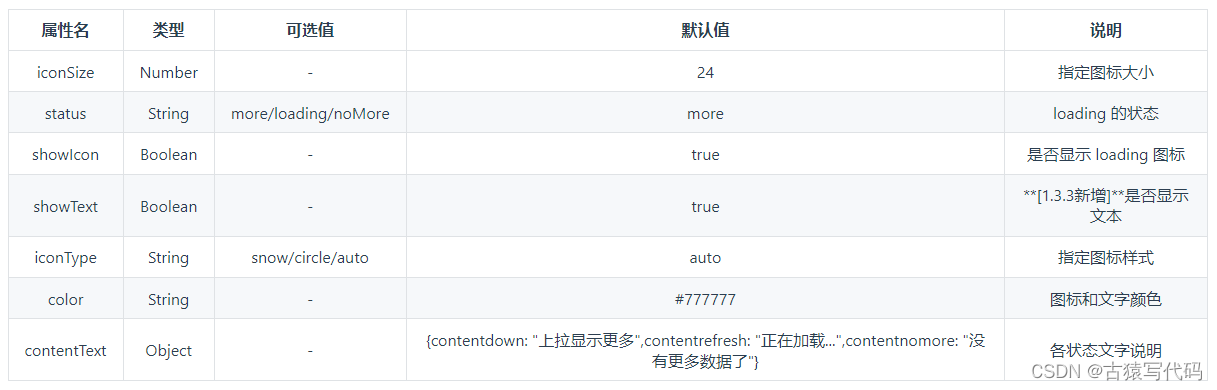
基于transformer的英译中翻译模型代码片段
基于Transformer的英译中翻译模型在PyTorch中实现,通常遵循以下关键步骤:
原理概览(温故知新)
Transformer模型由Vaswani等人在论文《Attention is All You Need》中提出,它摒弃了循环神经网络(RNNs)和卷积神经网络(CNNs),完全依赖于自注意力机制来捕捉长距离依赖关系。在机器翻译任务中,Transformer被应用于序列到序列(Sequence-to-Sequence)的学习框架,主要包括编码器(Encoder)和解码器(Decoder)两大部分。
编码器:负责读取源语言(英语)句子并生成其上下文相关的表示。每一层包括多头自注意力机制(Multi-Head Self-Attention)和前馈神经网络(Position-wise Feed-Forward Networks, FFNs),同时每层之间加入残差连接(Residual Connections)和层归一化(Layer Normalization)。
解码器:同样包含多头自注意力机制,但它在生成目标语言(中文)的同时会考虑编码器的输出,并且引入了掩码机制以防止未来位置的信息泄露。解码器的最后一层输出用于预测下一个词汇的概率分布。
实现步骤
数据预处理:
- 使用工具如
spacy对源语言和目标语言进行分词、添加特殊标记(如开始和结束符号)、构建词汇表及对应的嵌入矩阵。 - 将文本序列转化为Token索引序列,并填充至固定长度或使用动态padding方法适应变长输入。
- 划分训练集、验证集和测试集。
- 使用工具如
模型搭建:
- 定义编码器和解码器,每个部分都是由多个Transformer层堆叠而成。
- 初始化词嵌入层,然后分别构建编码器和解码器的层级结构。
- 在解码器中实现自注意力和源-目标注意力机制。
损失函数设定:
- 由于这是个分类问题,一般会使用交叉熵损失函数,针对每个时间步的预测词汇与实际目标词汇计算损失。
训练过程:
- 使用训练集数据进行模型训练,包括前向传播、反向传播、优化器更新权重。
- 可以采用梯度裁剪、学习率调整策略以提升训练效果和稳定性。
评估与推断:
- 使用验证集评估模型性能,如BLEU分数或其他翻译质量评估指标。
- 在推断阶段,采取自回归的方式逐词生成目标语言翻译结果,通常采用贪心搜索或beam search策略。
微调与迭代:
- 根据验证集表现调整模型参数,可能需要对模型进行微调或调整超参数以提高翻译质量。
具体到PyTorch代码实现时,可以利用torch.nn.Transformer模块直接构建Transformer模型的核心组件,或者根据论文自行编写各层结构,封装成完整的编码器和解码器类。
实现代码示例
创建模型
import math
import copy
from torch.autograd import Variable
import torch
import torch.nn as nn
import torch.nn.functional as F
DEVICE = config.device
class LabelSmoothing(nn.Module):
"""Implement label smoothing."""
def __init__(self, size, padding_idx, smoothing=0.0):
super(LabelSmoothing, self).__init__()
self.criterion = nn.KLDivLoss(size_average=False)
self.padding_idx = padding_idx
self.confidence = 1.0 - smoothing
self.smoothing = smoothing
self.size = size
self.true_dist = None
def forward(self, x, target):
assert x.size(1) == self.size
true_dist = x.data.clone()
true_dist.fill_(self.smoothing / (self.size - 2))
true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence)
true_dist[:, self.padding_idx] = 0
mask = torch.nonzero(target.data == self.padding_idx)
if mask.dim() > 0:
true_dist.index_fill_(0, mask.squeeze(), 0.0)
self.true_dist = true_dist
return self.criterion(x, Variable(true_dist, requires_grad=False))
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
# Embedding层
self.lut = nn.Embedding(vocab, d_model)
# Embedding维数
self.d_model = d_model
def forward(self, x):
# 返回x对应的embedding矩阵(需要乘以math.sqrt(d_model))
return self.lut(x) * math.sqrt(self.d_model)
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# 初始化一个size为 max_len(设定的最大长度)×embedding维度 的全零矩阵
# 来存放所有小于这个长度位置对应的positional embedding
pe = torch.zeros(max_len, d_model, device=DEVICE)
# 生成一个位置下标的tensor矩阵(每一行都是一个位置下标)
"""
形式如:
tensor([[0.],
[1.],
[2.],
[3.],
[4.],
...])
"""
position = torch.arange(0., max_len, device=DEVICE).unsqueeze(1)
# 这里幂运算太多,我们使用exp和log来转换实现公式中pos下面要除以的分母(由于是分母,要注意带负号)
div_term = torch.exp(torch.arange(0., d_model, 2, device=DEVICE) * -(math.log(10000.0) / d_model))
# 根据公式,计算各个位置在各embedding维度上的位置纹理值,存放到pe矩阵中
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# 加1个维度,使得pe维度变为:1×max_len×embedding维度
# (方便后续与一个batch的句子所有词的embedding批量相加)
pe = pe.unsqueeze(0)
# 将pe矩阵以持久的buffer状态存下(不会作为要训练的参数)
self.register_buffer('pe', pe)
def forward(self, x):
# 将一个batch的句子所有词的embedding与已构建好的positional embeding相加
# (这里按照该批次数据的最大句子长度来取对应需要的那些positional embedding值)
x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)
return self.dropout(x)
def attention(query, key, value, mask=None, dropout=None):
# 将query矩阵的最后一个维度值作为d_k
d_k = query.size(-1)
# 将key的最后两个维度互换(转置),才能与query矩阵相乘,乘完了还要除以d_k开根号
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# 如果存在要进行mask的内容,则将那些为0的部分替换成一个很大的负数
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 将mask后的attention矩阵按照最后一个维度进行softmax
p_attn = F.softmax(scores, dim=-1)
# 如果dropout参数设置为非空,则进行dropout操作
if dropout is not None:
p_attn = dropout(p_attn)
# 最后返回注意力矩阵跟value的乘积,以及注意力矩阵
return torch.matmul(p_attn, value), p_attn
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
super(MultiHeadedAttention, self).__init__()
# 保证可以整除
assert d_model % h == 0
# 得到一个head的attention表示维度
self.d_k = d_model // h
# head数量
self.h = h
# 定义4个全连接函数,供后续作为WQ,WK,WV矩阵和最后h个多头注意力矩阵concat之后进行变换的矩阵
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
if mask is not None:
mask = mask.unsqueeze(1)
# query的第一个维度值为batch size
nbatches = query.size(0)
# 将embedding层乘以WQ,WK,WV矩阵(均为全连接)
# 并将结果拆成h块,然后将第二个和第三个维度值互换(具体过程见上述解析)
query, key, value = [l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 调用上述定义的attention函数计算得到h个注意力矩阵跟value的乘积,以及注意力矩阵
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)
# 将h个多头注意力矩阵concat起来(注意要先把h变回到第三维的位置)
x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)
# 使用self.linears中构造的最后一个全连接函数来存放变换后的矩阵进行返回
return self.linears[-1](x)
class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
# 初始化α为全1, 而β为全0
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
# 平滑项
self.eps = eps
def forward(self, x):
# 按最后一个维度计算均值和方差
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
# 返回Layer Norm的结果
return self.a_2 * (x - mean) / torch.sqrt(std ** 2 + self.eps) + self.b_2
class SublayerConnection(nn.Module):
"""
SublayerConnection的作用就是把Multi-Head Attention和Feed Forward层连在一起
只不过每一层输出之后都要先做Layer Norm再残差连接
sublayer是lambda函数
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
# 返回Layer Norm和残差连接后结果
return x + self.dropout(sublayer(self.norm(x)))
def clones(module, N):
"""克隆模型块,克隆的模型块参数不共享"""
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(F.relu(self.w_1(x))))
class Encoder(nn.Module):
# layer = EncoderLayer
# N = 6
def __init__(self, layer, N):
super(Encoder, self).__init__()
# 复制N个encoder layer
self.layers = clones(layer, N)
# Layer Norm
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"""
使用循环连续eecode N次(这里为6次)
这里的Eecoderlayer会接收一个对于输入的attention mask处理
"""
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
class EncoderLayer(nn.Module):
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
# SublayerConnection的作用就是把multi和ffn连在一起
# 只不过每一层输出之后都要先做Layer Norm再残差连接
self.sublayer = clones(SublayerConnection(size, dropout), 2)
# d_model
self.size = size
def forward(self, x, mask):
# 将embedding层进行Multi head Attention
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
# 注意到attn得到的结果x直接作为了下一层的输入
return self.sublayer[1](x, self.feed_forward)
class Decoder(nn.Module):
def __init__(self, layer, N):
super(Decoder, self).__init__()
# 复制N个encoder layer
self.layers = clones(layer, N)
# Layer Norm
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
"""
使用循环连续decode N次(这里为6次)
这里的Decoderlayer会接收一个对于输入的attention mask处理
和一个对输出的attention mask + subsequent mask处理
"""
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
class DecoderLayer(nn.Module):
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
# Self-Attention
self.self_attn = self_attn
# 与Encoder传入的Context进行Attention
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
# 用m来存放encoder的最终hidden表示结果
m = memory
# Self-Attention:注意self-attention的q,k和v均为decoder hidden
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
# Context-Attention:注意context-attention的q为decoder hidden,而k和v为encoder hidden
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
class Transformer(nn.Module):
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(Transformer, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
def forward(self, src, tgt, src_mask, tgt_mask):
# encoder的结果作为decoder的memory参数传入,进行decode
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
class Generator(nn.Module):
# vocab: tgt_vocab
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
# decode后的结果,先进入一个全连接层变为词典大小的向量
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
# 然后再进行log_softmax操作(在softmax结果上再做多一次log运算)
return F.log_softmax(self.proj(x), dim=-1)
def make_model(src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1):
c = copy.deepcopy
# 实例化Attention对象
attn = MultiHeadedAttention(h, d_model).to(DEVICE)
# 实例化FeedForward对象
ff = PositionwiseFeedForward(d_model, d_ff, dropout).to(DEVICE)
# 实例化PositionalEncoding对象
position = PositionalEncoding(d_model, dropout).to(DEVICE)
# 实例化Transformer模型对象
model = Transformer(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout).to(DEVICE), N).to(DEVICE),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout).to(DEVICE), N).to(DEVICE),
nn.Sequential(Embeddings(d_model, src_vocab).to(DEVICE), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab).to(DEVICE), c(position)),
Generator(d_model, tgt_vocab)).to(DEVICE)
# This was important from their code.
# Initialize parameters with Glorot / fan_avg.
for p in model.parameters():
if p.dim() > 1:
# 这里初始化采用的是nn.init.xavier_uniform
nn.init.xavier_uniform_(p)
return model.to(DEVICE)
def batch_greedy_decode(model, src, src_mask, max_len=64, start_symbol=2, end_symbol=3):
batch_size, src_seq_len = src.size()
results = [[] for _ in range(batch_size)]
stop_flag = [False for _ in range(batch_size)]
count = 0
memory = model.encode(src, src_mask)
tgt = torch.Tensor(batch_size, 1).fill_(start_symbol).type_as(src.data)
for s in range(max_len):
tgt_mask = subsequent_mask(tgt.size(1)).expand(batch_size, -1, -1).type_as(src.data)
out = model.decode(memory, src_mask, Variable(tgt), Variable(tgt_mask))
prob = model.generator(out[:, -1, :])
pred = torch.argmax(prob, dim=-1)
tgt = torch.cat((tgt, pred.unsqueeze(1)), dim=1)
pred = pred.cpu().numpy()
for i in range(batch_size):
# print(stop_flag[i])
if stop_flag[i] is False:
if pred[i] == end_symbol:
count += 1
stop_flag[i] = True
else:
results[i].append(pred[i].item())
if count == batch_size:
break
return results
def greedy_decode(model, src, src_mask, max_len=64, start_symbol=2, end_symbol=3):
"""传入一个训练好的模型,对指定数据进行预测"""
# 先用encoder进行encode
memory = model.encode(src, src_mask)
# 初始化预测内容为1×1的tensor,填入开始符('BOS')的id,并将type设置为输入数据类型(LongTensor)
ys = torch.ones(1, 1).fill_(start_symbol).type_as(src.data)
# 遍历输出的长度下标
for i in range(max_len - 1):
# decode得到隐层表示
out = model.decode(memory,
src_mask,
Variable(ys),
Variable(subsequent_mask(ys.size(1)).type_as(src.data)))
# 将隐藏表示转为对词典各词的log_softmax概率分布表示
prob = model.generator(out[:, -1])
# 获取当前位置最大概率的预测词id
_, next_word = torch.max(prob, dim=1)
next_word = next_word.data[0]
if next_word == end_symbol:
break
# 将当前位置预测的字符id与之前的预测内容拼接起来
ys = torch.cat([ys,
torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=1)
return ys
模型训练
import torch
import torch.nn as nn
from torch.autograd import Variable
import logging
import sacrebleu
from tqdm import tqdm
import config
from beam_decoder import beam_search
from model import batch_greedy_decode
from utils import chinese_tokenizer_load
def run_epoch(data, model, loss_compute):
total_tokens = 0.
total_loss = 0.
for batch in tqdm(data):
out = model(batch.src, batch.trg, batch.src_mask, batch.trg_mask)
loss = loss_compute(out, batch.trg_y, batch.ntokens)
total_loss += loss
total_tokens += batch.ntokens
return total_loss / total_tokens
def train(train_data, dev_data, model, model_par, criterion, optimizer):
"""训练并保存模型"""
# 初始化模型在dev集上的最优Loss为一个较大值
best_bleu_score = 0.0
early_stop = config.early_stop
for epoch in range(1, config.epoch_num + 1):
# 模型训练
model.train()
train_loss = run_epoch(train_data, model_par,
MultiGPULossCompute(model.generator, criterion, config.device_id, optimizer))
logging.info("Epoch: {}, loss: {}".format(epoch, train_loss))
# 模型验证
model.eval()
dev_loss = run_epoch(dev_data, model_par,
MultiGPULossCompute(model.generator, criterion, config.device_id, None))
bleu_score = evaluate(dev_data, model)
logging.info('Epoch: {}, Dev loss: {}, Bleu Score: {}'.format(epoch, dev_loss, bleu_score))
# 如果当前epoch的模型在dev集上的loss优于之前记录的最优loss则保存当前模型,并更新最优loss值
if bleu_score > best_bleu_score:
torch.save(model.state_dict(), config.model_path)
best_bleu_score = bleu_score
early_stop = config.early_stop
logging.info("-------- Save Best Model! --------")
else:
early_stop -= 1
logging.info("Early Stop Left: {}".format(early_stop))
if early_stop == 0:
logging.info("-------- Early Stop! --------")
break
class LossCompute:
"""简单的计算损失和进行参数反向传播更新训练的函数"""
def __init__(self, generator, criterion, opt=None):
self.generator = generator
self.criterion = criterion
self.opt = opt
def __call__(self, x, y, norm):
x = self.generator(x)
loss = self.criterion(x.contiguous().view(-1, x.size(-1)),
y.contiguous().view(-1)) / norm
loss.backward()
if self.opt is not None:
self.opt.step()
if config.use_noamopt:
self.opt.optimizer.zero_grad()
else:
self.opt.zero_grad()
return loss.data.item() * norm.float()
class MultiGPULossCompute:
"""A multi-gpu loss compute and train function."""
def __init__(self, generator, criterion, devices, opt=None, chunk_size=5):
# Send out to different gpus.
self.generator = generator
self.criterion = nn.parallel.replicate(criterion, devices=devices)
self.opt = opt
self.devices = devices
self.chunk_size = chunk_size
def __call__(self, out, targets, normalize):
total = 0.0
generator = nn.parallel.replicate(self.generator, devices=self.devices)
out_scatter = nn.parallel.scatter(out, target_gpus=self.devices)
out_grad = [[] for _ in out_scatter]
targets = nn.parallel.scatter(targets, target_gpus=self.devices)
# Divide generating into chunks.
chunk_size = self.chunk_size
for i in range(0, out_scatter[0].size(1), chunk_size):
# Predict distributions
out_column = [[Variable(o[:, i:i + chunk_size].data,
requires_grad=self.opt is not None)]
for o in out_scatter]
gen = nn.parallel.parallel_apply(generator, out_column)
# Compute loss.
y = [(g.contiguous().view(-1, g.size(-1)),
t[:, i:i + chunk_size].contiguous().view(-1))
for g, t in zip(gen, targets)]
loss = nn.parallel.parallel_apply(self.criterion, y)
# Sum and normalize loss
l_ = nn.parallel.gather(loss, target_device=self.devices[0])
l_ = l_.sum() / normalize
total += l_.data
# Backprop loss to output of transformer
if self.opt is not None:
l_.backward()
for j, l in enumerate(loss):
out_grad[j].append(out_column[j][0].grad.data.clone())
# Backprop all loss through transformer.
if self.opt is not None:
out_grad = [Variable(torch.cat(og, dim=1)) for og in out_grad]
o1 = out
o2 = nn.parallel.gather(out_grad,
target_device=self.devices[0])
o1.backward(gradient=o2)
self.opt.step()
if config.use_noamopt:
self.opt.optimizer.zero_grad()
else:
self.opt.zero_grad()
return total * normalize
def evaluate(data, model, mode='dev', use_beam=True):
"""在data上用训练好的模型进行预测,打印模型翻译结果"""
sp_chn = chinese_tokenizer_load()
trg = []
res = []
with torch.no_grad():
# 在data的英文数据长度上遍历下标
for batch in tqdm(data):
# 对应的中文句子
cn_sent = batch.trg_text
src = batch.src
src_mask = (src != 0).unsqueeze(-2)
if use_beam:
decode_result, _ = beam_search(model, src, src_mask, config.max_len,
config.padding_idx, config.bos_idx, config.eos_idx,
config.beam_size, config.device)
else:
decode_result = batch_greedy_decode(model, src, src_mask,
max_len=config.max_len)
decode_result = [h[0] for h in decode_result]
translation = [sp_chn.decode_ids(_s) for _s in decode_result]
trg.extend(cn_sent)
res.extend(translation)
if mode == 'test':
with open(config.output_path, "w") as fp:
for i in range(len(trg)):
line = "idx:" + str(i) + trg[i] + '|||' + res[i] + '\n'
fp.write(line)
trg = [trg]
bleu = sacrebleu.corpus_bleu(res, trg, tokenize='zh')
return float(bleu.score)
def test(data, model, criterion):
with torch.no_grad():
# 加载模型
model.load_state_dict(torch.load(config.model_path))
model_par = torch.nn.DataParallel(model)
model.eval()
# 开始预测
test_loss = run_epoch(data, model_par,
MultiGPULossCompute(model.generator, criterion, config.device_id, None))
bleu_score = evaluate(data, model, 'test')
logging.info('Test loss: {}, Bleu Score: {}'.format(test_loss, bleu_score))
def translate(src, model, use_beam=True):
"""用训练好的模型进行预测单句,打印模型翻译结果"""
sp_chn = chinese_tokenizer_load()
with torch.no_grad():
model.load_state_dict(torch.load(config.model_path))
model.eval()
src_mask = (src != 0).unsqueeze(-2)
if use_beam:
decode_result, _ = beam_search(model, src, src_mask, config.max_len,
config.padding_idx, config.bos_idx, config.eos_idx,
config.beam_size, config.device)
decode_result = [h[0] for h in decode_result]
else:
decode_result = batch_greedy_decode(model, src, src_mask, max_len=config.max_len)
translation = [sp_chn.decode_ids(_s) for _s in decode_result]
print(translation[0])