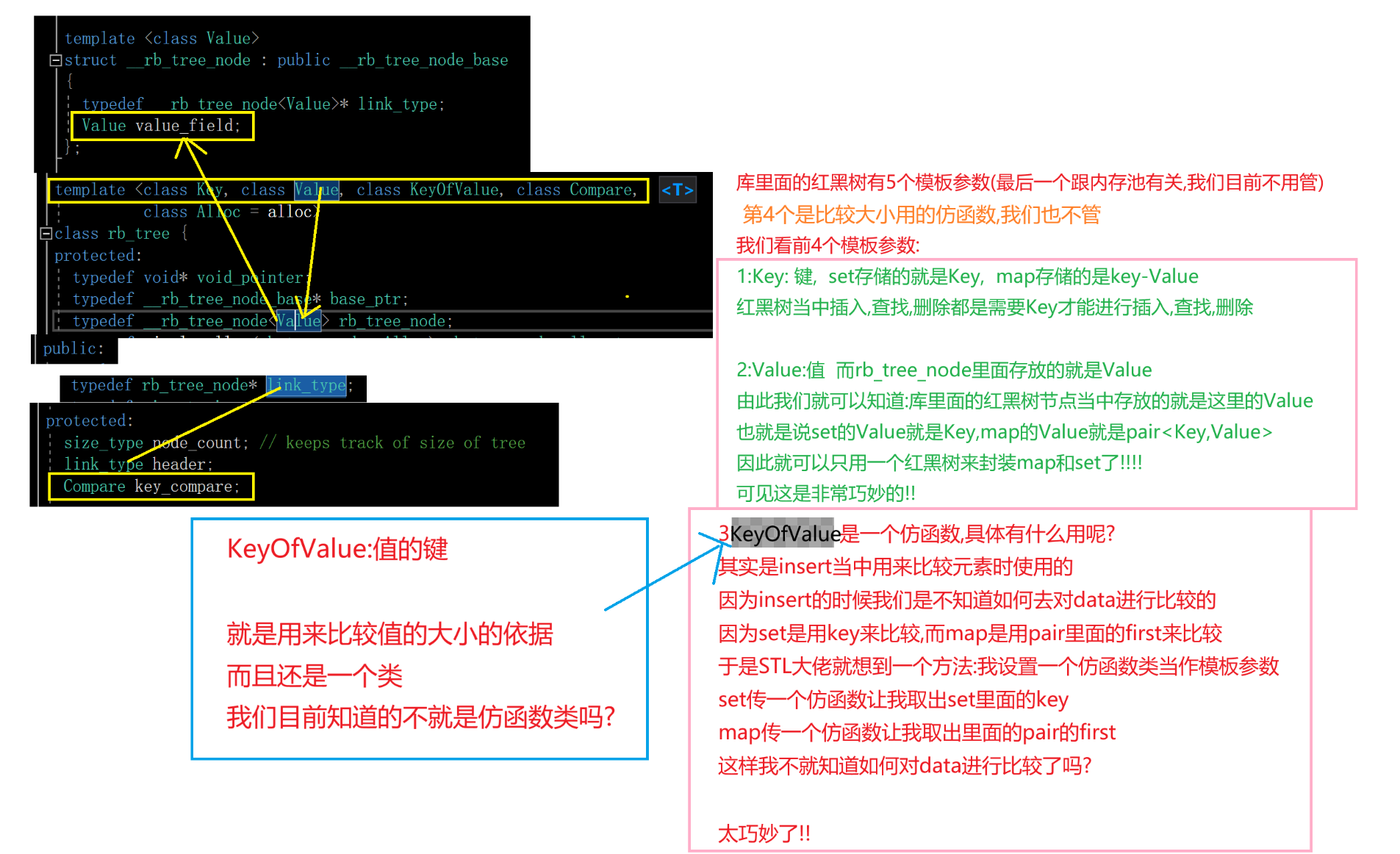
要使用Python进行网页爬虫,你需要使用一些特定的库,比如requests来发送HTTP请求,以及BeautifulSoup或lxml来解析HTML。以下是一个基本的爬虫示例:
首先,你需要安装必要的库。你可以使用pip进行安装:
bash复制代码
pip install requests beautifulsoup4 |
然后,你可以使用以下代码进行基本的网页爬取:
python复制代码
import requests |
|
from bs4 import BeautifulSoup |
|
# 定义要爬取的网页URL |
|
url = 'http://example.com' |
|
# 使用requests库发送GET请求 |
|
response = requests.get(url) |
|
# 确保请求成功 |
|
if response.status_code == 200: |
|
# 使用BeautifulSoup解析HTML |
|
soup = BeautifulSoup(response.text, 'html.parser') |
|
# 查找你感兴趣的元素,例如所有的段落元素 |
|
paragraphs = soup.find_all('p') |
|
# 打印出所有段落的内容 |
|
for p in paragraphs: |
|
print(p.get_text()) |
|
else: |
|
print('Failed to retrieve the webpage') |
这只是一个基本的示例,实际的爬虫可能会更复杂。例如,你可能需要处理相对链接、JavaScript动态加载的内容、登录验证、反爬虫策略等问题。
另外,记住在编写爬虫时要遵守网站的robots.txt文件以及相关的法律法规,不要过度请求网站,以免对网站的正常运行造成影响。
最后,请注意,爬虫的使用应当遵循道德和法律规定,不应侵犯他人的隐私或版权。在爬取任何数据之前,请确保你有权限这样做,并了解可能产生的后果。