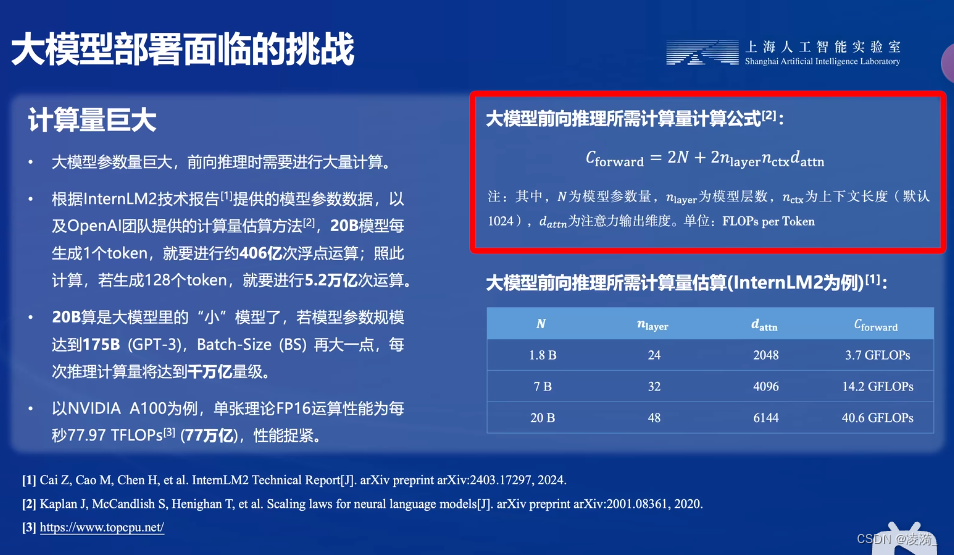
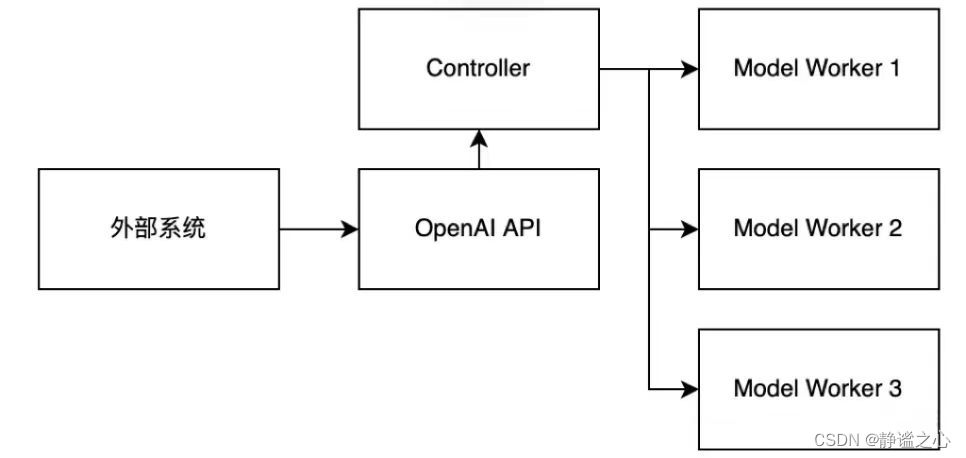
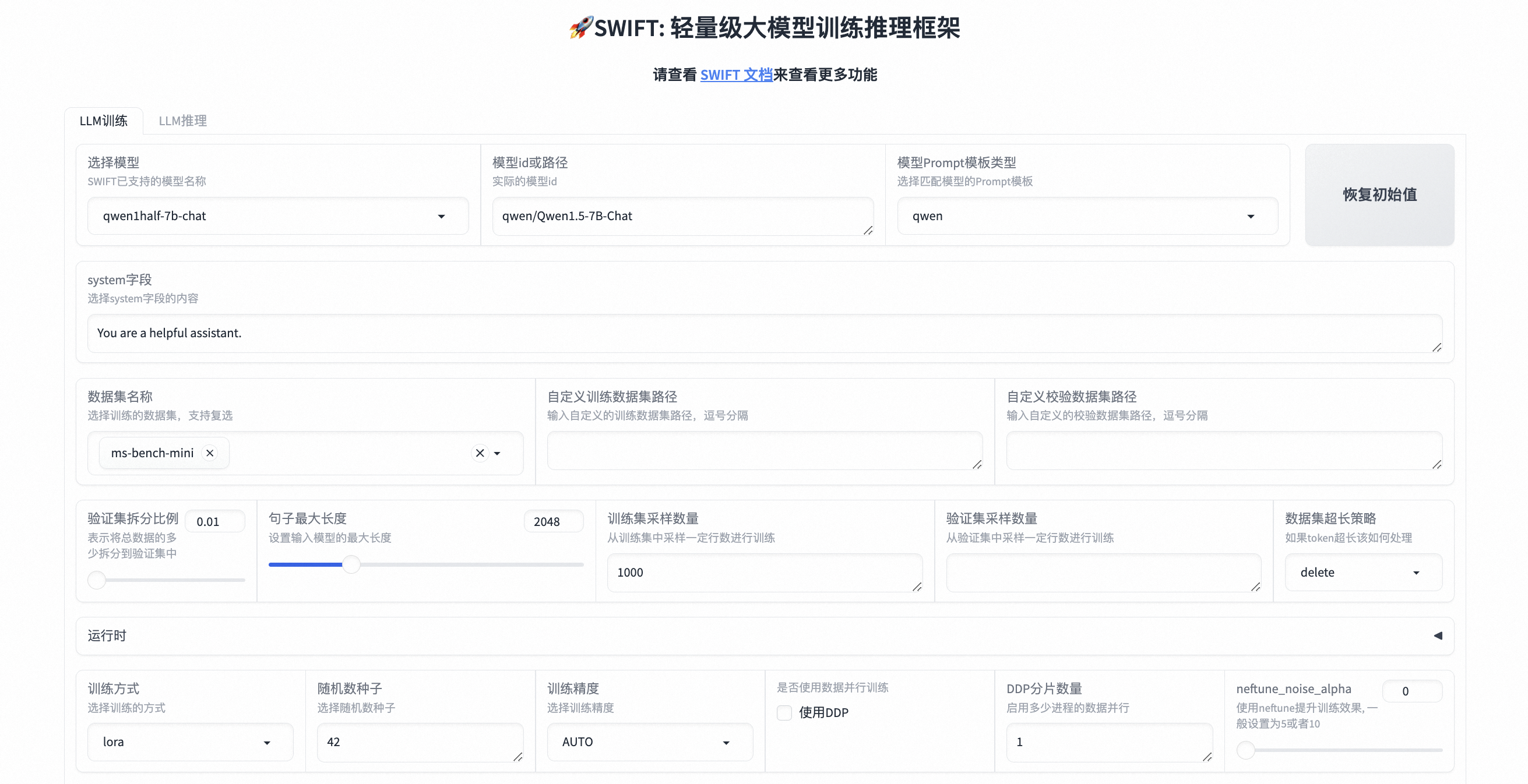
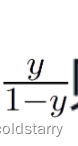针对大模型推理速度慢的问题,vLLM针对一些大模型进行优化适配,可以有效提高推理速度,体量越大的模型,提高的效果越好。
vLLM适配支持的大模型:
vLLM安装部署
vllm有两种安装方式:基于CUDA 12.1安装;源码安装。为了方便快捷,本文选择前者,并部署到容器内。
Dockerfile
FROM nvidia/cuda:12.1.0-devel-ubuntu22.04 WORKDIR /temp ENV DEBIAN_FRONTEND=noninteractive # 安装基础包 RUN apt update && \ apt install -y \ wget build-essential zlib1g-dev libncurses5-dev libgdbm-dev libnss3-dev libssl-dev \ libreadline-dev libffi-dev libsqlite3-dev libbz2-dev liblzma-dev libgl1 libglib2.0-0 git && \ apt clean && \ rm -rf /var/lib/apt/lists/* # 下载python & 编译&安装python RUN wget https://www.python.org/ftp/python/3.9.10/Python-3.9.10.tgz && \ tar -xvf Python-3.9.10.tgz && \ cd Python-3.9.10 && \ ./configure --enable-optimizations && \ make && \ make install WORKDIR /workspace RUN rm -r /temp && \ ln -s /usr/local/bin/python3 /usr/local/bin/python && \ ln -s /usr/local/bin/pip3 /usr/local/bin/pip WORKDIR /usr/src/Qwen1.5-14B-Chat-AWQ COPY requirements.txt ./ RUN pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade pip && \ pip install -i https://pypi.tuna.tsinghua.edu.cn/simple vllm && \ pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --no-cache-dir -r requirements.txt COPY . . CMD ["python", "/usr/src/Qwen1.5-14B-Chat-AWQ/app_vllm.py", "--model", "/home/models/Qwen1.5-14B-Chat-AWQ", "--trust-remote-code", "--max-model-len", "12000", "--gpu-memory-utilization", "0.9"] |
requirements.txt
transformers==4.32.0 accelerate tiktoken einops transformers_stream_generator==0.0.4 scipy gradio modelscope optimum auto-gptq |
# 创建cuda:12.1.0基础开发容器:
docker build -f ./Dockerfile -t vllm .
# 查看vllm容器id
docker ps | grep vllm
# 进入vllm容器并安装vllm
docker exec -ti vllmID /bin/bash
pip install vllm
# 保存当前vllm容器镜像
docker commit vllmID vllm:v1.0
app_vllm.py中可以参考vllm官方文档用例,写一些基础demo调试验证vllm容器环境是否OK
vLLM并发推理实践
官方用例中的LLM类不是多线程安全的,并发调用推理,会有问题。
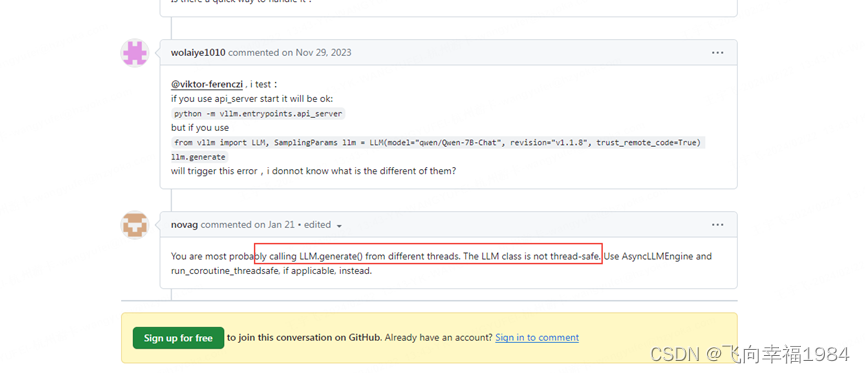
要使用AsyncLLMEngine类来实现并发推理场景,具体可参考官方的api_server
https://github.com/vllm-project/vllm/blob/main/vllm/entrypoints/api_server.py
sampling_params = SamplingParams(temperature=temperature, top_p=generation_config.top_p) text_outputs = [output.text for output in final_output.outputs] |
另外:vllm目前是没有针对chat场景的输入封装的,要开发者自己去处理输入,针对不同模型进行封装的。如:qwen的输入封装参考
vLLM 部署 Qwen_使用vllm部署qwen int4-CSDN博客
vLLM优化效果比对
qwen14b |
qwen14b-vllm |
qwen7b |
qwen7b-vllm |
qwen1.5-14b-vllm |
|
单发响应 |
973 ms |
356ms |
406 ms |
402ms |
398ms |
10 并发 |
最长 38 s |
最长1.155s |
最长1.368 s |
最长1.037s |
最长1.299s |
20并发 |
最长 77 s |
最长2.201s |
最长2.022s |
最长2.673s |
|
100 并发 |
最长385 s |
最长11.016秒 |
最长12.51 s |
最长9.4s |
最长12.396s |
- qwen7b略有提速。
- qwen14b的并发场景优化效果高达30+倍,还是很明显的提速。
- 这里qwen14b是不在支持列表的,所以,输出会有些问题;qwen7b-vllm和qwen1.5-14b-vllm的输出暂未发现问题。
- 综上,不难发现,针对大模型的推理优化,模型体量越大,优化效果越明显。
- vLLM技术还很新,可能有各种小问题,但是从实测效果看,提速显著,未来可期。
魔塔下载模型
1)安装魔搭:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple modelscope
2)下载模型
from modelscope.hub.snapshot_download import snapshot_download
model_dir = snapshot_download('qwen/Qwen1.5-14B-Chat-AWQ', cache_dir='autodl-tmp', revision='master', ignore_file_pattern='.bin')
执行命令,注意使用参数 ignore_file_pattern 避免下载 bin 文件。
如何在ModelScope社区魔搭下载所需的模型_如何 快速 下载 摩搭上的模型-CSDN博客