大数据
要了解大数据,我们就要先了解什么是数据?
数据就是指人们的行为,人们的某个行为都被称为是一项数据,这些数据可以用来对生活中各种各样的事物进行分析,而我们进行分析所需要的技术就是我们所学的大数据的一系列的技术栈
所谓大数据,就是指将现在的数据进行处理,并得出一定结果的技术
其中,大数据的核心工作就是从海量的高增长、多类别、低信息密度的数据中发掘出高质量的结果
由此延伸而出的大数据核心工作就是:数据存储、数据计算、数据传输
大数据框架
数据存储:
Hadoop中的HDFS
Hbase是最为广泛的NoSQL技术、
Apache KUDU 也是类似于Hadoop的分布式存储技术
数据计算:
Apache中的MapReduce,以及基于MapReduce的Hive
也包括Apache Spark (内存计算)以及 Apache Flink(实时计算)
数据传输:
Apache Kafka(分布式消息系统)、Apache Pulsar(分布式消息系统)、Apache Flume(流式数据采集工具、从很多数据源中获取数据)、Apache Sqoop
Hadoop
在广泛意义上、Hadoop是指一个技术框架,其内部的三个核心技术分别是:HDFS(分布式存储)、MapReduce(分布式计算)、YARN(分布式资源调度)
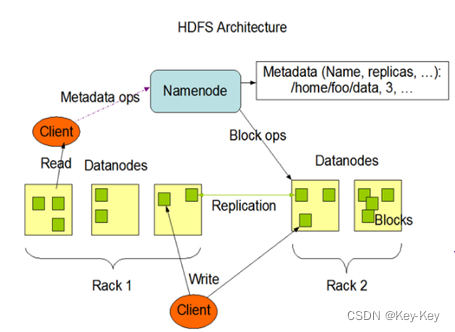
HDFS
HDFS是一个分布式存储框架。
为什么我们需要分布式存储框架呢 ---- 因为我们的大数据项目数据量太大,单机的存储是有极限的,另一方面,分布式存储中,存储效率、网络传输,磁盘读写方面也能有很高的性能提升,故我们有一个分布式存储系统是十分必要的
Hadoop框架下的分布式框架是典型的中心化模式的存储框架,另外还有去中心化的分布式框架(区块链)
HDFS的基础架构:
NameNode(主角色)(负责管理整个HDFS存储系统、以及Datanode)
Datanode(从角色)(多个)(主要负责数据的存储)
SecondaryNameNode(主角色的辅助)(处理元数据)
在我们的分布式机器上部署HDFS的过程:
在hadoop官网上下载hadoop3.3.4版本的hadoop
Hadoop部署
部署规划
我们在 node1 (4G内存,中心节点)机器上部署 Namenode、Datanode、Secondarynamenode
在 node2 (2G内存,从节点)和 node3 (2G内存,从节点)机器上部署 Datanode 信息
部署流程
将下载的hadoop.tar.gz上传到 用户目录下,再解压到 /export/server 目录中
tar -zxvf hadoop-3.3.4.tar.gz -C /export/server
之后我们进到/export/server应该可以看到一个名为hadoop的文件夹
之后为了寻找方便,给这个文件夹创建一个软连接
ln -s hadoop-3.3.6 hadoop
之后我们进入到hadoop-3.3.4文件夹内:
bin 存放hadoop的各种命令(重要)
etc 存放hadoop的配置文件(重要)
include 存放C语言的一些头文件
lib 存放linux系统的动态链接库
libexec 存放hadoop系统的脚本文件
licenses-binary 存放许可证文件
sbin 管理员程序(重要)
share 存放二进制源码(jar包)
文件配置
配置 workers 文件,这个文件在 hadoop-3.3.4/etc/hadoop 文件夹下,这个文件标注了我们的Datanode机器节点都有哪些,这里我们添加为:
node1
node2
node3
注意我们打开workers文件时,其可能会有一定的内容:我们删除 workers 文件中自带的 localhost 内容,再进行上面的添加操作
配置 hadoop-env.sh 文件,该文件标识了我们的 JAVA 环境的地址、hadoop 环境的地址、hadoop 配置文件的地址、hadoop 日志文件的地址:
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
配置core-site.xml文件,在该文件中配置了HDFS文件系统的网络通讯路径以及io操作文件的缓冲区大小:
其中fs.defaultFS指定了namenode,也就意味着我们后面在使用的时候都必须启动Namenode
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
配置 hdfs-site.xml 该文件中标注了:
dfs.datenode.data.dir.perm:新建文件的权限,我们配置为 700 代表着文件具有 rwx------- 的权限:
dfs.namenode.name.dir:NameNode 元数据的存储位置
dfs.namenode.hosts:该NameNode 所允许的datanode 是哪些
dfs.blocksize:hdfs的默认块大小
dfs.namenode.handler.count:100 能够处理的并发线程数(由于我们在本地虚拟机上运行,其CPU性能太低,这个值设置高了也没有意义)
dfs.datanode.data.dir:/data/dn 机器作为datanode,其数据存储的位置
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>node1,node2,node3</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
</configuration>
注意这里,我们配置了Namenode数据的存储位置和node1作为 Datandoe 的存储位置,故我们必须创建对应的文件夹,下面是绝对路径:
mkdir -p /data/nn
mkdir -p /data/dn
我们在node2 和 node3中要配置的是 dn 目录的路径:
mkdir -p /data/dn
之后,我们将 hadoop-3.3.4 目录复制到 node2 和 node3 同样的目录下:
scp -r hadoop-3.3.6 node2:`pwd`/
scp -r hadoop-3.3.6 node3:`pwd`/
这之后,Hadoop就在我们的三台机器上全部安装并配置完成了,最后我们还需要再配置一下环境变量
我们在/etc/profile文件中最下面配置(三台机器都得配):
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
之后:
source /etc/profile
使环境变量文件配置生效
最后,我们为了让hadoop用户也可以使用hadoop环境,我们要修改hadoop目录以及dn和nn文件的权限:
将 /data 目录、/export 目录全部都配置给 hadoop 用户
三台机器都需要修改
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export
其中 -R 的意思是 将目录与其子目录都进行修改
此时,我们的前期安装配置工作就全部完成了
进一步的前期准备
格式化存储空间
hadoop namenode -format
格式化之后,若 /data/nn 目录中存有文件的话,则证明我们格式化成功了
我们可以通过一键启动来尝试判断我们的启动是否成功:
start-dfs.sh
之后使用 jps 命令来查看运行中的 Java 环境,我们看到 namenode、datanode、secondarynamenode 时,启动就成功了,我们的子节点存在 datanode 一个进程
之后我们在浏览器里使用:
node1:9870
地址来访问 hadoop 的 Web UI 界面
我们通过下面的命令一键停止hadoop服务
stop-df.sh
一些另外的操作
我们可以进入logs文件夹下,使用tail -100 日志名 命令查看最后100行的日志情况
HDFS集群环境部署
HDFS 启停命令:
sbin/start-dfs.sh 文件一键启动HDFS集群
执行原理:
在哪个机器上执行这个脚本,HDFS就会将哪个机器当做 SecrondaryNamenode
之后HDFS会在机器上读取core-site.xml文件的内容(确定fs.defaultFS项),确认NameNode所在的机器并启动Namenode
之后HDFS会读取workers内容,确认DataNode所在的机器,并启动所有的DataNode
同样的,我们的关闭命令:
sbin/stop-dfs.sh 也会以同样的顺序读取相同的文件并对应的关闭对应的SecondaryNamenode、Namenode、Datanode
除了一键部署,这里还有单独部署的操作:
我们使用下面的命令可以只单独设置某一台机器的启停:
sbin/hadoop-deamon.sh 控制当前所在机器的启停
hadoop-deamon.sh (start|status|stop) (namenode|secondarynamenode|datanode)
bin/hdfs 此程序也用于单独控制当前机器的启停
hdfs --deamon (start|status|stop) (namenode|secondarynamenode|datanode)
Linux 中,文件系统的协议头是:file:// 我们以根路径选择文件的写法:file:/// , 最后一个 / 代表根路径
HDFS的协议:hdfs://namenode:port/ 以这个开始
假设我们有一个文件:hello.txt 在下面这个路径
Linux: file:///usr/local/hello.txt
HDFS: hdfs://node1:8020/usr/local/hello.txt
但一般情况下,我们是不需要写这两个文件头的,因为HDFS会自动帮我们写上这个
HDFS 文件操作命令:
HDFS 文件操作命令分为:
- hadoop fs
- hadoop dfs
这样两套命令体系,前者为老版本的命令体系,两者对于文件操作系统的用法完全一致,只有在某些特殊方法时会有所不同
创建文件夹:
hdfs dfs -mkdir -p /home/hadoop/qinghe
查看目录内容:
hdfs dfs -ls /...
hdfs dfs -ls -R /... 查看指定目录的内容及其子目录的所有内容
hdfs dfs -ls -h /... 查看文件内容并查看大小
将文件从Linux中上传到hdfs中:
hdfs dfs -put /... /... 前一个路径是文件在Linux中存放的位置,后一个路径是上传到HDFS中的位置
hdfs dfs -put -f /... /... 若目标文件夹已有同名文件则对其进行覆盖
hdfs dfs -put -p /... /... 保留访问和修改的时间与权限信息
查看上传的文件:
hdfs dfs -cat /... 查看文件内容
hdfs dfs -cat /... | more 以翻页的形式查看文件内容
下载HDFS中的文件到Linux:
hdfs dfs /... /... 将hdfs中的文件下载到Linux中的指定为止
hdfs dfs -f /... /... 下载hdfs中的文件,如果发生冲突则直接覆盖
hdfs dfs -p /... /... 保留访问和修改的时间与权限信息
复制操作:
hdfs dfs -cp /... /... 这两个路径都是hdfs中的路径,其会将第一个路径位置的文件复制到第二个文件,若指明了文件的名字,则其也具有重命名的效果
在HDFS中,我们对文件的修改操作只支持追加和删除!!!!不支持一点点修改!!!!!
追加操作,将Linux中的文件信息追加到Hdfs的文件中:
hdfs dfs -appendToFile /... /... 前一个文件必须存储在Linux中,第二个文件是HDFS中的文件,该指令会将Linux中的文件的内容添加到HDFS中
文件的移动:
hdfs dfs -mv /... /... 将前一个文件移动到后一个文件目录中,同样的,若指明了文件的名字,则其也具有重命名的效果
文件的删除:
hdfs dfs -rm -r /... 删除指定目录及其子目录中的所有内容
hdfs dfs -rm /... 删除指定文件,该命令不能删除文件夹
再删除中需要注意:HDFS是具有回收站功能的,但是HDFS中默认是不开启回收站机制的,我们可以通过如下配置来配置HDFS的回收站功能:
编辑如下路径的配置文件:/export/server/hadoop/etc/hadoop/core-site.xml
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>120</value>
</property>
这两个配置配置完成之后我们就开启了回收站机制
第一个配置1440指的是回收站会存储的数据存储一天,超过一天会自动清除
第二个配置指的是我们每2小时对回收站进行检查,清除超过存储时间的数据
该配置即时生效,无需重启,但配置只在对应的node节点机器上生效
如果我们配置了回收站,我们在删除文件时,就会将其移动到回收站中,回收站的位置是HDFS系统中的:
/user/hadoop/.Trash/Current
若我们在回收站开启的时候不希望将文件放到回收站中,而希望将文件直接删除,则我们需要添加 -skipTrash 参数:
hdfs dfs -rm -r -skipTrash /...
另外的操作
使用下面命令单点启动 hdfs
hdfs --daemon start datanode
关闭:
hdfs --daemon stop datanode
一键开启所有结点:
注意该命令不可以在 root 下运行
start-dfs.sh
stop-dfs.sh
新建:/opt/bin/jps-cluster.sh 创建一个可以快速查看多个节点信息的脚本:
#!/bin/bash
HOSTS=( node1 node2 node3 )
for HOST in ${HOSTS[*]}
do
echo "---------- $HOST ----------"
ssh -T $HOST << DELIMITER
jps | grep -iv jps
exit
DELIMITER
done
之后将这个脚本软连接到 /usr/bin 目录下,由于这个目录是被配置在环境变量中的,故我们将存储的软连接存放在这个目录时,就可以让这个让这个脚本直接被调用:
注意这里必须写绝对路径
ln -s /opt/bin/jps-cluster.sh /usr/bin
之后调用脚本就可以看见各机器上的 jps 情况了:
---------- node1 ----------
30980 NameNode
31676 SecondaryNameNode
31197 DataNode
---------- node2 ----------
22151 DataNode
---------- node3 ----------
21291 DataNode
Hadoop 在运行时会输出日志,这个日志被生成在 hadoop 根目录下
输出的日志是 .out 文件,但 .out 文件最后会被集成在 .log 文件下,所以我们只需要查看 .log 文件就可以了
经典案例 wordcount
词频统计经典案例:
统计文件中单词的出现次数
创建文件夹 /test_file/input 并进行输入:
echo "hello world hadoop linux hadoop" >> file1
echo "hadoop linux hadoop linux hello" >> file1
echo "hadoop linux mysql linux hadoop" >> file1
echo "hadoop linux hadoop linux hello" >> file1
echo "linux hadoop good programmer" >> file2
echo "good programmer qianfeng good" >> file2
将文件上传到 hdfs 根目录
hdfs dfs -put /test_file/input/ /
hdfs dfs ls -R /
之后我们调用下面的语句:
hadoop jar /export/server/hadoop-3.3.6/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /input /output
之后我们调用下面的命令就可以查看具体的内容了
hdfs dfs -cat /output/*
注意在生成的这条命令中,/output 文件夹必须是没有被创建的



![[AIGC <span style='color:red;'>大</span><span style='color:red;'>数据</span>基础] 浅谈<span style='color:red;'>hdfs</span>](https://img-blog.csdnimg.cn/img_convert/19fb698dcd7bf051b8d1a057ce063c81.jpeg)