提示:sklearn.model_selection.learning_curve的详细介绍
文章目录
1、需求分析
通过参数train_size选取不同规模的数据集,再分别在不同规模的数据集上做交叉验证,通过参数cv选取交叉验证的类型;
例如:我们想选取含有1000个样本的数据集的10%,33%,55%,78%,100%的数据做实验,探究不同数据量下模型的预测准确度,选取不同规模的数据集后,我们又想分别在不同规模的数据集下做一下5折交叉验证。我们就可以设train_size=array([0.1, 0.33, 0.55, 0.78, 1.]), cv=5。
2、learning_curve主要输出参数
train_sizes_abs:返回生成的训练的样本数,如[ 80 , 260 , 620,800 ],80=0.1×1000×[(5-1)/5]即train_sizes_abs[i]=train_size[i]×样本数×(cv对应每一次交叉验证的训练样本占总样本的百分比)
train_scores:返回训练集分数,该矩阵为( len ( train_sizes_abs ) , cv分割数 )即(5,5)维的分数,每行数据代表该样本数对应不同折的分数。
test_scores:同train_scores,只不过是这个对应的是测试集分数
3、learning_curve主要参数
X:特征矩阵,包含输入样本的特征。
y:目标变量,包含与输入样本对应的真实标签。
train_sizes:一个数组或可迭代对象,表示训练集的不同大小的比例。每个比例都将生成一个学习曲线点。
cv:用于交叉验证的折数或交叉验证迭代器。
scoring:用于评估模型性能的指标。常见的指标包括准确率(accuracy)、均方误差(mean_squared_error)、R平方(r2_score)等。
shuffle:是否在每次迭代前对数据进行洗牌,默认为False。
random_state:随机数种子,用于控制随机性。
estimator:用于拟合数据的机器学习模型,例如分类器或回归器。
4、learning_curve作用
5、learning_curve代码
代码如下(示例):
from sklearn.metrics import confusion_matrix as CM
import numpy as np
import matplotlib.pyplot as plt
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.tree import DecisionTreeClassifier as DTC
from sklearn.linear_model import LogisticRegression as LR
from sklearn.datasets import load_digits
from sklearn.model_selection import learning_curve # 画学习曲线的类
from sklearn.model_selection import ShuffleSplit # 设定交叉验证模式的类
from time import time
import datetime
from sklearn.metrics import brier_score_loss as bsl
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression as LR
from sklearn.model_selection import train_test_split
def plot_learning_curve(estimator, title, X, y,
ax, # 选择子图
ylim=None, # 设置纵坐标的取值范围
cv=None, # 交叉验证
n_jobs=None # 设定索要使用的线程
):
train_sizes, train_scores, test_scores = learning_curve(estimator, X, y
, cv=cv, n_jobs=n_jobs)
# learning_curve() 是一个可视化工具,用于评估机器学习模型的性能和训练集大小之间的关系。它可以帮助我们理解模型在不同数据规模下的训练表现,
# 进而判断模型是否出现了欠拟合或过拟合的情况。该函数会生成一条曲线,横轴表示不同大小的训练集,纵轴表示训练集和交叉验证集上的评估指标(例如
# 准确率、损失等)。通过观察曲线,我们可以得出以下结论:
# 1,训练集误差和交叉验证集误差之间的关系:当训练集规模较小时,模型可能过度拟合,训练集误差较低,交叉验证集误差较高;当训练集规模逐渐增大时,
# 模型可能更好地泛化,两者的误差逐渐趋于稳定。
# 2,训练集误差和交叉验证集误差对训练集规模的响应:通过观察曲线的斜率,我们可以判断模型是否存在高方差(过拟合)或高偏差(欠拟合)的问题。如果
# 训练集和交叉验证集的误差都很高,且二者之间的间隔较大,说明模型存在高偏差;如果训练集误差很低而交叉验证集误差较高,且二者的间隔也较大,说
# 明模型存在高方差。
# cv : int:交叉验证生成器或可迭代的可选项,确定交叉验证拆分策略。v的可能输入是:
# - 无,使用默认的3倍交叉验证,
# - 整数,指定折叠数。
# - 要用作交叉验证生成器的对象。
# - 可迭代的yielding训练/测试分裂。
# ShuffleSplit:我们这里设置cv,交叉验证使用ShuffleSplit方法,一共取得100组训练集与测试集,
# 每次的测试集为20%,它返回的是每组训练集与测试集的下标索引,由此可以知道哪些是train,那些是test。
# n_jobs : 整数,可选并行运行的作业数(默认值为1)。windows开多线程需要
ax.set_title(title)
if ylim is not None:
ax.set_ylim(*ylim)
# *是可以接受任意数量的参数
# 而 ** 可以接受任意数量的指定键值的参数
# def m(*args,**kwargs):
# print(args)
# print(kwargs)
# m(1,2,a=1,b=2)
# #args:(1,2),kwargs:{'b': 2, 'a': 1}
ax.set_xlabel("Training examples")
ax.set_ylabel("Score")
ax.grid() # 显示网格作为背景,不是必须
ax.plot(train_sizes, np.mean(train_scores, axis=1), 'o-'
, color="r", label="Training score")
ax.plot(train_sizes, np.mean(test_scores, axis=1), 'o-'
, color="g", label="Test score")
ax.legend(loc="best")
return ax
digits = load_digits()
X, y = digits.data, digits.target
print(X.shape)
print(X)
title = ["Naive Bayes", "DecisionTree", "SVM, RBF kernel", "RandomForest", "Logistic"]
# model = [GaussianNB(), DTC(), SVC(gamma=0.001)
# , RFC(n_estimators=50), LR(C=0.1, solver="lbfgs")]
model = [GaussianNB(), DTC(), SVC(gamma=0.001)
, RFC(n_estimators=50), LR(C=0.1, solver="liblinear")]
cv = ShuffleSplit(n_splits=10, test_size=0.2, random_state=0)
# n_splits:
# 划分数据集的份数,类似于KFlod的折数,默认为10份
# test_size:
# 测试集所占总样本的比例,如test_size=0.2即将划分后的数据集中20%作为测试集
# random_state:
# 随机数种子,使每次划分的数据集不变
# train_sizes: 随着训练集的增大,选择在10%,25%,50%,75%,100%的训练集大小上进行采样。
# 比如(CV= 5)10%的意思是先在训练集上选取10%的数据进行五折交叉验证。
# train_sizes:数组类,形状(n_ticks),dtype float或int
# 训练示例的相对或绝对数量,将用于生成学习曲线。如果dtype为float,则视为训练集最大尺寸的一部分
# (由所选的验证方法确定),即,它必须在(0,1]之内,否则将被解释为绝对大小注意,为了进行分类,
# 样本的数量通常必须足够大,以包含每个类中的至少一个样本(默认值:np.linspace(0.1,1.0,5))
# 输出:
# train_sizes_abs:
# 返回生成的训练的样本数,如[ 10 , 100 , 1000 ]
# train_scores:
# 返回训练集分数,该矩阵为( len ( train_sizes_abs ) , cv分割数 )维的分数,
# 每行数据代表该样本数对应不同折的分数
# test_scores:
# 同train_scores,只不过是这个对应的是测试集分数
fig, axes = plt.subplots(1, 5, figsize=(30, 6))
for ind, title_, estimator in zip(range(len(title)), title, model):
times = time()
plot_learning_curve(estimator, title_, X, y,
ax=axes[ind], ylim=[0.7, 1.05], n_jobs=4, cv=5)
print("{}:{}".format(title_, datetime.datetime.fromtimestamp(time() - times).strftime("%M:%S:%f")))
plt.show()
6、ShuffleSplit()
ShuffleSplit() 随机排列交叉验证,生成一个用户给定数量的独立的训练/测试数据划分。样例首先被打散然后划分为一对训练测试集合。
- n_splits:划分训练集、测试集的次数,默认为10
- test_size: 测试集比例或样本数量
- random_state:随机种子值,默认为None,可以通过设定明确的random_state,使得伪随机生成器的结果可以重复
from sklearn.model_selection import ShuffleSplit
import numpy as np
X = np.arange(10)
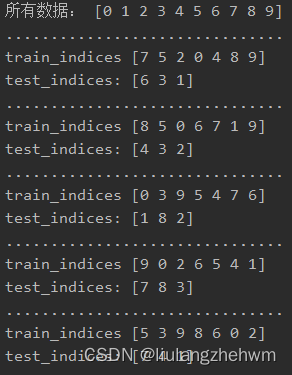
print("所有数据:", X)
ss = ShuffleSplit(n_splits=5, test_size=0.25)
n_fold = 1
for train_indices, test_indices in ss.split(X):
print('...............................')
print("train_indices", train_indices)
print("test_indices:", test_indices)