- python 爬虫
- Python 爬虫是一种自动化的方法,用于从互联网上收集信息。常用的Python爬虫库有:
- Requests :用于发送网络请求,获取网页数据。
- BeautifulSoup :解析HTML和XML文档,从中提取数据。
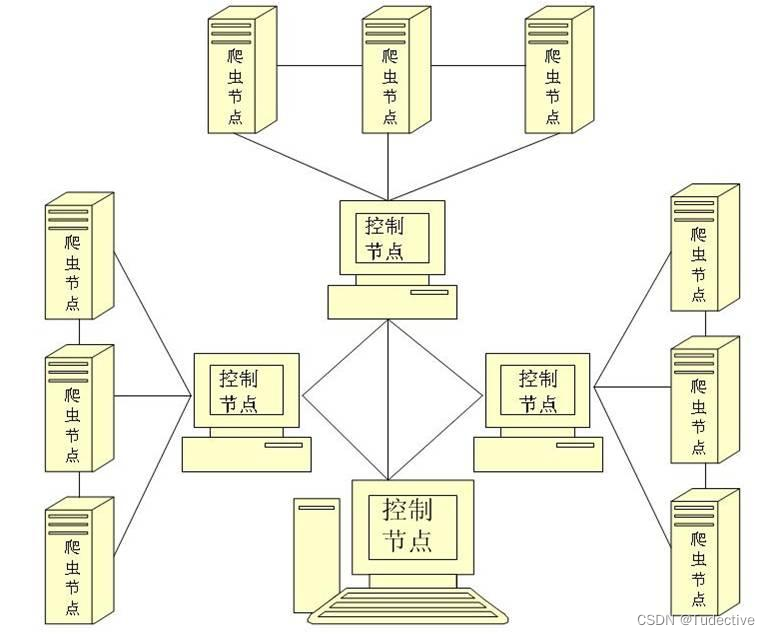
- Scrapy :一个强大的爬虫框架,适用于大规模的数据抓取。
- Selenium :用于模拟浏览器操作,可以处理JavaScript渲染的网页。
- Lxml :解析HTML和XML的库,速度快,解析能力强。
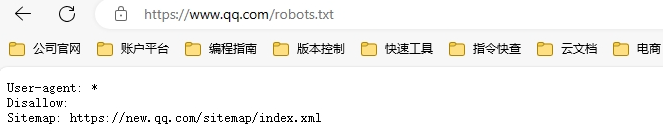
Python 爬虫的基本流程包括:发送HTTP请求、接收响应内容、解析内容并提取所需数据、存储数据。在开发爬虫时,需要注意遵守网站的robots.txt协议,尊重版权和隐私,合理控制访问频率以避免给网站服务器带来过大压力。
- BeautifulSoup
- BeautifulSoup 是一个用于解析HTML和XML文档的Python库,它创建了一个解析树,以便于提取其中的数据。它非常适合进行网页抓取。主要特点包括:
- 简单易用 :提供简单的方法来导航、搜索和修改解析树。
- 灵活 :能够解析不规范的HTML代码,并能与多种解析器(如 lxml 和 html5lib)一起使用。
- 强大 :支持复杂的选择器和正则表达式,