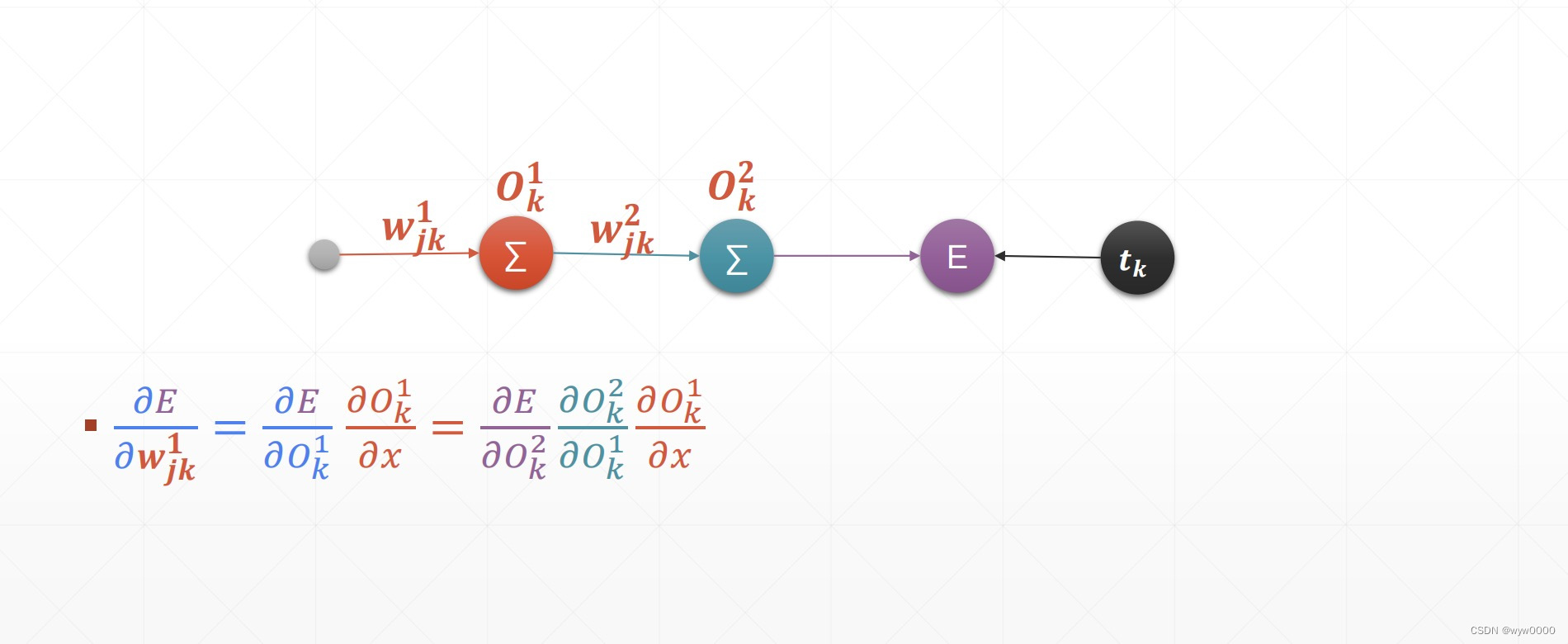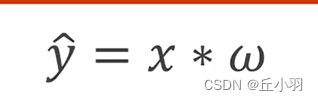一、说明
关于反向传播,我有一个精雕细刻的案例计划,但是实现了一半,目前没有顾得上继续充实,就拿论文的叙述这里先起个头,我后面将修改和促进此文的表述质量。
二、生物神经元
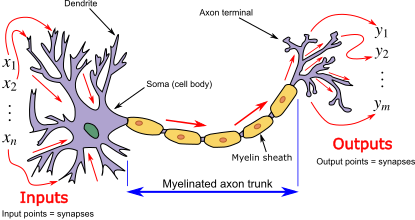
大脑是一个由大约100亿个神经元组成的复杂网络。每个神经元都有输入通道(树突)和一个输出通道(轴突),将其连接到大约 10,000 个其他神经元。神经元通过电化学信号进行交流。如果这些电输入的总和高于某个阈值,则神经元会激活或放电,这意味着它会沿着轴突将电化学信号传输到其他神经元,这些神经元的树突附着在其任何轴突上。如果总和低于阈值,则神经元不会触发。
人工神经网络(ANN)是一种大致基于大脑架构的机器学习算法。它通过人工神经元对生物神经元进行建模。人工神经网络是人工神经元的网络(逐层连接)。
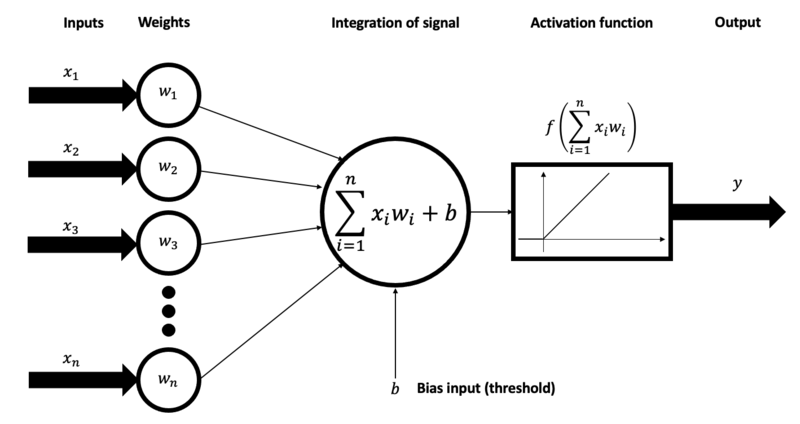
上面有时简明扼要地表示为:
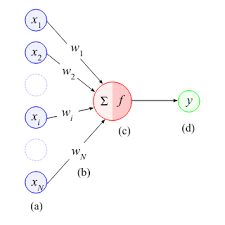
人工神经元从数据集接收一个或多个数字输入,每个输入乘以一个权重。这些权重就像重要因素一样,影响每个输入的整体影响。然后神经元执行两个步骤:
- 加权总和:它计算加权输入的总和。
- 激活:它将非线性激活函数应用于此总和。此函数根据神经元输入的组合强度确定神经元是否“触发”(输出非零值)。
然后,生成的输出被传递到网络中的下一个神经元或成为最终结果。
最初,每个神经元的每个输入的权重是随机分配的,或者使用一些启发式或迁移学习。除了与每个输入相关的权重外,还为每个神经元分配了一个额外的权重。该权重称为偏差项,与偏差项相关的输入值为 -1。这是一个偏置节点。在训练过程中,所有权重都会反复更新,直到神经元输出与输出实际值之间的差异最小化。神经元输出与实际输出之间的这种差异称为误差。
通过加权和和非线性激活函数,人工神经网络对数据执行一系列数学运算。这个过程允许他们根据他们在数据中发现的模式进行学习和预测。

深层和浅层神经网络
除了输入层和输出层外,神经网络还可以具有一个或多个中间层的神经元。这些层称为隐藏层。浅层神经网络只有一个隐藏层。具有多个隐藏层的网络称为深度神经网络。
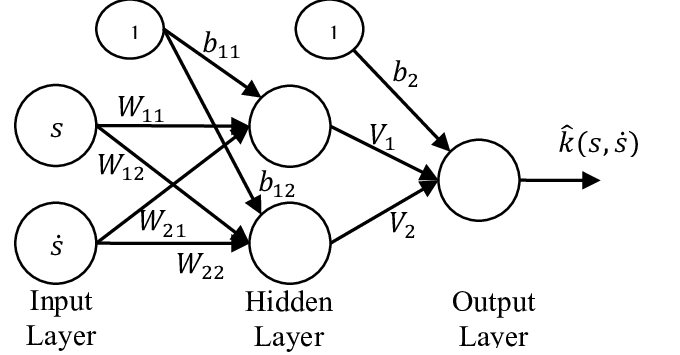
因此,在人工神经网络中,随着每层神经元数和神经元层数的增加,权重的数量也会增加。人工神经网络的训练或拟合包括从训练数据中迭代学习其权重的最佳值。使用技术优化权重
错误
包括神经网络在内的所有 ML 模型都会学习输入数据(称为训练数据)中的模式(模型或数学方程),并使用这些模式来预测看不见的数据(测试数据)的目标值。预测值与实际值不匹配将计为误差。
神经网络(就像线性回归一样)从他们的错误或错误中学习。
对于给定的数据集,通常使用量化网络所犯错误的数学函数。这种函数称为成本函数或损失函数。成本函数量化给定数据点的 DNN 输出与实际输出的接近程度。
常见的损失函数是回归任务的均方损失,分类任务的交叉熵损失。损失函数必须是可微的。
均方误差 (MSE):

三、人工神经网络的训练
该错误仅在网络的输出层变得明显。成本函数相对于网络中每个权重的梯度(偏导数)用于根据梯度下降算法指定的权重更新规则或其变体更新网络的特定权重。
函数的导数是函数值(输出)的变化与其输入(数据)的变化之比。正导数意味着函数输出随着输入的增加而增加,反之亦然。
梯度下降是一种函数最小化算法。它用于最小化网络的成本函数/损失/错误。也就是说,梯度下降计算 epoch 之后网络权重的更新(epoch 是训练数据集的传递),直到我们得到一组误差函数梯度最小(理想情况下为零)的权重。我们在这里使用的原理是,当函数处于最小值或最大值时,函数的梯度为零。
让我们将其可视化为其中一个权重 wi、相应的成本函数 J 和一个称为学习率的参数 η。

梯度下降
在梯度下降中更新权重(参数)的公式为:

梯度下降权重更新规则
高学习率(大η)会导致权重的大幅更新,可能会超过最小值并卡在局部最小值。相反,低学习率(小η)会导致收敛缓慢,甚至卡在起点附近。正确选择学习率对于高效培训很重要。
四、微积分的链式法则
如何计算损失函数的偏导数是直截了当的,因为权重定向连接到输出层或输出神经元,但是我们如何计算其偏导数,而不是直接连接到输出层的权重,即隐藏层中输入的权重。
链式法则是计算复合函数(如神经网络)导数的强大工具。
正如我们所看到的,神经网络是一个复合函数(即使是单个神经元也是权重和输入相乘的复合函数,将这些乘积相加,应用激活函数),其中每一层都获取前一层的输出并应用转换。然后将最终输出与所需结果进行比较,从而得出成本函数值。
链式法则指出,复合函数 f(g(x)) 的导数等于 f′(g(x)∗g′(x)。 即,复合函数 f(g(x)) 的导数等于函数 f 相对于 g(x) 的导数和函数 g 相对于 x 的导数的乘积。
反向传播递归应用链式法则来计算网络中每个权重的成本函数梯度,然后根据梯度下降算法的规则更新该权重。
让我们以一个非常小的神经网络为例,它只有一个输入神经元 x、一个隐藏神经元和一个输出神经元。净输出为 y′,实际输出为 y,因此误差 J(w) 为 1/n*(y−y′)^2(假设 MSE 为成本函数)。

小型神经网络
现在要找到 J wrt y′ 的导数,链式法则说我们需要找到 y′ wrt 的导数,它自己的输入参数,即 w2 和 z,(从网络中可以看出,y′ 是应用于 w2 和 z 乘积的 SoftMax 的组合),而 z 反过来是一个复合函数,由 sigmoid 组成,应用于 w1 和 x 的函数积。因此,我们需要计算以下导数,

因此,链式法则的递归应用允许我们训练非常深入的神经网络,其中包含数十亿层和数十亿(数万亿)参数。一个深度(层数)和宽度(每层神经元数)足够大的深度神经网络,在足够的数据上训练足够多的纪元,可以近似任何函数。这就是为什么今天的生成式人工智能模型已经学习了英语或印地语等自然语言的模型,或者他们已经学会了生成逼真的艺术。