Training and Validation
Download Video Features
cd data/anet/features
bash download_anet_c3d.sh
# bash download_anet_tsn.sh
# bash download_i3d_vggish_features.sh
# bash download_tsp_features.sh以download_c3d_features.sh为例
# Download the C3D feature files , refer to http://activity-net.org/challenges/2016/download.html#c3d to more details.
wget http://ec2-52-25-205-214.us-west-2.compute.amazonaws.com/data/challenge16/features/c3d/activitynet_v1-3.part-00
wget http://ec2-52-25-205-214.us-west-2.compute.amazonaws.com/data/challenge16/features/c3d/activitynet_v1-3.part-01
wget http://ec2-52-25-205-214.us-west-2.compute.amazonaws.com/data/challenge16/features/c3d/activitynet_v1-3.part-02
wget http://ec2-52-25-205-214.us-west-2.compute.amazonaws.com/data/challenge16/features/c3d/activitynet_v1-3.part-03
wget http://ec2-52-25-205-214.us-west-2.compute.amazonaws.com/data/challenge16/features/c3d/activitynet_v1-3.part-04
wget http://ec2-52-25-205-214.us-west-2.compute.amazonaws.com/data/challenge16/features/c3d/activitynet_v1-3.part-05
cat activitynet_v1-3.part-* > c3d_features.zip && unzip c3d_features.zip
python convert_c3d_h5_to_npy.py这段代码是一个命令行脚本,用于从指定的URL下载C3D特征文件,并进行后续的文件处理。
首先,使用`wget`命令下载了6个C3D特征文件:
- `activitynet_v1-3.part-00`
- `activitynet_v1-3.part-01`
- `activitynet_v1-3.part-02`
- `activitynet_v1-3.part-03`
- `activitynet_v1-3.part-04`
- `activitynet_v1-3.part-05`
下载的命令格式为`wget <URL>`,其中`<URL>`是特征文件的具体地址。
接下来,使用`cat`命令将下载的6个部分文件合并为一个名为`c3d_features.zip`的压缩文件。该命令的格式为`cat <file1> <file2> ... > <output_file>`,其中`<file1> <file2> ...`是要合并的文件列表,`<output_file>`是合并后的输出文件。
然后,使用`unzip`命令解压缩`c3d_features.zip`文件,将其中的内容提取出来。使用 && 运算符可以确保只有在前一个命令成功执行后,才会执行后面的命令。这对于确保顺序执行和避免在出现错误时执行后续命令很有用。
最后,使用`python convert_c3d_h5_to_npy.py`命令运行一个名为`convert_c3d_h5_to_npy.py`的Python脚本,该脚本可能用于将C3D特征文件从HDF5格式转换为Numpy数组格式。
总结起来,这段代码的作用是从指定的URL下载C3D特征文件,然后将其解压缩并进行进一步的处理。请注意,其中的URL地址已经发生变化,无法直接访问。
Dense Video Captioning
PDVC with learnt proposals
# Training
config_path=cfgs/anet_c3d_pdvc.yml
python train.py --cfg_path ${config_path} --gpu_id ${GPU_ID}
# The script will evaluate the model for every epoch. The results and logs are saved in `./save`.
# Evaluation
eval_folder=anet_c3d_pdvc # specify the folder to be evaluated
python eval.py --eval_folder ${eval_folder} --eval_transformer_input_type queries --gpu_id ${GPU_ID}先traing再evaluation
执行train.py
if __name__ == '__main__':
opt = opts.parse_opts()
if opt.gpu_id:
os.environ["CUDA_VISIBLE_DEVICES"] = ",".join([str(i) for i in opt.gpu_id])
if opt.disable_cudnn:
torch.backends.cudnn.enabled = False
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # to avoid OMP problem on macos
train(opt)opt = opts.parse_opts() 这行代码的作用是调用 opts 模块中的 parse_opts() 函数,解析命令行选项,并将解析结果存储在变量 opt 中,opt是一个对象或字典,以便后续代码使用这些解析结果进行相应的操作。
os.environ["CUDA_VISIBLE_DEVICES"] 是一个用于访问环境变量的方法,用于获取指定环境变量的值。
在这个特定的例子中,CUDA_VISIBLE_DEVICES 是一个环境变量,用于控制可见的CUDA设备(用于GPU计算)。它的值是一个字符串,包含一个或多个用逗号分隔的设备索引或设备ID。
通过 os.environ["CUDA_VISIBLE_DEVICES"],可以获取当前环境中已设置的 CUDA_VISIBLE_DEVICES 环境变量的值。
例如,假设在系统中设置了 CUDA_VISIBLE_DEVICES=0,1,那么使用 os.environ["CUDA_VISIBLE_DEVICES"] 将返回字符串 "0,1"。
在深度学习中,这个环境变量通常用于控制使用哪些GPU设备进行计算。通过设置不同的设备索引或ID,可以限制模型在特定的GPU设备上运行,或者在多个GPU设备上并行运行模型。这对于多GPU环境下的分布式训练或任务调度非常有用。
通过将 torch.backends.cudnn.enabled 设置为 False,可以禁用cuDNN加速。这可能是由于某些特定情况下,cuDNN的行为可能导致问题或不兼容性。禁用cuDNN可能会影响模型的性能,但有时也可能是必需的,特别是在调试或特殊需求的情况下。
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True' 这行代码的作用是设置 KMP_DUPLICATE_LIB_OK 环境变量的值为 'True',用于解决在 macOS 上使用 OpenMP 进行多线程计算时可能出现的问题。
下面进入train函数:先导库
# coding:utf-8
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import json
import time
import torch
import os
import sys
import collections
import numpy as np
from tqdm import tqdm
import torch.optim as optim
from torch.utils.data import DataLoader
from os.path import dirname, abspath
pdvc_dir = dirname(abspath(__file__))#这行代码获取当前脚本文件的绝对路径,然后使用dirname函数获取该路径的父目录路径,并将其赋值给变量pdvc_dir。这个变量将用作后续路径拼接的基准。
sys.path.insert(0, pdvc_dir)
sys.path.insert(0, os.path.join(pdvc_dir, 'densevid_eval3'))
sys.path.insert(0, os.path.join(pdvc_dir, 'densevid_eval3/SODA'))
# print(sys.path)
from eval_utils import evaluate
import opts
from tensorboardX import SummaryWriter
from misc.utils import print_alert_message, build_floder, create_logger, backup_envir, print_opt, set_seed
from data.video_dataset import PropSeqDataset, collate_fn
from pdvc.pdvc import build
from collections import OrderedDict`sys.path` 是一个 Python 的内置模块 `sys` 中的变量,它是一个包含了模块搜索路径的列表。
模块搜索路径是一个由目录路径组成的列表,当 Python 导入模块时,它会按照 `sys.path` 中的路径顺序搜索模块所在的位置。如果模块所在的路径在 `sys.path` 中,Python 就能够找到并成功导入该模块。
`sys.path` 的默认值包含了以下位置:
- 当前脚本的目录
- Python 安装路径下的标准库目录
- 环境变量 `PYTHONPATH` 指定的目录
通过修改 `sys.path`,我们可以在运行时动态地向模块搜索路径中添加新的目录,这样 Python 就可以找到并导入这些目录中的模块。
在上面提到的代码中,`sys.path.insert(0, pdvc_dir)`、`sys.path.insert(0, os.path.join(pdvc_dir, 'densevid_eval3'))` 和 `sys.path.insert(0, os.path.join(pdvc_dir, 'densevid_eval3/SODA'))` 这些语句将特定的目录路径插入到 `sys.path` 的开头,以确保 Python 在导入模块时首先搜索这些路径。这样做可以确保程序能够正确地导入所需要的模块,即使这些模块不在默认的模块搜索路径中。
通过打印 `sys.path`,我们可以查看当前的模块搜索路径,以便验证路径是否已被正确添加或检查其他路径是否存在。
接下来看train函数:train函数前面的部分是记录训练进度,存储日志,这里边的细节以后再补充
def train(opt):
set_seed(opt.seed)#设置随机种子,用于使随机过程可重复。
save_folder = build_floder(opt)#调用 build_floder 函数来构建一个保存文件夹路径,并将其赋值给 save_folder 变量。
logger = create_logger(save_folder, 'train.log')#调用 create_logger 函数创建一个日志记录器,并将其赋值给 logger 变量。该日志记录器用于记录训练过程中的日志信息。
tf_writer = SummaryWriter(os.path.join(save_folder, 'tf_summary'))#创建一个 TensorBoard 的 SummaryWriter 对象,用于将训练过程中的指标和图像数据写入 TensorBoard 日志文件。
if not opt.start_from:
backup_envir(save_folder)
logger.info('backup evironment completed !')
saved_info = {'best': {}, 'last': {}, 'history': {}, 'eval_history': {}}
# continue training
if opt.start_from:
opt.pretrain = False
infos_path = os.path.join(save_folder, 'info.json')
with open(infos_path) as f:
logger.info('Load info from {}'.format(infos_path))
saved_info = json.load(f)
prev_opt = saved_info[opt.start_from_mode[:4]]['opt']
exclude_opt = ['start_from', 'start_from_mode', 'pretrain']
for opt_name in prev_opt.keys():
if opt_name not in exclude_opt:
vars(opt).update({opt_name: prev_opt.get(opt_name)})
if prev_opt.get(opt_name) != vars(opt).get(opt_name):
logger.info('Change opt {} : {} --> {}'.format(opt_name, prev_opt.get(opt_name),
vars(opt).get(opt_name)))接下来看数据集定义
train_dataset = PropSeqDataset(opt.train_caption_file,
opt.visual_feature_folder,
opt.dict_file, True, 'gt',
opt)train_dataset是PropSeqDataset类的一个实例化对象
class PropSeqDataset(EDVCdataset):
def __init__(self, anno_file, feature_folder, translator_pickle, is_training, proposal_type,
opt):
super(PropSeqDataset, self).__init__(anno_file,
feature_folder, translator_pickle, is_training, proposal_type,
opt)PropSeqDataset类是EDVCdataset的一个子类
class EDVCdataset(Dataset):
def __init__(self, anno_file, feature_folder, translator_json, is_training, proposal_type, opt):
super(EDVCdataset, self).__init__()
self.anno = json.load(open(anno_file, 'r'))#标注文件
self.translator = Translator(translator_json, opt.vocab_size)
self.max_caption_len = opt.max_caption_len
self.keys = list(self.anno.keys())
for json_path in opt.invalid_video_json:
invalid_videos = json.load(open(json_path))
self.keys = [k for k in self.keys if k[:13] not in invalid_videos]
print('load captioning file, %d captioning loaded', len(self.keys))
self.feature_folder = feature_folder
self.feature_sample_rate = opt.feature_sample_rate
self.opt = opt
self.proposal_type = proposal_type
self.is_training = is_training
self.train_proposal_sample_num = opt.train_proposal_sample_num
self.gt_proposal_sample_num = opt.gt_proposal_sample_num
self.feature_dim = self.opt.feature_dim
self.num_queries = opt.num_queries而EDVCdataset又是Dataset的一个子类(根对上了,这样就能用dataloader了)
看一眼EDVCdataset中的属性初始化
open(anno_file, 'r'):这一部分打开由anno_file变量指定的文件,并以读取模式 ('r') 打开。open()函数返回一个文件对象,可用于读取文件的内容。json.load():这是 Python 中json模块提供的一个函数。它接受一个文件对象(或包含 JSON 文档的字符串)作为输入,并将其解析为 Python 对象。生成的对象可能是一个字典、一个列表,或者这些数据类型的组合,具体取决于 JSON 数据的结构。
事实上传递给anno_file的文件路径在opt.train_caption_file中已经给出,是train_modified.json这个文件,看一眼文件格式:
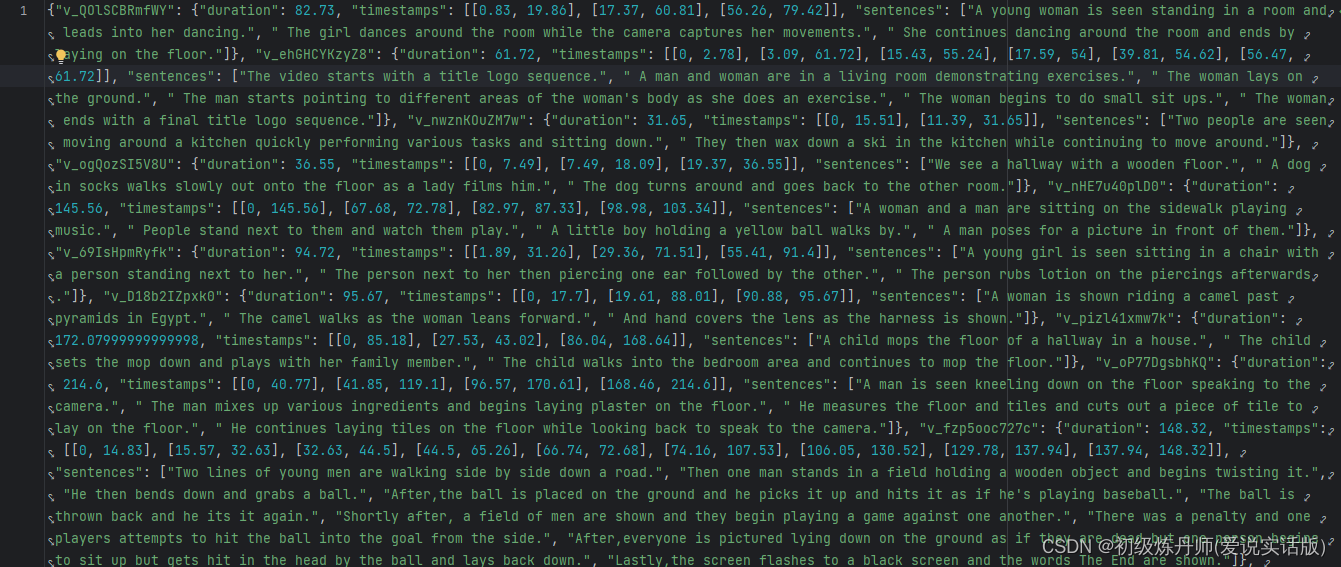
可以看到这是视频标注的真值信息
下面看传入PropSeqDataset的第二个参数opt.visual_feature_folder,点开他的配置文件,

看这个model部分
(未完待续)

























![Linux基础命令[19]-id](https://img-blog.csdnimg.cn/direct/f9f4ceeb8ff543b7a18458457e4c94ce.png)