文章目录
ORM 框架
ORM框架的底层原理可以概括为以下几个方面:
- 数据库表到对象的映射:ORM框架通过分析数据库表结构,将表的列映射为对象的属性,将表的记录映射为对象的实例。这样,应用程序可以直接操作对象,而无需关心底层数据库的操作。
- 对象到数据库表的映射:ORM框架可以通过反向工程或配置文件,将对象的属性映射为数据库表的列,将对象的实例映射为表的记录。这样,应用程序对对象的修改可以自动反映到数据库中。
- SQL生成和执行:ORM框架可以根据对象操作,自动生成对应的SQL语句,如插入、更新、删除和查询等。这些SQL语句可以通过底层的数据库连接,被执行到数据库中。
- 缓存和性能优化:ORM框架通常会提供缓存机制,将数据库查询结果缓存在内存中,以提高查询性能。
- 事务管理:ORM框架通常提供事务管理机制,应用程序可以通过框架提供的接口进行事务的提交、回滚和回滚点的设置,以保证数据的一致性和可靠性。
SQLAlchemy 简介
SQLAlchemy是一个Python的SQL工具包和对象关系映射(ORM)框架,它为应用程序开发者提供了全套的企业级持久性模型。
SQLAlchemy提供了完整的ORM实现,包括对象定义、关系定义、以及查询语言;
SQLAlchemy提供了多种数据库系统的交互,包括PostgreSQL、MySQL、SQLite、Oracle、Microsoft SQL Server、Sybase等;
SQLAlchemy 作用
- ORM(对象关系映射):SQLAlchemy允许开发者使用Python类来定义数据库表,这些类中的对象实例代表表中的行。这使得开发者可以用面向对象的方式处理数据库,而无需直接编写SQL语句。
- SQL表达式语言:除了ORM,SQLAlchemy还提供了一个SQL表达式语言,允许开发者直接编写SQL语句。这使得开发者可以在需要的时候灵活地使用SQL,而不仅仅是依赖于ORM。
- 事务管理:SQLAlchemy提供了强大的事务管理功能,包括自动提交、回滚、保存点等。
- 数据库抽象:SQLAlchemy对数据库进行了抽象,开发者可以在不更改Python代码的情况下更换数据库引擎。
- 连接池:SQLAlchemy提供了数据库连接池,可以有效地管理数据库连接,提高应用程序的性能。

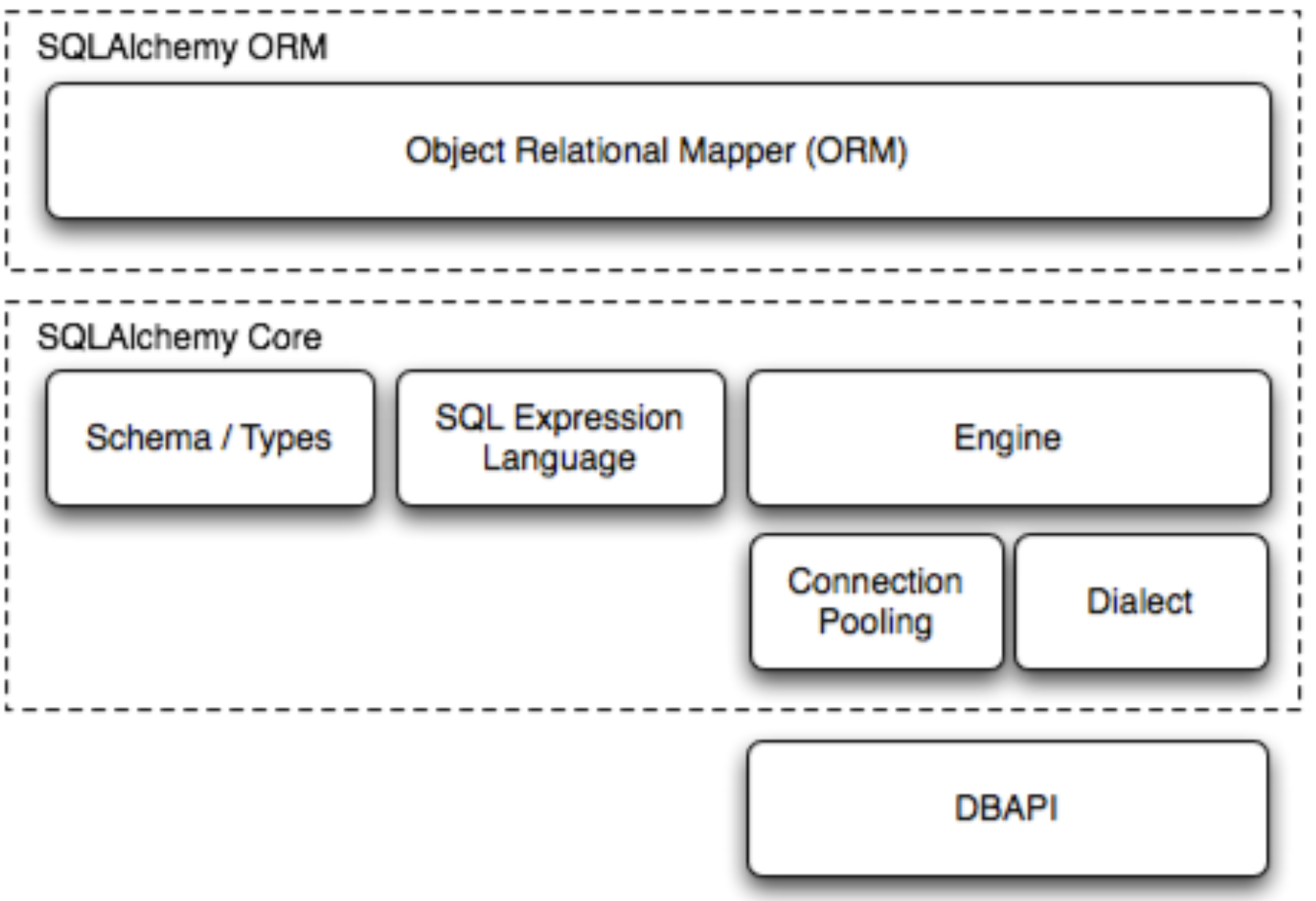
SQLAlchemy 原理
SQLAlchemy是python中常用的ORM层框架;
它的位置处于Dialect和web应用之间,自身并不包含连接数据库的功能,需要配合数据库驱动(Dialect)使用;
SQLAlchemy 的核心功能是将 Python 类映射到数据库表(或者相反),并提供了一种方便的方式来查询和操作这些表;
为了实现与数据库的交互,SQLAlchemy 需要一个数据库驱动(dialect);
这些驱动是与特定数据库系统(如 MySQL、PostgreSQL、SQLite 等)通信的桥梁。
在 SQLAlchemy 中,可以使用 pymysql作为 MySQL 的 Dialect,以便 SQLAlchemy 能够与 MySQL 数据库进行通信。
除了DBAPI之外,SQLAlchemy 还需要一个数据库连接池(Pool),用于管理数据库连接。
SQLAlchemy的工作流程:
- Dialect: 是SQLAlchemy与特定数据库交互的接口,不同的数据库有不同的SQL方言和特性,Dialect就是用来处理这些差异的;
- Engine: 是SQLAlchemy的核心部分,它通过Dialect获取数据库连接,负责处理数据库的所有交互,包括执行SQL语句、提交事务等;
- Connection Pool: 是Engine的一部分,用于管理数据库连接。它负责创建、使用和回收数据库连接,以提高性能和资源利用率。
- Metadata:保存数据库中schema信息的集合
- **Table:数据库表的对象;**可以自己定义,或者通过engine从数据库中已经存在的表中反射;当然同时也有Column作为列的对象。
- Mapped Class:映射模型类,把数据库表映射成类。
- Session:构建一个绑定到engine的session会话,是最终用来进行各种数据库操作的接口。
这个工作流程的目的是让开发者能够更简洁、更高效地与数据库进行交互,同时隐藏了底层的复杂性和差异性。
SQLAlchemy 使用流程
创建引擎(Engine):
- 引擎是SQLAlchemy的核心,它负责和数据库建立连接,并提供了一个接口来执行SQL语句。
- 创建引擎时,需要指定数据库驱动(Dialect)和数据库连接信息(如数据库地址、用户名、密码等)。
定义模型类(ORM):
- 在SQLAlchemy中,模型类通常通过继承Base类(来自SQLAlchemy的声明性基类)来定义。
- 在模型类中,使用SQLAlchemy提供的字段类型来定义属性,这些属性将映射到数据库表的列。
- 可以通过在模型类上定义关系,如relationship来建立表与表之间的关联,实现ORM的一对多、多对多等关系。
创建会话(Session):
- 会话是SQLAlchemy ORM中用于与数据库交互的主要接口。
- 会话提供了一个上下文环境,在这个环境中进行的所有数据库操作(如添加、更新、删除数据)都会被记录,并可以在事务结束时一起提交到数据库。
- 通过会话,可以查询数据库中的对象,也可以将对象保存到数据库中。
执行操作(Operation):
- 通过Base对象,可以执行数据库的表操作,如:创建表,删除表等;
- 通过会话对象,可以执行各种数据库操作,如:新增、查询、修改、删除、事物提交、事物回滚等;
数据库驱动配置
关系型数据库配置
| 数据库 | 依赖 | 连接字符串 |
|---|---|---|
| MySQL | pymysql | mysql+pymysql://username:password@localhost:3306/database_name |
| PostgreSQL | psycopg2 | postgresql://username:password@localhost:5432/database_name |
| SQLite | 不需要 | sqlite:///example.db |
| Oracle | cx_Oracle | oracle://username:password@localhost:1521/orcl |
NoSQL数据库配置
| 数据库 | 依赖 | 连接字符串 |
|---|---|---|
| MongoDB | pymongo | mongodb://username:password@localhost:27017/database_name |
| CouchDB | couchdb | couchdb://username:password@localhost:5984/database_name |
| Redis | redis | redis://localhost:6379/0 |
创建引擎(Engine)
create_engine是 SQLAlchemy 中用于创建数据库引擎的函数;
这个引擎是 SQLAlchemy 与数据库之间的桥梁,它负责处理与数据库的所有通信,包括执行 SQL 语句、提交事务等;
create_engine方法接受多个参数,这些参数用于配置如何连接到数据库以及如何处理与数据库的交互。以下是
create_engine方法的一些常用参数及其说明:
- url:
连接到数据库所需的所有信息;- echo:
一个布尔值或文件对象,用于控制 SQL 语句的输出;
如果设置为True,所有发送给数据库的 SQL 语句将会被打印到标准输出。
如果设置为一个文件对象,则 SQL 语句将被写入该文件。这对于调试非常有用。- echo_pool:
一个布尔值,用于控制连接池相关操作的输出;
如果设置为True,与连接池相关的日志信息将被打印到标准输出。- pool_size:
连接池的大小;
这决定了可以同时保持打开状态的数据库连接的最大数量。- pool_recycle:
连接在被回收之前可以保持空闲的最长时间(以秒为单位);
这对于处理某些数据库连接的问题(例如连接断开或过期)非常有用。- max_overflow:
连接池中可以超出pool_size设置的最大连接数的数量;
当连接需求超过pool_size时,额外的连接将被创建,直到达到pool_size + max_overflow的限制。- convert_unicode:
一个布尔值,决定是否将所有传递给数据库的参数转换为 Unicode;
在 Python 2 中,这可能是有用的,因为数据库可能需要 Unicode 字符串。
在 Python 3 中,这通常不是必需的,因为字符串默认就是 Unicode。- encoding:
用于设置发送到数据库的字符串的编码方式。- isolation_level:
设置事务的隔离级别;
这可以是一个字符串(如'READ_COMMITTED')或一个 SQLAlchemy 定义的常量。- echo_json:
一个布尔值,当设置为True时,输出的 SQL 语句将以 JSON 格式打印。- connect_args:
一个字典,包含传递给数据库驱动程序的额外连接参数;
这些参数取决于所使用的特定数据库和驱动程序。- strategy:
一个字符串,用于指定连接池使用的策略;
这可以是'plain','threadlocal','multi'或其他由数据库驱动程序支持的策略。
from sqlalchemy import create_engine
SQLALCHEMY_DATABASE_URL = "mysql+pymysql://root:root@10.211.55.3:3306/testdb?charset=utf8"
engine = create_engine(
url=SQLALCHEMY_DATABASE_URL,
echo=True, # 是否打印SQL
pool_size=10, # 连接池的大小,指定同时在连接池中保持的数据库连接数,默认:5
max_overflow=20, # 超出连接池大小的连接数,超过这个数量的连接将被丢弃,默认: 5
)
定义模型类(ORM)
在 SQLAlchemy 中,
Column类是用于定义表结构中的列的对象;
Column类接受多个参数来配置该列的各种属性;以下是一些常用的
Column参数及其含义:
name:
一个字符串,表示列的名称;
在大多数情况下,你可以通过简单地给
Column构造函数提供一个参数来隐式地设置这个值,但如果你需要更明确的控制,你可以使用name参数来明确指定列名。type_:
一个 SQLAlchemy 数据类型对象,定义了该列中数据的类型和约束;
例如,
Integer、String、Date等。这是
Column构造函数必需的参数,因为它定义了列中数据的类型。primary_key:
这是一个布尔值,用于标记该列是否为主键;
如果设置为
True,则这列将自动成为表的主键。nullable:
这是一个布尔值,用于指定该列是否允许存储
NULL值;如果设置为
False,则这列将不允许存储NULL值。default:
可以是一个值、一个 SQL 表达式或者一个可调用的对象;用于指定列的默认值;
当插入新记录时没有为该列提供值时,将使用此默认值。
server_default:
是一个 SQL 表达式,用于在数据库级别上设置列的默认值;
这通常用于数据库自动生成的值,如自增 ID、当前时间戳等。
unique:
一个布尔值,用于指定该列的值是否必须唯一;
如果设置为
True,则这列的值将不允许重复。index:
一个布尔值或者一个
Index对象,用于指示是否应该为该列创建索引;索引可以提高查询性能,但会增加数据库存储空间的开销。
autoincrement:
一个布尔值,用于指定是否应该自动递增该列的值;
如果设置为
True,则每次插入新记录时,该列的值将自动递增。comment:
一个字符串,用于为该列添加注释;
这些注释通常用于文档化数据库架构。
doc:
一个字符串,用于为该列添加文档字符串;
它通常用于存储有关列用途或限制的信息。
info:
一个字典,用于存储与列相关的任意附加信息;
这些信息对于应用程序来说是私有的,并且不会发送到数据库。
key:
用于指定在 Python 对象中代表该列的属性名称;
在 SQLAlchemy 的 ORM 中,这通常用于映射表列到对象的属性。
quote:
这是一个布尔值,用于指定是否应该在 SQL 语句中引用列名;
这在列名与 SQL 关键字冲突时非常有用。
onupdate:
一个 SQL 表达式,用于指定当列的值被更新时应该执行的操作;
这通常用于实现“触发器”或“自动更新”逻辑。
| 数据类型对照 | 对象 | 数据库 |
|---|---|---|
| 整数型 | Boolean() | TINYINT |
| Integer() | INT | |
| SMALLINT() | SMALLINT | |
| BIGINT() | BIGINT | |
| 浮点型 | DECIMAL() | DECIMAL |
| Float() | FLOAT | |
| REAL() | DOUBLE | |
| 字符型 | String() | VARCHAR |
| CHAR() | CHAR | |
| 日期型 | DATETIME() | DATETIME |
| DATE() | DATE | |
| TIMESTAMP() | TIMESTAMP | |
| 备注型 | Text() | TEXT |
| Unicode Text() | TINYTEXT | |
| 枚举型 | Eunm() | EUNM |
from sqlalchemy import Column, Integer, String, Enum, Date, UniqueConstraint
from sqlalchemy.ext.declarative import declarative_base
# 先建立基本映射类,后边真正的模型映射类都要继承它
Base = declarative_base()
# 定义模型映射类Student,让其继承上一步创建的基本映射类Base
class Student(Base): # 自定义类,功能生成一张表,参数必须继承SQLORM基类
__tablename__ = 'student' # 指定本类映射到student表,变量名__tablename__是固定写法
# 创建字段:字段名称(与数据库字段对应) = Column(字段类型,字段属性...)
# 指定sno映射到sno字段; sno字段为整型、为主键、为自增
sno = Column(Integer, primary_key=True, autoincrement=True, comment="学生学号")
# sname字段为字符串类型、为普通索引
sname = Column(String(10), index=True, comment="学生姓名")
# sidcard字段为字符串类型、为唯一索引
sidcard = Column(String(18), unique=True, comment="学生身份证号码")
# ssex字段为枚举值类型,默认“男”
ssex = Column(Enum("男", "女"), default="男", comment="学生性别")
# sphone字段为字符串类型
sphone = Column(String(11), comment="学生手机号码")
# sphone字段为日期类型
sbirthday = Column(Date, comment="学生生日")
# sphone字段为字符串类型
sclass = Column(String(10), comment="学生班级编号")
# 创建身份证号码和手机号码联合唯一约束
__table_args__ = (
# UniqueConstraint('字段','字段',name='索引名称') 创建唯一组合索引
UniqueConstraint('sidcard', 'sphone', name='unique_idcard_phone')
)
# object 基类也存在该方法,这里重写该方法
# __repr__方法默认返回该对象实现类的“类名+object at +内存地址”值
def __repr__(self):
return f"<Student(sname='{self.sname}', sidcard='{self.sidcard}', ssex='{self.ssex}', sphone='{self.sphone}', sbirthday='{self.sbirthday}', sclass='{self.sclass}')>"
创建会话(Session)
sessionmaker是 SQLAlchemy 中用于创建会话(Session)类的工厂函数。
session是 SQLAlchemy 的核心组件之一,它提供了与数据库交互的接口,包括添加、删除、查询和更新对象。
sessionmaker函数接受一系列参数,用于配置创建的会话的行为。以下是一些常用的
sessionmaker参数及其含义:
- bind:
这是一个可选的参数,可以是一个数据库引擎(Engine)实例或者是一个数据库连接(Connection)实例。如果提供了这个参数,那么创建的会话将默认使用这个绑定进行数据库操作。- class_:
这是一个可选参数,用于指定会话的类。通常不需要指定,因为sessionmaker会创建一个默认的会话类。但是,如果需要自定义会话的行为,可以传递一个自定义的类。- autocommit:
一个布尔值,指定会话是否自动提交事务。如果设置为True,则每次执行查询或修改操作后,事务都会自动提交。这通常用于那些不需要复杂事务管理的场景。- autoflush:
一个布尔值,指定在查询之前是否自动刷新(flush)挂起的更改。当设置为True时,会话会在执行查询之前将所有挂起的对象更改应用到数据库中。这有助于确保查询返回的是最新的数据。- expire_on_commit:
一个布尔值,指定在事务提交后是否使所有对象过期。如果设置为True,则提交事务后,所有从会话中加载的对象都将被标记为过期,下次访问这些对象时,它们将从数据库中重新加载。- query_cls:
用于指定会话中使用的查询类的类对象。这允许您自定义查询的行为。- extension:
一个可选参数,用于添加会话扩展。会话扩展可以用来修改或增强会话的行为。可以传递一个扩展实例或扩展类。- info:
一个字典,用于存储与会话相关的任意信息。这可以用来在应用程序的不同部分之间传递数据。- kwargs:
其他关键字参数,这些参数将被传递给底层的Session构造函数。
from sqlalchemy.orm import sessionmaker
# 在SQLAlchemy中,CRUD都是通过会话Session进行的,所以我们必须要先创建会话;
# 每一个SessionLocal实例就是一个数据库的session
# flush 是指发送数据库语句到数据库,但数据库不一定执行写入磁盘;
# commit 是指提交事物,将变更保存到数据库文件
SessionLocal = sessionmaker(
bind=engine, # 绑定创建的引擎
autoflush=False, # 不要自动刷新
autocommit=False, # 不要自动提交
expire_on_commit=True
)
创建数据库表
Base.metadata.create_all()是 SQLAlchemy 中用于创建所有映射到Base的表的方法。这里的
Base通常是一个继承自declarative_base()的类,它充当所有模型类的基类。
metadata是一个MetaData对象,它包含了所有与Base相关的表元数据。
create_all()方法接受一些参数来定制表创建的过程。以下是该方法的常用参数及其含义:
bind:
一个
Engine或Connection对象,指定了应该在哪个数据库上创建表;如果未指定,则使用
MetaData对象关联的默认引擎。tables:
表对象列表,表示应该创建哪些表;
如果未指定,则创建所有与
MetaData对象关联的表。checkfirst:
一个布尔值,默认为
False;如果设置为
True,则create_all()会在尝试创建表之前检查表是否已经存在;如果表已存在,则不会执行任何操作。
indexes:
一个布尔值,默认为
True;如果设置为
False,则不会创建索引。uniques:
一个布尔值,默认为
True;如果设置为
False,则不会创建唯一约束。foreign_keys:
一个布尔值,默认为
True;如果设置为
False,则不会创建外键约束。primary_keys:
一个布尔值,默认为
True;如果设置为
False,则不会创建主键约束。schema:
一个字符串,指定了表应该被创建在哪个 schema 下;
这通常用于支持多 schema 的数据库。
ddl_runner:
这是一个可选的参数,用于指定一个自定义的 DDL 运行器;
默认情况下,SQLAlchemy 使用其内部的 DDL 运行器。
kwargs:
其他关键字参数,这些参数将传递给底层的
DDL创建函数。
# 使用实例化的基本映射类,调用create_all方法向指定数据库创建模型表
Base.metadata.create_all(bind=engine) #向数据库创建指定表
# 创建成功后,控制台打印出:
# 2024-03-12 20:52:24,840 INFO sqlalchemy.engine.Engine SELECT DATABASE()
# 2024-03-12 20:52:24,840 INFO sqlalchemy.engine.Engine [raw sql] {}
# 2024-03-12 20:52:24,841 INFO sqlalchemy.engine.Engine SELECT @@sql_mode
# 2024-03-12 20:52:24,841 INFO sqlalchemy.engine.Engine [raw sql] {}
# 2024-03-12 20:52:24,842 INFO sqlalchemy.engine.Engine SELECT @@lower_case_table_names
# 2024-03-12 20:52:24,842 INFO sqlalchemy.engine.Engine [raw sql] {}
# 2024-03-12 20:52:24,843 INFO sqlalchemy.engine.Engine BEGIN (implicit)
# 2024-03-12 20:52:24,843 INFO sqlalchemy.engine.Engine DESCRIBE `testdb`.`student`
# 2024-03-12 20:52:24,843 INFO sqlalchemy.engine.Engine [raw sql] {}
# 2024-03-12 20:52:24,864 INFO sqlalchemy.engine.Engine
# CREATE TABLE student (
# sno INTEGER NOT NULL COMMENT '学生学号' AUTO_INCREMENT,
# sname VARCHAR(10) COMMENT '学生姓名',
# sidcard VARCHAR(18) COMMENT '学生身份证号码',
# ssex ENUM('男','女') COMMENT '学生性别',
# sphone VARCHAR(11) COMMENT '学生手机号码',
# sbirthday DATE COMMENT '学生生日',
# sclass VARCHAR(10) COMMENT '学生班级编号',
# PRIMARY KEY (sno),
# CONSTRAINT unique_idcard_phone UNIQUE (sidcard, sphone),
# UNIQUE (sidcard)
# )
#
#
# 2024-03-12 20:52:24,864 INFO sqlalchemy.engine.Engine [no key 0.00009s] {}
# 2024-03-12 20:52:25,013 INFO sqlalchemy.engine.Engine CREATE INDEX ix_student_sname ON student (sname)
# 2024-03-12 20:52:25,013 INFO sqlalchemy.engine.Engine [no key 0.00013s] {}
# 2024-03-12 20:52:25,050 INFO sqlalchemy.engine.Engine COMMIT
控制台反馈的创建数据库表DDL语句

数据库表属性详情

删除数据库表
Base.metadata.drop_all(engine) #向数据库删除指定表
新增数据
新增一条数据
add()
- 参数:一个或多个模型实例。
- 含义:将模型实例添加到会话中,但并不会立即执行数据库插入操作。通常需要在调用
commit()方法后,才会真正将数据插入到数据库中。
if __name__ == '__main__':
session = SessionLocal()
# 创建Faker对象
fake = Faker('zh_CN')
id_card = fake.ssn(min_age=18, max_age=60)
id_card_date = id_card[6:-4]
student1 = Student(
sname=fake.name(),
sidcard=id_card,
sphone=fake.phone_number(),
sbirthday=id_card_date,
sclass="S95001"
)
session.add(student1)
session.commit()

新增多条数据
add_all()
- 参数:模型实例的列表或集合。
- 含义:一次性添加多个模型实例到会话中,同样需要调用
commit()方法来执行数据库插入操作。
if __name__ == '__main__':
session = SessionLocal()
# 创建Faker对象
fake = Faker('zh_CN')
students = []
for i in range(5):
id_card = fake.ssn(min_age=18, max_age=60)
id_card_date = id_card[6:-4]
student = Student(
sname=fake.name(),
sidcard=id_card,
sphone=fake.phone_number(),
sbirthday=id_card_date,
sclass="S95001"
)
students.append(student)
session.add_all(students)
session.commit()

查询数据
查询一条数据
first()
- 参数:无。
- 含义:执行查询并返回第一条匹配的记录。
if __name__ == '__main__':
session = SessionLocal()
print(session.query(Student).first())
# <Student(sname='何桂花', sidcard='542527198801036507', ssex='男', sphone='13251643334', sbirthday='1988-01-03', sclass='S95001')>
查询所有数据
all()
- 参数:无。
- 含义:执行查询并返回所有匹配的记录。
if __name__ == '__main__':
session = SessionLocal()
print(session.query(Student).all())
# [<Student(sname='何桂花', sidcard='542527198801036507', ssex='男', sphone='13251643334', sbirthday='1988-01-03', sclass='S95001')>,
# <Student(sname='吴瑞', sidcard='450922198611143201', ssex='男', sphone='15555975684', sbirthday='1986-11-14', sclass='S95001')>,
# <Student(sname='苑霞', sidcard='620201198211023923', ssex='男', sphone='18701410014', sbirthday='1982-11-02', sclass='S95001')>,
# <Student(sname='刘洁', sidcard='640100198106300791', ssex='男', sphone='13579764982', sbirthday='1981-06-30', sclass='S95001')>,
# <Student(sname='娄文', sidcard='530923200103272118', ssex='男', sphone='13199326654', sbirthday='2001-03-27', sclass='S95001')>,
# <Student(sname='郑东', sidcard='410422198212040446', ssex='男', sphone='18249471034', sbirthday='1982-12-04', sclass='S95001')>]
查询过滤数据
filter():
- 参数:一个或多个条件表达式。
- 含义:在查询对象上添加过滤条件,用于筛选数据库中的记录。
filter_by()
- 参数:键值对,键为模型类的属性名,值为要匹配的值。
- 含义:根据指定的属性名和值来添加过滤条件。
if __name__ == '__main__':
session = SessionLocal()
print(session.query(Student).filter_by(sname="刘洁").first())
# <Student(sname='刘洁', sidcard='640100198106300791', ssex='男', sphone='13579764982', sbirthday='1981-06-30', sclass='S95001')>
print(session.query(Student).filter(Student.sno > 3).all())
# [<Student(sname='刘洁', sidcard='640100198106300791', ssex='男', sphone='13579764982', sbirthday='1981-06-30', sclass='S95001')>,
# <Student(sname='娄文', sidcard='530923200103272118', ssex='男', sphone='13199326654', sbirthday='2001-03-27', sclass='S95001')>,
# <Student(sname='郑东', sidcard='410422198212040446', ssex='男', sphone='18249471034', sbirthday='1982-12-04', sclass='S95001')>]
比较运算符
print(session.query(Student).filter(Student.sname == "何桂花").all())
print(session.query(Student).filter(Student.sname != "何桂花").all())
print(session.query(Student).filter(Student.sno > 3).all())
print(session.query(Student).filter(Student.sno >= 3).all())
print(session.query(Student).filter(Student.sno < 3).all())
print(session.query(Student).filter(Student.sno >= 3).all())
成员运算符
# 包含
print(session.query(Student).filter(Student.sname.in_(["何桂花", "郑东"])).all())
# 不包含
print(session.query(Student).filter(~Student.sname.in_(["何桂花", "郑东"])).all())
逻辑运算符
# 与
from sqlalchemy import and_
print(session.query(Student).filter(and_(Student.sname == "何桂花", Student.ssex == "男")).all())
# 或
from sqlalchemy import or_
print(session.query(Student).filter(or_(Student.sname == "何桂花", Student.ssex == "男")).all())
# 非
from sqlalchemy import not_
print(session.query(Student).filter(not_(Student.sname == "何桂花")).all())
排序
# order by 查询 DESC倒序
from sqlalchemy import desc
print(session.query(Student).order_by(desc(Student.sno)).all())
分组
print(session.query(Student).group_by(Student.ssex).all())
模糊查询
# 区分大小写
print(session.query(Student).filter(Student.sname.like("%ZhangSan%")).all())
# 不区分大小写
print(session.query(Student).filter(Student.sname.ilike("%ZhangSan%")).all())
分页
print(session.query(Student).offset(2).limit(3).all())
统计
print(session.query(Student).count())
print(session.query(Student).filter(Student.ssex == "女").count())
更新数据
if __name__ == '__main__':
session = SessionLocal()
# 查询要更新的对象
student = session.query(Student).filter(Student.sno == 1).first()
if student:
# 如果存在,则更新其字段
student.ssex = "女"
student.sclass = "S95002"
# 提交更改到数据库
session.commit()
print("更新成功")
else:
print("对象不存在")
删除数据
if __name__ == '__main__':
session = SessionLocal()
delete_students = session.query(Student).filter(Student.sphone.like("%135%")).all()
# 标记这些对象为删除状态
for stu in delete_students:
session.delete(stu)
# 提交更改到数据库
session.commit()
执行SQL语句
if __name__ == '__main__':
session = SessionLocal()
all_student = session.execute(text("select * from student")).all()
for stu in all_student:
print(stu)
# (1, '何桂花', '542527198801036507', '女', '13251643334', datetime.date(1988, 1, 3), 'S95002')
# (2, '吴瑞', '450922198611143201', '男', '15555975684', datetime.date(1986, 11, 14), 'S95001')
# (3, '苑霞', '620201198211023923', '男', '18701410014', datetime.date(1982, 11, 2), 'S95001')
# (5, '娄文', '530923200103272118', '男', '13199326654', datetime.date(2001, 3, 27), 'S95001')
# (6, '郑东', '410422198212040446', '男', '18249471034', datetime.date(1982, 12, 4), 'S95001')
多表联合查询
在使用SQLAlchemy进行多表联合查询时,可以通过多种方式来实现;
包括内连接(INNER JOIN)、外连接(LEFT OUTER JOIN、RIGHT OUTER JOIN、FULL OUTER JOIN)以及交叉连接(CROSS JOIN)。
基本设置
首先,定义两个模型User和Address,它们通过外键关联
from sqlalchemy import create_engine, Column, Integer, String, ForeignKey
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship, sessionmaker
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
addresses = relationship("Address", back_populates="user")
class Address(Base):
__tablename__ = 'addresses'
id = Column(Integer, primary_key=True)
email_address = Column(String, nullable=False)
user_id = Column(Integer, ForeignKey('users.id'))
user = relationship("User", back_populates="addresses")
内连接(INNER JOIN)
内连接返回两个表中匹配的记录
# 创建Session
engine = create_engine('sqlite:///:memory:', echo=True)
Base.metadata.create_all(engine)
Session = sessionmaker(bind=engine)
session = Session()
# 内连接查询
result = session.query(User, Address).join(Address).filter(Address.email_address == 'example@example.com').all()
for user, address in result:
print(user.name, address.email_address)
外连接(LEFT OUTER JOIN)
外连接返回左表的所有记录,以及右表中匹配的记录。
如果右表中没有匹配的记录,则结果中这部分的值为
NULL。
# 外连接查询
result = session.query(User, Address).outerjoin(Address).all()
for user, address in result:
print(user.name, address.email_address if address else 'No Address')
使用select_from()指定JOIN的起始表
当需要明确指定
JOIN的起始表时,可以使用select_from()方法。
# 使用select_from明确指定JOIN的起始表
result = session.query(User.name, Address.email_address).select_from(Address).join(User).all()
for name, email_address in result:
print(name, email_address)
使用relationship()进行自动JOIN
如果在模型间定义了
relationship(),SQLAlchemy可以自动处理JOIN操作,使查询更简洁。
# 使用relationship自动JOIN
result = session.query(User).join(User.addresses).all() # 自动JOIN Address
for user in result:
print(user.name, [address.email_address for address in user.addresses])
多表连接
可以同时连接多个表,进行复杂的查询操作。
# 假设还有一个Order模型与User关联
class Order(Base):
__tablename__ = 'orders'
id = Column(Integer, primary_key=True)
user_id = Column(Integer, ForeignKey('users.id'))
total = Column(Integer)
user = relationship("User", back_populates="orders")
User.orders = relationship("Order", back_populates="user")
# 连接User、Address和Order表
result = session.query(User.name, Address.email_address, Order.total).\
join(Address).\
join(Order).\
filter(User.name == 'Alice').\
all()
for name, email_address, total in result:
print(name, email_address, total)
这些示例展示了使用SQLAlchemy进行多表联合查询的不同方法,包括内连接、外连接以及如何利用
relationship()进行自动JOIN。通过这些技巧,可以灵活地构建出复杂的查询逻辑,以满足各种数据检索需求。
总结
SQLAlchemy,作为Python的ORM(对象关系映射)框架,不仅简化了数据库操作,而且为开发者提供了丰富的查询接口;
它允许开发者以面向对象的方式与数据库进行交互,将数据库表映射为Python类,字段映射为类属性,从而实现了数据的增删改查;
此外,SQLAlchemy还支持多种数据库引擎,确保了代码的可移植性;
通过SQLAlchemy,开发者能够更加高效、安全地管理数据库,从而专注于业务逻辑的实现。
































![[长城杯 2021 院校组]funny_js](https://img-blog.csdnimg.cn/img_convert/e25fe9a84df99860f734840689b06a2a.png)