客户端的负载均衡器的性能会好一点,因为想象一下,有1w个请求,打到我们的服务端负载均衡器上面的性能高,还是1w个客户端,它们自身就有负载均衡器进行负载。哪个效率高呢?
显而易见,客户端的负载均衡器性能较高。
1.2 负载均衡策略
无论是上面的客户端负载均衡器还是服务器的负载均衡器,他们的负载均衡策略都是相同的,因为负载均衡策略本质是一种思想。
常见的负载均衡策略有以下几个:
- 轮询(Round Robin):轮询策略按照顺序将每个新的请求分发给后端服务器,依次循环。这是一种最简单的负载均衡策略,适用于后端服务器的性能相近,且每个请求的处理时间大致相同的情况
- 随机选择(Random):随机选择策略随机选择一个后端服务器来处理每个新的请求。这种策略适用于后端服2 务器性能相似,且每个请求的处理时间相近的情况,但不保证请求的分发是均的。
- 最少连接(Least Connections):最少连接策略将请求分发给当前连接数最少的后端服务器。这可以确保负载均衡在后端服务器的连接负载上均衡,但需要维护连接计数。
- IP 哈希(IP Hash):IP 哈希策略使用客户端的 IP 地址来计算哈希值,然后将请求发送到与哈希值对应的后端服务器。这种策略可用于确保来自同一客户端的请求都被发送到同一台后端服务器,适用于需要会话保持的情况。
- 加权轮询(Weighted Round Robin):加权轮询策略给每个后端服务器分配一个权重值,然后按照权重值比例来分发请求。这可以用来处理后端服务器性能不均衡的情况,将更多的请求分发给性能更高的服务器。
- 加权随机选择(Weighted Random):加权随机选择策略与加权轮询类似,但是按照权重值来随机选择后端服务器。这也可以用来处理后端服务器性能不均衡的情况,但是分发更随机。
- 最短响应时间(Least Response Time):最短响应时间策略会测量每个后端服务器的响应时间,并将请求发送到响应时间最短的服务器。这种策略可以确保客户端获得最快的响应,适用于要求低延迟的应用。
使用的比较多的是轮询、哈希(IP)、加权负载均衡、最短响应时间负载均衡策略。
可能有人会问为什么最少连接并不被广泛运用呢?这是因为最少连接无法反映硬件的情况,比如1核1G的服务器有1000个请求,32核32G有1500个请求,之后如果再来请求,其实分配给32核服务器是最快的。
最少连接策略比较适合服务器的配置都基本一样的情况,但是这种情况是比较少见的。
二、 为什么要学习 Spring Cloud Balancer ?
因为 Ribbon 作为早期的客户端负载均衡工具,在 Spring Cloud 2020.0.0 版本之后已经被移除了,取而代之的是 Spring Cloud LoadBalancer,而且 Ribbon 也已经不再维护,所以它也是 Spring 官方推荐的负载均衡解决方案。
三、 Spring Cloud LoadBalancer 内置的两种负载均衡策略
3.1 轮询负载均衡策略(默认的)
从它的源码实现可以看出来默认的负载均衡策略是轮询的策略。
IDEA 搜索它的配置类 LoadBalancerClientConfiguration:
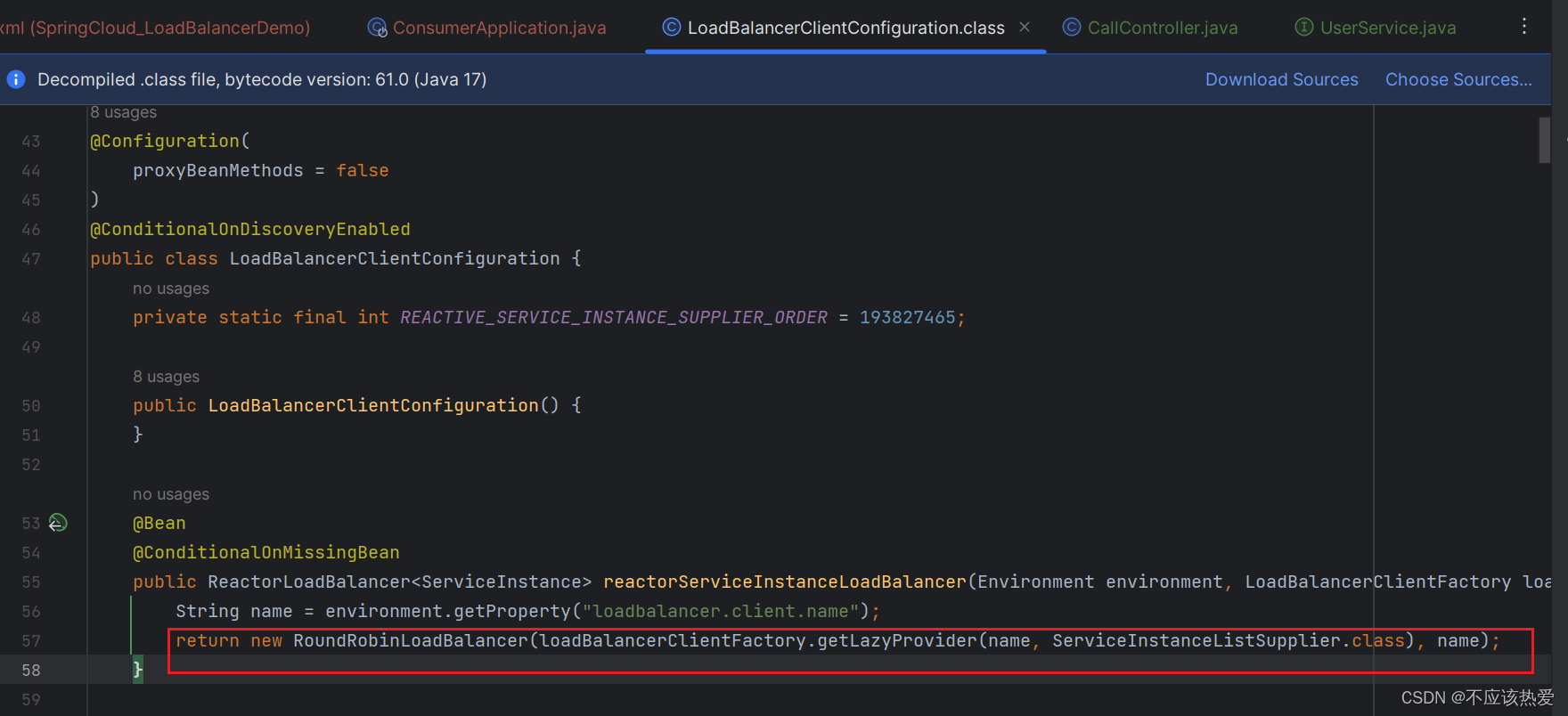
进入到 RoundRobinLoadBalancer 这个类里边,定位到 getInstanceResponse 方法,就能看到轮询策略的关键代码:
private Response<ServiceInstance> getInstanceResponse(List<ServiceInstance> instances) {
if (instances.isEmpty()) {
if (log.isWarnEnabled()) {
log.warn("No servers available for service: " + this.serviceId);
}
return new EmptyResponse();
} else if (instances.size() == 1) {
return new DefaultResponse((ServiceInstance)instances.get(0));
} else {
int pos = this.position.incrementAndGet() & Integer.MAX_VALUE;
ServiceInstance instance = (ServiceInstance)instances.get(pos % instances.size());
return new DefaultResponse(instance);
}
}理解关键代码:
int pos = this.position.incrementAndGet() & Integer.MAX_VALUE;
- 观察源码我们发现:this.position.incrementAndGet() 方法等价于 "++随机数 "。因为incrementAndGet是一个原子操作,保证了每次调用都会得到一个唯一的递增数值,position在构造方法中利用new Random()).nextInt(1000)进行赋值。
- & Integer.MAX_VALUE 这部分是一个位运算,它确保了如果 position 的值增加到超过 Integer.MAX_VALUE 时,不会产生负数。其一,在轮询算法中,如果计数器变成负数,那么取余操作可能会产生负的索引值,这是无效的; 其二,也可也保证在相同规则底下的公平性。
ServiceInstance instance = (ServiceInstance)
instances.get(pos % instances.size()); // 进行轮询选择instances 是一个包含所有服务实例的列表。
pos % instances.size() 计算的是 pos 除以 instances 列表大小的余数,这保证了不论 pos 增长到多大,这个表达式的结果都是在 0 到 instances.size() - 1 的范围内,这样就可以循环地从服务实例列表中选择服务实例。
举个例子比如,现在有两个机器,那么代码中的instance.getSize()得到的就是2,那么如何实现轮询呢?
其实本质就是让下标从 0到1,再从1到0,如此循环往复,那么以上这种做法就很好实现,比如现在我初始化的随机数是6,那么6经过与Integer.MAX_VALUE(这个数值除了符号位为0,其他都为1)的与操作之后还是6。
6跟2进行取模运算的话,得到下标为0,由于随机数是自增的,接下来随机数为7,那么7进行与操作之后还是7,7进行模2之后得到下标为1。循环往复,就实现了轮询算法。
3.2 随机负载均衡策略
观察源码可以知道,SpringCloud LoadBalancer内置了两种负载均衡策略:
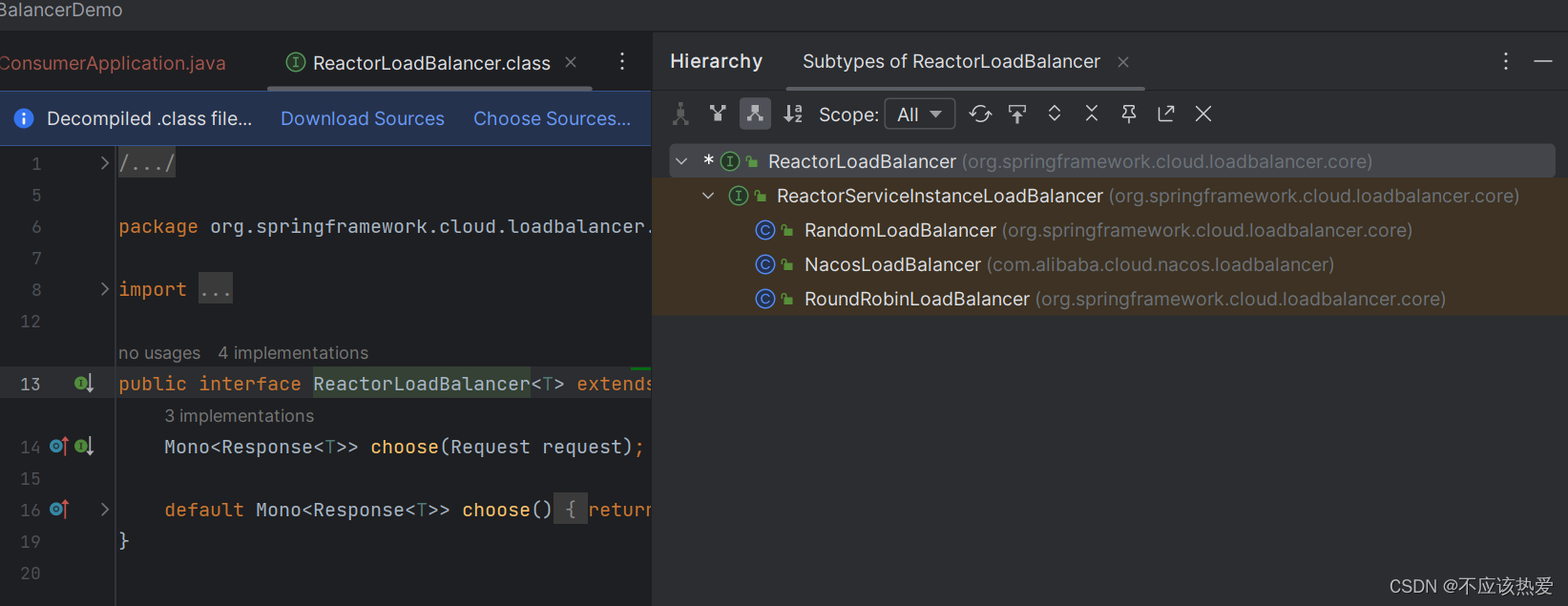
第一种轮询的负载均衡策略(默认),上面已经介绍过了,那么接下来我们来看如何实现 随机负载均衡策略。
实现随机负载均衡策略的步骤:
① 创建随机负载均衡策略
② 设置随机负载均衡策略
3.2.1 创建随机负载均衡策略
通过查看官网源码可以得知,自定义负载均衡器按照如下实现即可:
public class RandomLoadBalancerConfig {
// 随机的负载均衡策略
@Bean
public ReactorLoadBalancer<ServiceInstance> randomLoadBalancer(Environment environment, LoadBalancerClientFactory loadBalancerClientFactory) {
String name = environment.getProperty("loadbalancer.client.name");
return new RandomLoadBalancer(
loadBalancerClientFactory.getLazyProvider(name,
ServiceInstanceListSupplier.class), name);
}
}3.2.2 设置随机负载均衡策略
在consumer模块中的service接口上通过@LoadBalancerClient 设置负载均衡策略:
@Service
@FeignClient("loadbalancer-service")
// 设置局部的负载均衡策略
@LoadBalancerClient(name = "loadbalancer-service",
configuration = RandomLoadBalancerConfig.class)
public interface UserService {
@RequestMapping("/user/getname")
public String getName(@RequestParam("id") Integer id);
}有时候局部的负载均衡策略不会生效(版本问题),可以将其设置为全局的负载均衡策略。
如何设置全局的负载均衡策略:(在springboot启动类上加 @LoadBalancerClients 注解)
@SpringBootApplication
@EnableFeignClients // 开启 OpenFeign
// 设置全局的负载均衡策略
@LoadBalancerClients(defaultConfiguration =
RandomLoadBalancerConfig.class)
public class ConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(ConsumerApplication.class, args);
}
}这个时候,就是随机的负载均衡策略了,可以启动两个生产者和消费者,然后拿着消费者这边的端口去获取服务感受。
四、 Nacos 权重负载均衡器
Nacos 中有两种负载均衡策略:权重负载均衡策略和 CMDB(地域就近访问)标签负载均衡策略
它默认的策略是权重。
在 Spring Cloud Balancer 配置为 Nacos 负载均衡器的步骤:
① 创建 Nacos 负载均衡器
② 设置 Nacos 负载均衡器
4.1 创建 Nacos 负载均衡器
配置 Nacos 负载均衡需要注入 NacosDiscoveryProperties 这个类,因为它需要使用到配置文件中的一些关键信息。
这里使用@LoadBalancerClients注解是需要在启动时候就获取nacos相关的信息。
@LoadBalancerClients(defaultConfiguration = NacosLoadBalancerConfig.class)
public class NacosLoadBalancerConfig {
@Resource
NacosDiscoveryProperties nacosDiscoveryProperties;
@Bean
public ReactorLoadBalancer<ServiceInstance> nacosLoadBalancer(Environment environment, LoadBalancerClientFactory loadBalancerClientFactory) {
String name = environment.getProperty("loadbalancer.client.name");
return new NacosLoadBalancer(
loadBalancerClientFactory.getLazyProvider(name,
ServiceInstanceListSupplier.class), name, nacosDiscoveryProperties);
}
}这里修改的时候除了new的时候修改成NacosLoadBalancer之外,里面的方法也需要多传递一个NacosDiscoveryProperties 的对象。

其实相比于之前的设置负载均衡器,也就多了三步而已:
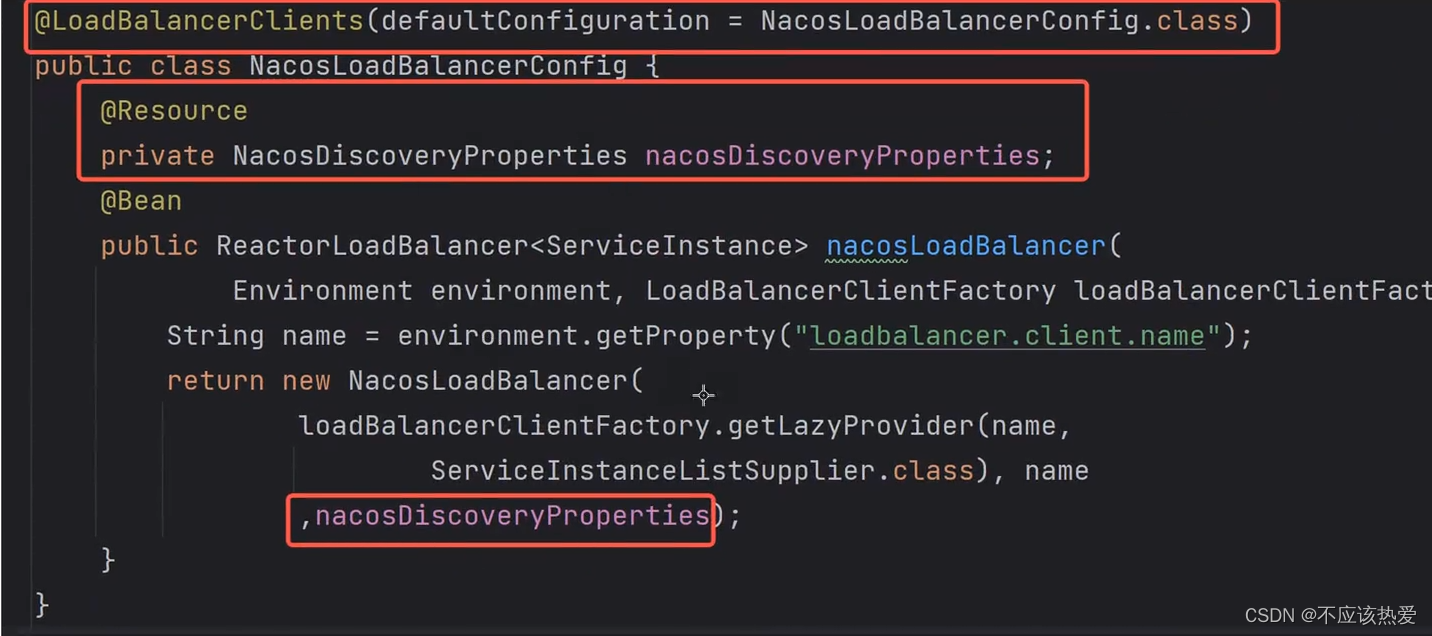
4.2 设置Nacos 负载均衡器
@Service
@FeignClient("loadbalancer-service")
// 设置局部的负载均衡策略
@LoadBalancerClient(name = "loadbalancer-service",
configuration = NacosLoadBalancerConfig.class)
public interface UserService {
@RequestMapping("/user/getname")
public String getName(@RequestParam("id") Integer id);
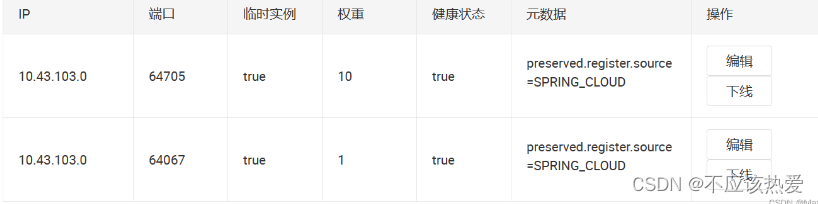
}再测试之前,可以先将 Nacos 中一个生产者的权重给设置为 10,一个设置为 1,这样就能明显感受到 Nacos 权重的负载均衡策略了。
五、自定义负载均衡器
自定义负载均衡策略需要 3 个步骤:
① 创建自定义负载均衡器
② 封装自定义负载均衡器
③ 为服务设置自定义负载均衡策器
5.1 创建自定义负载均衡器
这里也是可以参考源码的实现的,搜索 RandomLoadBalancer 这个类,模仿它的实现去创建自定义负载均衡器。
Ⅰ. 创建一个负载均衡类, 并让其实现 ReactorServiceInstanceLoadBalancer 接口;
Ⅱ. 复制 RandomLoadBalancer 的整个方法体,粘贴到自定义负载均衡类中,并修改构造方法名称
Ⅲ. 在关键方法 getInstanceResponse 中实现自定义负载均衡策略(以IP哈希负载均衡为例)
public class CustomLoadBalancer implements ReactorServiceInstanceLoadBalancer {
private static final Log log = LogFactory.getLog(CustomLoadBalancer.class);
private final String serviceId;
private ObjectProvider<ServiceInstanceListSupplier> serviceInstanceListSupplierProvider;
public CustomLoadBalancer(ObjectProvider<ServiceInstanceListSupplier> serviceInstanceListSupplierProvider, String serviceId) {
this.serviceId = serviceId;
this.serviceInstanceListSupplierProvider = serviceInstanceListSupplierProvider;
}
public Mono<Response<ServiceInstance>> choose(Request request) {
ServiceInstanceListSupplier supplier = (ServiceInstanceListSupplier)this.serviceInstanceListSupplierProvider.getIfAvailable(NoopServiceInstanceListSupplier::new);
return supplier.get(request).next().map((serviceInstances) -> {
return this.processInstanceResponse(supplier, serviceInstances);
});
}
private Response<ServiceInstance> processInstanceResponse(ServiceInstanceListSupplier supplier, List<ServiceInstance> serviceInstances) {
Response<ServiceInstance> serviceInstanceResponse = this.getInstanceResponse(serviceInstances);
if (supplier instanceof SelectedInstanceCallback && serviceInstanceResponse.hasServer()) {
((SelectedInstanceCallback)supplier).selectedServiceInstance((ServiceInstance)serviceInstanceResponse.getServer());
}
return serviceInstanceResponse;
}
private Response<ServiceInstance> getInstanceResponse(List<ServiceInstance> instances) {
if (instances.isEmpty()) {
if (log.isWarnEnabled()) {
log.warn("No servers available for service: " + this.serviceId);
}
return new EmptyResponse();
} else {
// 自定义负载均衡策略
// 获取 Request 对象
ServletRequestAttributes attributes = (ServletRequestAttributes)
RequestContextHolder.getRequestAttributes();
HttpServletRequest request = attributes.getRequest();
String ipAddress = request.getRemoteAddr();
System.out.println("用户 IP:" + ipAddress);
int hash = ipAddress.hashCode();
// IP 哈希负载均衡【关键代码】
int index = hash % instances.size();
// 得到服务实例的方法
ServiceInstance instance = (ServiceInstance) instances.get(index);
return new DefaultResponse(instance);
}
}
}5.2 封装自定义负载均衡器
public class CustomLoadBalancerConfig {
// IP 哈希负载均衡
@Bean
public ReactorLoadBalancer<ServiceInstance> customLoadBalancer(Environment environment, LoadBalancerClientFactory loadBalancerClientFactory) {
String name = environment.getProperty("loadbalancer.client.name");
return new CustomLoadBalancer(
loadBalancerClientFactory.getLazyProvider(name,
ServiceInstanceListSupplier.class), name);
}
}5.3 为服务设置自定义负载均衡策器
@Service
@FeignClient("loadbalancer-service")
// 设置局部的负载均衡策略
@LoadBalancerClient(name = "loadbalancer-service",
configuration = CustomLoadBalancerConfig.class)
public interface UserService {
@RequestMapping("/user/getname")
public String getName(@RequestParam("id") Integer id);
}PS:测试的时候发现自定义的负载均衡策略不生效怎么办 ?
① 把前边的 Nacos 的负载均衡器一整个注释掉(包括 @LoadBalancerClients注解),只提供一个类。
② 如果设置局部的负载均衡不生效,就去启动类上设置全局的负载均衡策略。
@SpringBootApplication
@EnableFeignClients // 开启 OpenFeign
// 设置全局的负载均衡策略
@LoadBalancerClients(defaultConfiguration =
CustomLoadBalancerConfig.class)
public class ConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(ConsumerApplication.class, args);
}
}六、Spring Cloud LoadBalancer 中的缓存机制
Spring Cloud LoadBalancer 中获取服务实例有两种方式:
- 实时获取:每次都从注册中心得到最新的健康实例(效果好,开销大)
- 缓存服务列表:每次得到服务列表之后,缓存一段时间(既保证性能,也能保证一定的及时性)
Spring Cloud LoadBalancer 默认开启了缓存服务列表的功能。
测试 Spring Cloud LoadBalancer 的缓存机制:
1. 将前面设置负载均衡策略全部注释掉,使用默认的轮询测试(便于观察)
2. 准备两个服务
3. 将其中一个服务下线,下线的同时立马去获取服务,然后等大约 35s ,再去获取服务
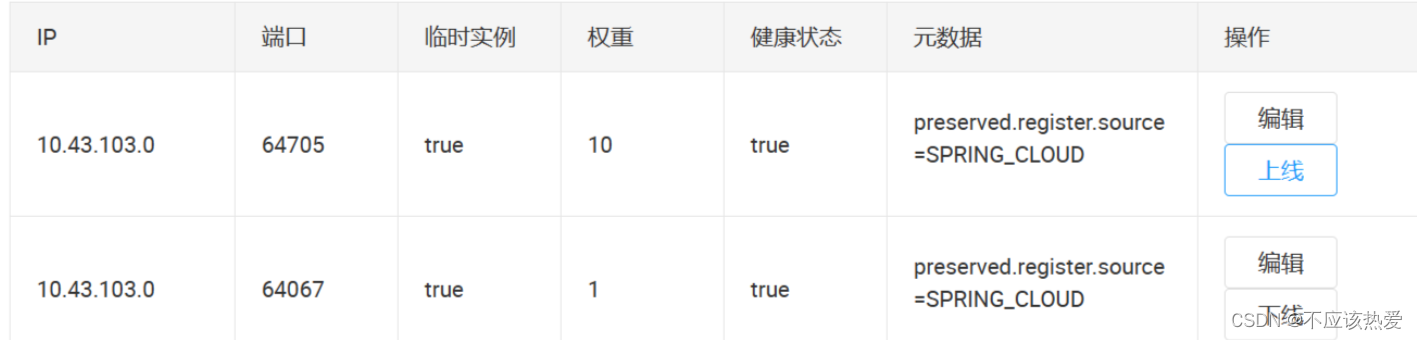
【测试结果】 当我下线第一个服务的时候,立马去获取服务,这个时候还是两个服务轮询的获取,等过了 35s 左右,就只能获取到 64067 这个服务了。
6.1 Spring Cloud LoadBalancer 中缓存机制的一些特性
默认特性如下:
① 缓存的过期时间为 35s;
② 缓存保存个数为 256 个。
我们可以通过在配置文件中去设置这些特性:
spring:
cloud:
loadbalancer:
cache:
ttl: 35s # 过期时间
capacity: 1024 # 设置缓存个数6.2 关闭缓存
关闭 Spring Cloud LoadBalancer 中的缓存可以通过以下配置文件来设置:
spring:
cloud:
loadbalancer:
cache:
enabled: false # 关闭缓存PS:尽管关闭缓存对于开发和测试很有用,但是在生产环境上,它的效率是要远低于开启缓存,所以在生产环境上始终都要开启缓存。