对于深度学习模型来说,模型部署指让训练好的模型在特定环境中运行的过程。相比于软件部署,模型部署会面临更多的难题:
- 运行模型所需的环境难以配置。深度学习模型通常是由一些框架编写,比如 PyTorch、TensorFlow。由于框架规模、依赖环境的限制,这些框架不适合在手机、开发板等生产环境中安装。深度学习模型的结构通常比较庞大,需要大量的算力才能满足实时运行的需求。模型的运行效率需要优化。
为了让模型最终能够部署到某一环境上,开发者们可以使用
任意一种深度学习框架来定义网络结构,并通过训练确定网络中的参数。之后,模型的结构和参数会被转换成一种只描述网络结构的中间表示,一些针对网络结构的优化会在中间表示上进行。最后,用面向硬件的高性能编程框架(如 CUDA,OpenCL)编写,能高效执行深度学习网络中算子的推理引擎会把中间表示转换成特定的文件格式,并在对应硬件平台上高效运行模型。这一条流水线解决了模型部署中的两大问题:使用对接深度学习框架和推理引擎的中间表示,开发者不必担心如何在新环境中运行各个复杂的框架;通过中间表示的网络结构优化和推理引擎对运算的底层优化,模型的运算效率大幅提升。专栏:模型部署那些事 - 知乎 (zhihu.com)
先从本质上来认识一下神经网络的结构。
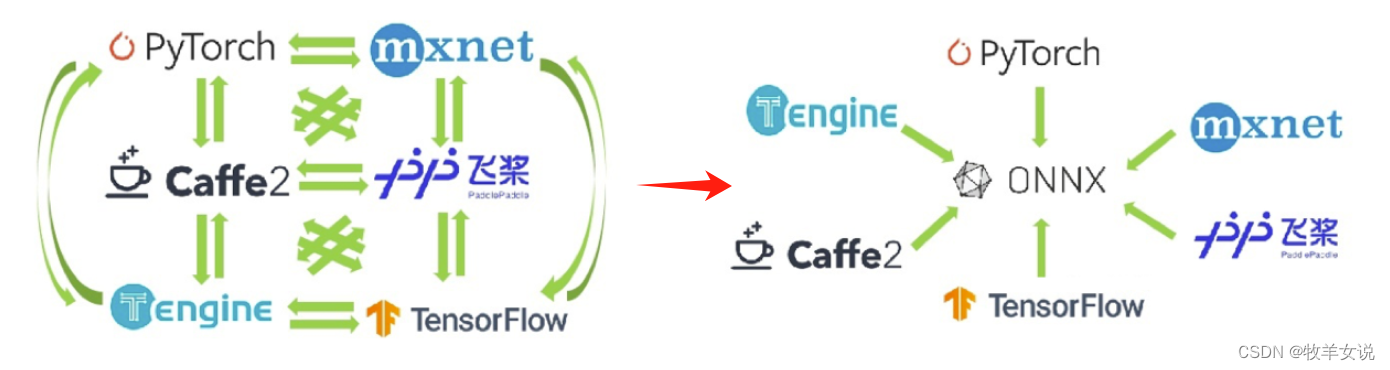
神经网络实际上只是描述了数据计算的过程,其结构可以用计算图表示。为了加速计算,一些框架会使用对神经网络“先编译,后执行”的静态图来描述网络。静态图的缺点是难以描述控制流(比如 if-else 分支语句和 for 循环语句),直接对其引入控制语句会导致产生不同的计算图。比如循环执行 n 次 a=a+b,对于不同的 n,会生成不同的计算图。ONNX (Open Neural Network Exchange)是 Facebook 和微软在2017年共同发布的,用于标准描述计算图的一种格式。目前,
在数家机构的共同维护下,ONNX 已经对接了多种深度学习框架和多种推理引擎。因此,ONNX 被当成了深度学习框架到推理引擎的桥梁,就像编译器的中间语言一样。由于各框架兼容性不一,我们通常只用 ONNX 表示更容易部署的静态图。其中,torch.onnx.export 是 PyTorch 自带的把模型转换成 ONNX 格式的函数。让我们先看一下前三个必选参数:前三个参数分别是要转换的
模型、模型的任意一组输入、导出的 ONNX 文件的文件名。转换模型时,需要原模型和输出文件名是很容易理解的,但为什么需要为模型提供一组输入呢?- 这就涉及到 ONNX 转换的原理了。
从 PyTorch 的模型到 ONNX 的模型,本质上是一种语言上的翻译。直觉上的想法是像编译器一样彻底解析原模型的代码,记录所有控制流。但前面也讲到,我们通常只用 ONNX 记录不考虑控制流的静态图。因此,PyTorch 提供了一种叫做追踪(trace)的模型转换方法:给定一组输入,再实际执行一遍模型,即把这组输入对应的计算图记录下来,保存为 ONNX 格式。export 函数用的就是追踪导出方法,需要给任意一组输入,让模型跑起来。
- 这就涉及到 ONNX 转换的原理了。
剩下的参数中,opset_version 表示 ONNX 算子集的版本。深度学习的发展会不断诞生新算子,为了支持这些新增的算子,ONNX会经常发布新的算子集,目前已经更新15个版本。我们令 opset_version = 11,即使用第11个 ONNX 算子集,是因为 SRCNN 中的 bicubic (双三次插值)在 opset11 中才得到支持。剩下的两个参数 input_names, output_names 是输入、输出 tensor 的名称。我们可以用下面的脚本来验证一下模型文件是否正确。
import onnx onnx_model = onnx.load("yolon.onnx") try: onnx.checker.check_model(onnx_model) except Exception: print("Model incorrect") else: print("Model correct")看一看 ONNX 模型具体的结构是怎么样的。我们可以使用 Netron (开源的模型可视化工具)来可视化 ONNX 模型。把 yolon.onnx 文件从本地的文件系统拖入网站,即可看到可视化结果。点击某一个算子节点,可以看到算子的具体信息。每个算子记录了算子属性、图结构、权重三类信息。
- 算子属性信息即图中 attributes 里的信息,对于卷积来说,算子属性包括了卷积核大小(kernel_shape)、卷积步长(strides)等内容。这些算子属性最终会用来生成一个具体的算子。
- 图结构信息指算子节点在计算图中的名称、邻边的信息。根据每个算子节点的图结构信息,就能完整地复原出网络的计算图。
- 权重信息指的是网络经过训练后,算子存储的权重信息。对于卷积来说,权重信息包括卷积核的权重值和卷积后的偏差值。
ONNX Runtime 是由微软维护的一个跨平台机器学习推理加速器,也就是我们前面提到的”推理引擎“。ONNX Runtime 是直接对接 ONNX 的,即 ONNX Runtime 可以直接读取并运行 .onnx 文件, 而不需要再把 .onnx 格式的文件转换成其他格式的文件。也就是说,对于 PyTorch - ONNX - ONNX Runtime 这条部署流水线,只要在目标设备中得到 .onnx 文件,并在 ONNX Runtime 上运行模型,模型部署就算大功告成了。ONNX Runtime 提供了 Python 接口。可以添加如下代码运行模型:
import onnxruntime ort_session = onnxruntime.InferenceSession("yolon.onnx") ort_inputs = {'input': input_img} ort_output = ort_session.run(['output'], ort_inputs)[0] ort_output = np.squeeze(ort_output, 0) ort_output = np.clip(ort_output, 0, 255) ort_output = np.transpose(ort_output, [1, 2, 0]).astype(np.uint8) cv2.imwrite("face.png", ort_output)这段代码中,除去后处理操作外,和 ONNX Runtime 相关的代码只有三行。让我们简单解析一下这三行代码。onnxruntime.InferenceSession用于获取一个 ONNX Runtime 推理器,其参数是用于推理的 ONNX 模型文件。
推理器的 **run** 方法用于模型推理,其第一个参数为输出张量名的列表,第二个参数为输入值的字典。其中输入值字典的 key 为张量名,value 为 numpy 类型的张量值。输入输出张量的名称需要和torch.onnx.export 中设置的输入输出名对应。
模型部署的常见流水线是“深度学习框架-中间表示-推理引擎”。其中比较常用的一个中间表示是 ONNX。深度学习模型实际上就是一个计算图。模型部署时通常把模型转换成静态的计算图,即没有控制流(分支语句、循环语句)的计算图。PyTorch 框架自带对 ONNX 的支持,只需要构造一组随机的输入,并对模型调用 torch.onnx.export 即可完成 PyTorch 到 ONNX 的转换。推理引擎 ONNX Runtime 对 ONNX 模型有原生的支持。给定一个 .onnx 文件,只需要简单使用 ONNX Runtime 的 Python API 就可以完成模型推理。
如果模型的操作稍微复杂一点,我们可能就要为兼容模型而付出大量的功夫了。实际上,模型部署时一般会碰到以下几类困难:
- 模型的动态化。出于性能的考虑,各推理框架都默认模型的输入形状、输出形状、结构是静态的。而为了让模型的泛用性更强,部署时需要在尽可能不影响原有逻辑的前提下,让模型的输入输出或是结构动态化。
- 新算子的实现。深度学习技术日新月异,提出新算子的速度往往快于 ONNX 维护者支持的速度。为了部署最新的模型,部署工程师往往需要自己在 ONNX 和推理引擎中支持新算子。
- 中间表示与推理引擎的兼容问题。由于各推理引擎的实现不同,对 ONNX 难以形成统一的支持。为了确保模型在不同的推理引擎中有同样的运行效果,部署工程师往往得为某个推理引擎定制模型代码,这为模型部署引入了许多工作量。
super()用来调用父类(基类)的方法,init()是类的构造方法,super().init() 就是调用父类的init方法, 同样可以使用super()去调用父类的其他方法。init() 是python中的构造函数,在创建对象的时"自动调用"。定义类时可以不写init方法,系统会默认创建,如果子类B和父类A,都写了init方法,那么A的init方法就会被B覆盖。想调用A的init方法需要用super去调用。python3 直接写成 : super().init(),python2 必须写成 :super(本类名,self).init()
PyTorch 模型在导出到 ONNX 模型时,模型的输入参数的类型必须全部是 torch.Tensor。我们传入参数如果是一个整形变量。这不符合 PyTorch 转 ONNX 的规定。我们必须要修改一下原来的模型的输入。为了保证输入的所有参数都是 torch.Tensor 类型的。但是,导出 ONNX 时却报了一条 TraceWarning 的警告。这条警告说有一些量可能会追踪失败。可以发现,虽然我们把模型推理的输入设置为了两个,但 ONNX 模型还是长得和原来一模一样,只有一个叫 " input " 的输入。
这是由于我们使用了 torch.Tensor.item() 把数据从 Tensor 里取出来,**而导出 ONNX 模型时这个操作是无法被记录的,只好报了一条 TraceWarning**。模型部署中常见的几类困难有:模型的动态化;新算子的实现;框架间的兼容。PyTorch 转 ONNX,实际上就是把每一个操作转化成 ONNX 定义的某一个算子。比如对于 PyTorch 中的 Upsample 和 interpolate,在转 ONNX 后最终都会成为 ONNX 的 Resize 算子。通过修改继承自 torch.autograd.Function 的算子的 symbolic 方法,可以改变该算子映射到 ONNX 算子的行为。
ONNX 是目前模型部署中最重要的中间表示之一。学懂了 ONNX 的技术细节,就能规避大量的模型部署问题。要决定新算子映射到 ONNX 算子的方法。映射到 ONNX 的方法由一个算子的 symbolic 方法决定。symbolic 方法第一个参数必须是g,之后的参数是算子的自定义输入,和 forward 函数一样。ONNX 算子的具体定义由 g.op 实现。g.op 的每个参数都可以映射到 ONNX 中的算子属性。
TorchScript 是一种序列化和优化 PyTorch 模型的格式,在优化过程中,一个
torch.nn.Module模型会被转换成 TorchScript 的torch.jit.ScriptModule模型。现在, TorchScript 也被常当成一种中间表示使用。torch.onnx.export中需要的模型实际上是一个torch.jit.ScriptModule。而要把普通 PyTorch 模型转一个这样的 TorchScript 模型,有跟踪(trace)和记录(script)两种导出计算图的方法。如果给torch.onnx.export传入了一个普通 PyTorch 模型(torch.nn.Module),那么这个模型会默认使用跟踪的方法导出。跟踪法只能通过实际运行一遍模型的方法导出模型的静态图,即无法识别出模型中的控制流(如循环);记录法则能通过解析模型来正确记录所有的控制流。跟踪法与直接 torch.onnx.export(model, …)等价 ,记录法必须先调用 torch.jit.sciprt 。
model_trace = torch.jit.trace(model, dummy_input) model_script = torch.jit.script(model)
由于推理引擎对静态图的支持更好,通常我们在模型部署时不需要显式地把 PyTorch 模型转成 TorchScript 模型,直接把 PyTorch 模型用
torch.onnx.export跟踪导出即可。ONNX 模型的每个输入和输出张量都有一个名字。很多推理引擎在运行 ONNX 文件时,都需要以“名称-张量值”的数据对来输入数据,并根据输出张量的名称来获取输出数据。在进行跟张量有关的设置(比如添加动态维度)时,也需要知道张量的名字。在实际的部署流水线中,我们都需要设置输入和输出张量的名称,并保证 ONNX 和推理引擎中使用同一套名称。
希望模型在导出至 ONNX 时有一些不同的行为模型在直接用 PyTorch 推理时有一套逻辑,而在导出的ONNX模型中有另一套逻辑。比如,我们可以把一些后处理的逻辑放在模型里,以简化除运行模型之外的其他代码。
torch.onnx.is_in_onnx_export()可以实现这一任务,该函数仅在执行torch.onnx.export()时为真。使用
is_in_onnx_export确实能让我们方便地在代码中添加和模型部署相关的逻辑。但是,这些代码对只关心模型训练的开发者来说很不友好,突兀的部署逻辑会降低代码整体的可读性。同时,is_in_onnx_export只能在每个需要添加部署逻辑的地方都“打补丁”,难以进行统一的管理。在确保
torch.onnx.export()的调用方法无误后,PyTorch 转 ONNX 时最容易出现的问题就是算子不兼容了。这里我们会介绍如何判断某个 PyTorch 算子在 ONNX 中是否兼容,以助大家在碰到报错时能更好地把错误归类。在转换普通的torch.nn.Module模型时,PyTorch 一方面会用跟踪法执行前向推理,把遇到的算子整合成计算图;另一方面,PyTorch 还会把遇到的每个算子翻译成 ONNX 中定义的算子。在这个翻译过程中,可能会碰到以下情况:- 该算子可以一对一地翻译成一个 ONNX 算子。
- 该算子在 ONNX 中没有直接对应的算子,会翻译成一至多个 ONNX 算子。
- 该算子没有定义翻译成 ONNX 的规则,报错。
由于 PyTorch 算子是向 ONNX 对齐的,这里我们先看一下 ONNX 算子的定义情况,再看一下 PyTorch 定义的算子映射关系。
实际的部署过程中,我们都有可能会碰到一个最简单的算子缺失问题: 算子在 ATen 中已经实现了,ONNX 中也有相关算子的定义,但是相关算子映射成 ONNX 的规则没有写。在这种情况下,我们只需要为 ATen 算子补充描述映射规则的符号函数就行了。ATen 是 PyTorch 内置的 C++ 张量计算库,PyTorch 算子在底层绝大多数计算都是用 ATen 实现的。
ONNX 的
Asinh算子。这个算子在 ATen 中有实现,却缺少了映射到 ONNX 算子的符号函数。在这里,我们来尝试为它补充符号函数,并导出一个包含这个算子的 ONNX 模型。为了编写符号函数,我们需要获得asinh推理接口的输入参数定义。这时,我们要去torch/_C/_VariableFunctions.pyi和torch/nn/functional.pyi这两个文件中搜索我们刚刚得到的这个算子名。这两个文件是编译 PyTorch 时本地自动生成的文件,里面包含了 ATen 算子的 PyTorch 调用接口。通过搜索,我们可以知道asinh在文件torch/_C/_VariableFunctions.pyi中,其接口定义为:def asinh(input: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...经过这些步骤,我们确认了缺失的算子名为
asinh,它是一个有实现的 ATen 算子。我们还记下了asinh的调用接口。接下来,我们要为它补充符号函数,使它在转换成 ONNX 模型时不再报错。
符号函数,可以看成是 PyTorch 算子类的一个静态方法。在把 PyTorch 模型转换成 ONNX 模型时,各个 PyTorch 算子的符号函数会被依次调用,以完成 PyTorch 算子到 ONNX 算子的转换。符号函数的定义一般如下:
def symbolic(g: torch._C.Graph, input_0: torch._C.Value, input_1: torch._C.Value, ...):其中,
torch._C.Graph和torch._C.Value都对应 PyTorch 的 C++ 实现里的一些类。只需要知道第一个参数就固定叫g,它表示和计算图相关的内容;后面的每个参数都表示算子的输入,需要和算子的前向推理接口的输入相同。对于 ATen 算子来说,它们的前向推理接口就是上述两个.pyi文件里的函数接口。g有一个方法op。在把 PyTorch 算子转换成 ONNX 算子时,需要在符号函数中调用此方法来为最终的计算图添加一个 ONNX 算子。其定义如下:def op(name: str, input_0: torch._C.Value, input_1: torch._C.Value, ...)第一个参数是算子名称。如果该算子是普通的 ONNX 算子,只需要把它在 ONNX 官方文档里的名称填进去即可。在最简单的情况下,我们只要把 PyTorch 算子的输入用
g.op()一一对应到 ONNX 算子上即可,并把g.op()的返回值作为符号函数的返回值。在情况更复杂时,我们转换一个 PyTorch 算子可能要新建若干个 ONNX 算子。
回到
asinh算子上,来为它编写符号函数。我们先去翻阅一下 ONNX 算子文档,学习一下我们在符号函数里的映射关系g.op()里应该怎么写。Asinh的文档写道:该算子有一个输入input,一个输出output,二者的类型都为张量。现在,我们可以用代码来补充这二者的映射关系了。在刚刚导出asinh算子的代码中,我们添加以下内容:from torch.onnx.symbolic_registry import register_op def asinh_symbolic(g, input, *, out=None): return g.op("Asinh", input) register_op('asinh', asinh_symbolic, '', 9)这里的
asinh_symbolic就是asinh的符号函数。从除g以外的第二个输入参数开始,其输入参数应该严格对应它在 ATen 中的定义:def asinh(input: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...在符号函数的函数体中,
g.op("Asinh", input)则完成了 ONNX 算子的定义。其中,第一个参数"Asinh"是算子在 ONNX 中的名称。至于第二个参数input,如我们刚刚在文档里所见,这个算子只有一个输入,因此我们只要把符号函数的输入参数input对应过去就行。ONNX 的Asinh的输出和 ATen 的asinh的输出是一致的,因此我们直接把g.op()的结果返回即可。定义完符号函数后,我们要把这个符号函数和原来的 ATen 算子“绑定”起来。这里,我们要用到
register_op这个 PyTorch API 来完成绑定。如示例所示,只需要一行简单的代码即可把符号函数asinh_symbolic绑定到算子asinh上:register_op('asinh', asinh_symbolic, '', 9)register_op的第一个参数是目标 ATen 算子名,第二个是要注册的符号函数,这两个参数很好理解。第三个参数是算子的“域”,对于普通 ONNX 算子,直接填空字符串即可。第四个参数表示向哪个算子集版本注册。我们遵照 ONNX 标准,向第 9 号算子集注册。值得注意的是,这里向第 9 号算子集注册,不代表较新的算子集(第 10 号、第 11 号……)都得到了注册。import torch class Model(torch.nn.Module): def __init__(self): super().__init__() def forward(self, x): return torch.asinh(x) from torch.onnx.symbolic_registry import register_op def asinh_symbolic(g, input, *, out=None): return g.op("Asinh", input) register_op('asinh', asinh_symbolic, '', 9) model = Model() input = torch.rand(1, 3, 10, 10) torch.onnx.export(model, input, 'asinh.onnx')在完成了一份自定义算子后,我们一定要测试一下算子的正确性。一般我们要用 PyTorch 运行一遍原算子,再用推理引擎(比如 ONNX Runtime)运行一下 ONNX 算子,最后比对两次的运行结果。对于我们刚刚得到的
asinh.onnx,可以用如下代码来验证:import onnxruntime import torch import numpy as np class Model(torch.nn.Module): def __init__(self): super().__init__() def forward(self, x): return torch.asinh(x) model = Model() input = torch.rand(1, 3, 10, 10) torch_output = model(input).detach().numpy() sess = onnxruntime.InferenceSession('asinh.onnx') ort_output = sess.run(None, {'0': input.numpy()})[0] assert np.allclose(torch_output, ort_output)使用
np.allclose来保证两个结果张量的误差在一个可以允许的范围内。一切正常的话,运行这段代码后,assert所在行不会报错,程序应该没有任何输出。
对于一些比较复杂的运算,仅使用 PyTorch 原生算子是无法实现的。这个时候,就要考虑自定义一个 PyTorch 算子,再把它转换到 ONNX 中了。新增 PyTorch 算子的方法有很多,PyTorch 官方比较推荐的一种做法是添加 TorchScript 算子 。以可变形卷积(Deformable Convolution)算子为例,介绍为现有 TorchScript 算子添加 ONNX 支持的方法。
有了支持 ATen 算子的经验之后,我们可以知道为算子添加符号函数一般要经过以下几步:
- 获取原算子的前向推理接口。
- 获取目标 ONNX 算子的定义。
- 编写符号函数并绑定。
首先定义一个包含了算子的模型,为之后转换 ONNX 模型做准备。
import torch import torchvision class Model(torch.nn.Module): def __init__(self): super().__init__() self.conv1 = torch.nn.Conv2d(3, 18, 3) self.conv2 = torchvision.ops.DeformConv2d(3, 3, 3) def forward(self, x): return self.conv2(x, self.conv1(x))torchvision.ops.DeformConv2d就是 Torchvision 中的可变形卷积层。相比于普通卷积,可变形卷积的其他参数都大致相同,唯一的区别就是在推理时需要多输入一个表示偏移量的张量。然后,我们查询算子的前向推理接口。DeformConv2d层最终会调用deform_conv2d这个算子。我们可以在torchvision/csrc/ops/deform_conv2d.cpp中查到该算子的调用接口:m.def(TORCH_SELECTIVE_SCHEMA( "torchvision::deform_conv2d(Tensor input, Tensor weight, Tensor offset, ...... bool use_mask) -> Tensor"));那么接下来,根据之前的经验,我们就是要去 ONNX 官方文档中查找算子的定义了。去 ONNX 的官方算子页面搜索 “deform”,将搜不出任何内容。目前,ONNX 还没有提供可变形卷积的算子,我们要自己定义一个 ONNX 算子了。
在前面讲过,
g.op()是用来定义 ONNX 算子的函数。对于 ONNX 官方定义的算子,g.op()的第一个参数就是该算子的名称。而对于一个自定义算子,g.op()的第一个参数是一个带命名空间的算子名,比如:g.op("custom::deform_conv2d, ...)其中,"::"前面的内容就是我们的命名空间。该概念和 C++ 的命名空间类似,是为了防止命名冲突而设定的。如果在
g.op()里不加前面的命名空间,则算子会被默认成 ONNX 的官方算子。PyTorch 在运行 g.op() 时会对官方的算子做检查,如果算子名有误,或者算子的输入类型不正确, g.op() 就会报错。为了让我们随心所欲地定义新 ONNX 算子,我们必须设定一个命名空间,给算子取个名,再定义自己的算子。此处,我们只关心如何导出一个包含新 ONNX 算子节点的 onnx 文件。因此,我们可以为新算子编写如下简单的符号函数:@parse_args("v", "v", "v", "v", "v", "i", "i", "i", "i", "i", "i", "i", "i", "none") def symbolic(g, input, weight, offset, mask, bias, stride_h, stride_w, pad_h, pad_w, dil_h, dil_w, n_weight_grps, n_offset_grps, use_mask): return g.op("custom::deform_conv2d", input, offset)在这个符号函数中,我们以刚刚搜索到的算子输入参数作为符号函数的输入参数,并只用
input和offset来构造一个简单的 ONNX 算子。最令人疑惑的就是装饰器
@parse_args了。简单来说,TorchScript 算子的符号函数要求标注出每一个输入参数的类型。比如"v"表示 Torch 库里的value类型,一般用于标注张量,而"i"表示 int 类型,"f"表示 float 类型,"none"表示该参数为空。具体的类型含义可以在torch.onnx.symbolic_helper.py[https://github.com/pytorch/pytorch/blob/master/torch/onnx/symbolic_helper.py]中查看。这里输入参数中的input, weight, offset, mask, bias都是张量,所以用"v"表示。后面的其他参数同理。我们不必纠结于@parse_args的原理,根据实际情况对符号函数的参数标注类型即可。有了符号函数后,我们通过如下的方式注册符号函数:register_custom_op_symbolic("torchvision::deform_conv2d", symbolic, 9)和前面的
register_op类似,注册符号函数时,我们要输入算子名、符号函数、算子集版本。与前面不同的是,这里的算子集版本是最早生效版本,在这里设定版本 9,意味着之后的第 10 号、第 11 号……版本集都能使用这个新算子。import torch import torchvision class Model(torch.nn.Module): def __init__(self): super().__init__() self.conv1 = torch.nn.Conv2d(3, 18, 3) self.conv2 = torchvision.ops.DeformConv2d(3, 3, 3) def forward(self, x): return self.conv2(x, self.conv1(x)) from torch.onnx import register_custom_op_symbolic from torch.onnx.symbolic_helper import parse_args @parse_args("v", "v", "v", "v", "v", "i", "i", "i", "i", "i", "i", "i", "i", "none") def symbolic(g, input, weight, offset, mask, bias, stride_h, stride_w, pad_h, pad_w, dil_h, dil_w, n_weight_grps, n_offset_grps, use_mask): return g.op("custom::deform_conv2d", input, offset) register_custom_op_symbolic("torchvision::deform_conv2d", symbolic, 9) model = Model() input = torch.rand(1, 3, 10, 10) torch.onnx.export(model, input, 'dcn.onnx')
最后,我们来学习一种简单的为 PyTorch 添加 C++ 算子实现的方法,来代替较为复杂的新增 TorchScript 算子。同时,我们会用
torch.autograd.Function封装这个新算子。torch.autograd.Function能完成算子实现和算子调用的隔离。不管算子是怎么实现的,它封装后的使用体验以及 ONNX 导出方法会和原生的 PyTorch 算子一样。这是我们比较推荐的为算子添加 ONNX 支持的方法。为了应对更复杂的情况,我们来自定义一个奇怪的my_add算子。这个算子的输入张量a, b,输出2a + b的值。我们会先把它在 PyTorch 中实现,再把它导出到 ONNX 中。为 PyTorch 添加简单的 C++ 拓展还是很方便的。
对于我们定义的 my_add 算子,可以用以下的 C++ 源文件来实现。我们把该文件命名为 “my_add.cpp”:// my_add.cpp #include <torch/torch.h> torch::Tensor my_add(torch::Tensor a, torch::Tensor b) { return 2 * a + b; } PYBIND11_MODULE(my_lib, m) { m.def("my_add", my_add); }torch::Tensor就是 C++ 中 torch 的张量类型,它的加法和乘法等运算符均已重载。因此,我们可以像对普通标量一样对张量做加法和乘法。轻松地完成了算子的实现后,我们用PYBIND11_MODULE来为 C++ 函数提供 Python 调用接口。这里的my_lib是我们未来要在 Python 里导入的模块名。双引号中的my_add是 Python 调用接口的名称,这里我们对齐 C++ 函数的名称,依然用 "my_add"这个名字。之后,我们可以编写如下的 Python 代码并命名为 “setup.py”,来编译刚刚的 C++ 文件:from setuptools import setup from torch.utils import cpp_extension setup(name='my_add', ext_modules=[cpp_extension.CppExtension('my_lib', ['my_add.cpp'])], cmdclass={'build_ext': cpp_extension.BuildExtension})这段代码使用了 Python 的 setuptools 编译功能和 PyTorch 的 C++ 拓展工具函数,可以编译包含了 torch 库的 C++ 源文件。这里我们需要填写的只有模块名和模块中的源文件名。我们刚刚把模块命名为
my_lib,而源文件只有一个my_add.cpp,因此拓展模块那一行要写成ext_modules=[cpp_extension.CppExtension('my_lib', ['my_add.cpp'])],之后,像处理普通的 Python 包一样执行安装命令,我们的 C++ 代码就会自动编译了。python setup.py develop直接用 Python 接口调用 C++ 函数不太“美观”,一种比较优雅的做法是把这个调用接口封装起来。这里我们用
torch.autograd.Function来封装算子的底层调用:import torch import my_lib class MyAddFunction(torch.autograd.Function): @staticmethod def forward(ctx, a, b): return my_lib.my_add(a, b) @staticmethod def symbolic(g, a, b): two = g.op("Constant", value_t=torch.tensor([2])) a = g.op('Mul', a, two) return g.op('Add', a, b)Function类本身表示 PyTorch 的一个可导函数,只要为其定义了前向推理和反向传播的实现,我们就可以把它当成一个普通 PyTorch 函数来使用。PyTorch 会自动调度该函数,合适地执行前向和反向计算。对模型部署来说,Function类有一个很好的性质:如果它定义了symbolic静态方法,该Function在执行torch.onnx.export()时就可以根据symbolic中定义的规则转换成 ONNX 算子。这个symbolic就是前面提到的符号函数,只是它的名称必须是symbolic而已。在
forward函数中,我们用my_lib.my_add(a, b)就可以调用之前写的C++函数了。这里my_lib是库名,my_add是函数名,这两个名字是在前面C++的PYBIND11_MODULE中定义的。在
symbolic函数中,我们用g.op()定义了三个算子:常量、乘法、加法。这里乘法和加法的用法和前面提到的asinh一样,只需要根据 ONNX 算子定义规则把输入参数填入即可。而在定义常量算子时,我们要把 PyTorch 张量的值传入value_t参数中。在 ONNX 中,我们需要把新建常量当成一个算子来看待,尽管这个算子并不会以节点的形式出现在 ONNX 模型的可视化结果里。把算子封装成Function后,我们可以把my_add算子用起来了。my_add = MyAddFunction.apply class MyAdd(torch.nn.Module): def __init__(self): super().__init__() def forward(self, a, b): return my_add(a, b)在这份代码里,我们先用
my_add = MyAddFunction.apply获取了一个奇怪的变量。这个变量是用来做什么的呢?其实,apply是torch.autograd.Function的一个方法,这个方法完成了Function在前向推理或者反向传播时的调度。我们在使用Function的派生类做推理时,不应该显式地调用forward(),而应该调用其apply方法。在使用my_add算子时,我们应该忽略MyAddFunction的实现细节,而只通过my_add这个接口来访问算子。这里my_add的地位,和 PyTorch 的asinh,interpolate,conv2d等原生函数是类似的。有了访问新算子的接口后,我们**
可以进一步把算子封装成一个神经网络中的计算层。我们定义一个叫做的 MyAdd 的 torch.nn.Module,它封装了my_add,就和封装了conv2d 的 torch.nn.Conv2d 一样**。
和之前的测试流程一样,让我们用下面的代码来导出一个包含新算子的 ONNX 模型,并验证一下它是否正确。
model = MyAdd() input = torch.rand(1, 3, 10, 10) torch.onnx.export(model, (input, input), 'my_add.onnx') torch_output = model(input, input).detach().numpy() import onnxruntime import numpy as np sess = onnxruntime.InferenceSession('my_add.onnx') ort_output = sess.run(None, {'a': input.numpy(), 'b': input.numpy()})[0] assert np.allclose(torch_output, ort_output)整理一下,整个流程的 P y t h o n 代码如下 \textcolor{red}{整理一下,整个流程的 Python 代码如下} 整理一下,整个流程的Python代码如下:
import torch import my_lib class MyAddFunction(torch.autograd.Function): @staticmethod def forward(ctx, a, b): return my_lib.my_add(a, b) @staticmethod def symbolic(g, a, b): two = g.op("Constant", value_t=torch.tensor([2])) a = g.op('Mul', a, two) return g.op('Add', a, b) my_add = MyAddFunction.apply class MyAdd(torch.nn.Module): def __init__(self): super().__init__() def forward(self, a, b): return my_add(a, b) model = MyAdd() input = torch.rand(1, 3, 10, 10) torch.onnx.export(model, (input, input), 'my_add.onnx') torch_output = model(input, input).detach().numpy() import onnxruntime import numpy as np sess = onnxruntime.InferenceSession('my_add.onnx') ort_output = sess.run(None, {'a': input.numpy(), 'b': input.numpy()})[0] assert np.allclose(torch_output, ort_output)
ATen 是 PyTorch 的 C++ 张量运算库。通过查询
torch/_C/_VariableFunctions.pyi和torch/nn/functional.pyi,我们可以知道 ATen 算子的 Python 接口定义。用
register_op可以为 ATen 算子补充注册符号函数用
register_custom_op_symbolic可以为 TorchScript 算子补充注册符号函数ONNX 在底层是用 Protobuf 定义的。Protobuf,全称 Protocol Buffer,是 Google 提出的一套表示和序列化数据的机制。使用 Protobuf 时,用户需要先写一份数据定义文件,再根据这份定义文件把数据存储进一份二进制文件。可以说,数据定义文件就是数据类,二进制文件就是数据类的实例。这里给出一个 Protobuf 数据定义文件的例子:
message Person { required string name = 1; required int32 id = 2; optional string email = 3; }这段定义表示在
Person这种数据类型中,必须包含name、id这两个字段,选择性包含email字段。根据这份定义文件,用户就可以选择一种编程语言,定义一个含有成员变量name、id、email的Person类,把这个类的某个实例用 Protobuf 存储成二进制文件;反之,用户也可以用二进制文件和对应的数据定义文件,读取出一个Person类的实例。对于 ONNX ,Protobuf 的数据定义文件在其开源库,这些文件定义了神经网络中模型、节点、张量的数据类型规范;而二进制文件就是我们熟悉的“.onnx"文件,每一个 onnx 文件按照数据定义规范,存储了一个神经网络的所有相关数据。直接用 Protobuf 生成 ONNX 模型还是比较麻烦的。幸运的是,ONNX 提供了很多实用 API,我们可以在完全不了解 Protobuf 的前提下,构造和读取 ONNX 模型。
还需要先了解一下 ONNX 的结构定义规则,学习一下 ONNX 在 Protobuf 定义文件里是怎样描述一个神经网络的。神经网络本质上是一个计算图。计算图的节点是算子,边是参与运算的张量。而通过可视化 ONNX 模型,我们知道 ONNX 记录了所有算子节点的属性信息,并把参与运算的张量信息存储在算子节点的输入输出信息中。事实上,ONNX 模型的结构可以用类图大致表示如下:

如图所示,一个 ONNX 模型可以用
ModelProto类表示。ModelProto包含了版本、创建者等日志信息,还包含了存储计算图结构的graph。GraphProto类则由输入张量信息、输出张量信息、节点信息组成。张量信息ValueInfoProto类包括张量名、基本数据类型、形状。节点信息NodeProto类包含了算子名、算子输入张量名、算子输出张量名。
假如我们有一个描述
output=a*x+b的 ONNX 模型model,用print(model)可以输出以下内容:ir_version: 8 graph { node { input: "a" input: "x" output: "c" op_type: "Mul" } node { input: "c" input: "b" output: "output" op_type: "Add" } name: "linear_func" input { name: "a" type { tensor_type { elem_type: 1 shape { dim {dim_value: 10} dim {dim_value: 10} } } } } input { name: "x" type { tensor_type { elem_type: 1 shape { dim {dim_value: 10} dim {dim_value: 10} } } } } input { name: "b" type { tensor_type { elem_type: 1 shape { dim {dim_value: 10} dim {dim_value: 10} } } } } output { name: "output" type { tensor_type { elem_type: 1 shape { dim { dim_value: 10} dim { dim_value: 10} } } } } } opset_import {version: 15}对应上文中的类图,这个模型的信息由
ir_version,opset_import等全局信息和graph图信息组成。而graph包含一个乘法节点、一个加法节点、三个输入张量a, x, b以及一个输出张量output。
ONNX 模型是按以下的结构组织起来的:
ModelProto-
GraphProto-
NodeProtoValueInfoProto
现在,让我们抛开 PyTorch,尝试完全用 ONNX 的 Python API 构造一个描述线性函数
output=a*x+b的 ONNX 模型。我们将根据上面的结构,自底向上地构造这个模型。首先,我们可以用helper.make_tensor_value_info构造出一个描述张量信息的ValueInfoProto对象。如前面的类图所示,我们要传入张量名、张量的基本数据类型、张量形状这三个信息。在 ONNX 中,不管是输入张量还是输出张量,它们的表示方式都是一样的。因此,这里我们用类似的方式为三个输入a, x, b和一个输出output构造ValueInfoProto对象。如下面的代码所示:import onnx from onnx import helper from onnx import TensorProto a = helper.make_tensor_value_info('a', TensorProto.FLOAT, [10, 10]) x = helper.make_tensor_value_info('x', TensorProto.FLOAT, [10, 10]) b = helper.make_tensor_value_info('b', TensorProto.FLOAT, [10, 10]) output = helper.make_tensor_value_info('output', TensorProto.FLOAT, [10, 10])之后,我们要构造算子节点信息
NodeProto,这可以通过在helper.make_node中传入算子类型、输入算子名、输出算子名这三个信息来实现。我们这里先构造了描述c=a*x的乘法节点,再构造了output=c+b的加法节点。如下面的代码所示:mul = helper.make_node('Mul', ['a', 'x'], ['c']) add = helper.make_node('Add', ['c', 'b'], ['output'])在计算机中,图一般是用一个节点集和一个边集表示的。而
ONNX 巧妙地把边的信息保存在了节点信息里,省去了保存边集的步骤。在 ONNX 中,如果某节点的输入名和之前某节点的输出名相同,就默认这两个节点是相连的。如上面的例子所示:Mul节点定义了输出c,Add节点定义了输入c,则Mul节点和Add节点是相连的。正是因为有这种边的隐式定义规则,
所以 ONNX 对节点的输入有一定的要求:一个节点的输入,要么是整个模型的输入,要么是之前某个节点的输出。如果我们把a, x, b中的某个输入节点从计算图中拿出(这个操作会在之后的代码中介绍),或者把Mul的输出从c改成d,则最终的 ONNX 模型都是不满足标准的。一个不满足标准的 ONNX 模型可能无法被推理引擎正确识别。ONNX 提供了 APIonnx.checker.check_model来判断一个 ONNX 模型是否满足标准。
接下来,我们用
helper.make_graph来构造计算图GraphProto。helper.make_graph函数需要传入节点、图名称、输入张量信息、输出张量信息这 4 个参数。如下面的代码所示,我们把之前构造出来的NodeProto对象和ValueInfoProto对象按照顺序传入即可。graph = helper.make_graph([mul, add], 'linear_func', [a, x, b], [output])这里
make_graph的节点参数有一个要求:计算图的节点必须以拓扑序给出。拓扑序是与有向图的相关的数学概念。如果按拓扑序遍历所有节点的话,能保证每个节点的输入都能在之前节点的输出里找到(对于 ONNX 模型,我们把计算图的输入张量也看成“之前的输出”)。最后,我们用
helper.make_model把计算图GraphProto封装进模型ModelProto里,一个 ONNX 模型就构造完成了。make_model函数中还可以添加模型制作者、版本等信息,为了简单起见,我们没有添加额外的信息。如下面的代码所示:model = helper.make_model(graph)构造完模型之后,我们用下面这三行代码来检查模型正确性、把模型以文本形式输出、存储到一个 “.onnx” 文件里。这里用
onnx.checker.check_model来检查模型是否满足 ONNX 标准是必要的,因为无论模型是否满足标准,ONNX 都允许我们用onnx.save存储模型。我们肯定不希望生成一个不满足标准的模型。onnx.checker.check_model(model) print(model) onnx.save(model, 'linear_func.onnx')成功执行这些代码的话,程序会以文本格式输出模型的信息,其内容应该和我们在上一节展示的输出一样。整理一下,用 ONNX Python API 构造模型的代码如下:
import onnx from onnx import helper from onnx import TensorProto # input and output a = helper.make_tensor_value_info('a', TensorProto.FLOAT, [10, 10]) x = helper.make_tensor_value_info('x', TensorProto.FLOAT, [10, 10]) b = helper.make_tensor_value_info('b', TensorProto.FLOAT, [10, 10]) output = helper.make_tensor_value_info('output', TensorProto.FLOAT, [10, 10]) # Mul mul = helper.make_node('Mul', ['a', 'x'], ['c']) # Add add = helper.make_node('Add', ['c', 'b'], ['output']) # graph and model graph = helper.make_graph([mul, add], 'linear_func', [a, x, b], [output]) model = helper.make_model(graph) # save model onnx.checker.check_model(model) print(model) onnx.save(model, 'linear_func.onnx')可以用 ONNX Runtime 运行模型,来看看模型是否正确:
import onnxruntime import numpy as np sess = onnxruntime.InferenceSession('linear_func.onnx') a = np.random.rand(10, 10).astype(np.float32) b = np.random.rand(10, 10).astype(np.float32) x = np.random.rand(10, 10).astype(np.float32) output = sess.run(['output'], {'a': a, 'b': b, 'x': x})[0] assert np.allclose(output, a * x + b)
通过用 API 构造 ONNX 模型,我们已经彻底搞懂了 ONNX 由哪些模块组成。现在,让我们看看该如何读取现有的".onnx"文件并从中提取模型信息。首先,我们可以用下面的代码读取一个 ONNX 模型:
import onnx model = onnx.load('linear_func.onnx') print(model)传给
onnx.save的是一个ModelProto的对象。同理,用上面的onnx.load读取 ONNX 模型时,我们收获的也是一个ModelProto的对象。输出这个对象后,我们应该得到和之前完全相同的输出。接下来,我们来看看怎么把图GraphProto、节点NodeProto、张量信息ValueInfoProto读取出来:graph = model.graph node = graph.node input = graph.input output = graph.output print(node) print(input) print(output)可以分别访问模型的图、节点、张量信息。这里大家或许会有疑问:该怎样找出
graph.node,graph.input中node, input这些属性名称呢?其实,属性的名称就写在每个对象的输出里。我们以print(node)的输出为例:[input: "a" input: "x" output: "c" op_type: "Mul" , input: "c" input: "b" output: "output" op_type: "Add" ]在这段输出中,我们能看出
node其实就是一个列表,列表中的对象有属性input, output, op_type(这里input也是一个列表,它包含的两个元素都显示出来了)。当我们想知道 ONNX 模型某数据对象有哪些属性时,我们不必去翻 ONNX 文档,只需要先把数据对象输出一下,然后在输出结果找出属性名即可。读取 ONNX 模型的信息后,修改 ONNX 模型就是一件很轻松的事了。这里我们来看一个直接修改模型属性的例子:import onnx model = onnx.load('linear_func.onnx') node = model.graph.node node[1].op_type = 'Sub' onnx.checker.check_model(model) onnx.save(model, 'linear_func_2.onnx')在读入之前的
linear_func.onnx模型后,我们可以直接修改第二个节点的类型node[1].op_type,把加法变成减法。这样,我们的模型描述的是a * x - b这个线性函数。
在实际部署中,如果用深度学习框架导出的 ONNX 模型出了问题,一般要通过修改框架的代码来解决,而不会从 ONNX 入手,我们把 ONNX 模型当成一个不可修改的黑盒看待。现在,我们已经深入学习了 ONNX 的原理,可以尝试对 ONNX 模型本身进行调试了。可以巧妙利用 ONNX 提供的子模型提取功能,对 ONNX 模型进行调试。
ONNX 使用 Protobuf 定义规范和序列化模型一个 ONNX 模型主要由
ModelProto,GraphProto,NodeProto,ValueInfoProto这几个数据类的对象组成。使用onnx.helper.make_xxx,我们可以构造 ONNX 模型的数据对象。onnx.save()可以保存模型,onnx.load()可以读取模型,onnx.checker.check_model()可以检查模型是否符合规范。onnx.utils.extract_model()可以从原模型中取出部分节点,和新定义的输入、输出边构成一个新的子模型。利用子模型提取功能,我们可以输出原 ONNX 模型的中间结果,实现对 ONNX 模型的调试。精度对齐,是模型部署中重要的一个环节。在把深度学习框架模型转换成中间表示模型后,部署工程师们要做的第一件事就是精度对齐,确保模型的计算结果与之前相当。精度对齐时最常用的方法,就是使用测试集评估一遍中间表示模型,看看模型的评估指标(如准确度、相似度)是否下降。
而在 PyTorch 到 ONNX 这条部署路线上,这种精度对齐方式有一些不便:
一旦我们发现 PyTorch 模型和 ONNX 模型的评估指标有了出入,我们很难去追踪精度是在哪一个模块出了问题。这是因为 PyTorch 和 ONNX 模块总是难以对应。假设我们现在有一个由很多卷积块
convs1, convs2...组成的网络,我们想对齐 PyTorch 模型和 ONNX 模型的精度。第一步,我们想比较第一个卷积块的输出x = self.convs1(x)。模块在PyTorch 模型中的输出可以很轻松地得到,可是,这个输出究竟对应 ONNX 模型里的哪一个输出呢?在小模型里,我们或许能够通过阅读 PyTorch 模型的源码,推断出每个 ONNX 模块与 PyTorch 模块的对应关系;但是,在大模型中,我们是难以建立 PyTorch 与 ONNX 的对应关系的。为了把 PyTorch 和 ONNX 模块对应起来,我们可以使用一种储存了调试信息的自定义算子,如下图所示:

可以定义一个叫做
Debug的 ONNX 算子,它有一个属性调试名name。而由于每一个 ONNX 算子节点又自带了输出张量的名称,这样一来,ONNX 节点的输出名和调试名绑定在了一起。我们可以顺着 PyTorch 里的调试名,找到对应 ONNX 里的输出,完成 PyTorch 和 ONNX 的对应。上图的例子中,我们把第一个卷积块输出
x=self.convs1(x)接入一个带有调试名x_0的调试算子。在最后生成的 ONNX 模型中,假设调试名x_0对应的输出张量叫做a。知道了这一信息后,我们只需要先运行一遍 PyTorch 模型,记录第一个卷积块的输出;再运行一遍 ONNX 模型,用截取 ONNX 中间结果的方法,记录中间张量a的值。这样,我们就可以对齐某 PyTorch 模块和它对应的 ONNX 模块的输出了。
需要实现之前提到的 Debug 算子:
import torch class DebugOp(torch.autograd.Function): @staticmethod def forward(ctx, x, name): return x @staticmethod def symbolic(g, x, name): return g.op("my::Debug", x, name_s=name) debug_apply = DebugOp.applyDebug 算子的调用接口有两个参数:输入张量
x和调试名name。为了把这个算子“伪装”成一个普通的算子,使之能正常地参与推理、构建计算图的操作,我们还是需要正确定义对输入x进行操作的forward函数。而在表示 PyTorch 与 ONNX 映射规则的symbolic函数里,我们要定义一个带有调试名的 ONNX 算子,并把输入的name传给算子。由于 Debug 算子本身不表示任何计算,因此在forward函数中,直接把输入x返回即可。而symbolic函数定义了一个新算子my::Debug:算子有一个输入x,一个属性name。我们直接把算子调用接口里的x,name传入即可。
这里需要补充介绍算子定义函数
g.op()的一些规范。在g.op()中,算子的属性需要以 {attibute_name}_{type}=attibute_value 这样的格式传入。其中{attibute_name}为属性名,{type}指定了算子属性的数据类型。比如说我们上面的算子属性写成name_s,实际上是定义了一个字符串类型,名字叫做name的属性。除了表示字符串类型的_s外,还有表示float型的_f,表示tensor型的_t。在完成算子的定义后,我们可以通过 debug_apply = DebugOp.apply 获取算子的调用接口。这样以后就可以通过debug_apply(x, name)来使用这个算子了。来实现精度对齐工具的核心——Debugger 类。这个类包含了实现精度对齐所需的所有操作。Debugger 类有三个成员变量:
torch_value记录了运行 PyTorch 模型后每个调试张量的值。onnx_value记录了运行 ONNX 模型后每个调试张量的值。output_debug_name记录了把调试张量加入 ONNX 的输出后,每个输出张量的调试名。
Debugger 类有以下方法:
debug封装了之前编写好的debug_apply。该方法需要在原 PyTorch 模型中调用,可以为导出的 ONNX 模型添加 Debug 算子节点,同时记录 PyTorch 调试张量值。def debug(self, x, name): self.torch_value[name] = x.detach().cpu().numpy() return debug_apply(x, name)
extract_debug_model和 ONNX 的子模型提取函数的用法类似,可以把带调试节点的 ONNX 模型转化成一个可以输出调试张量的 ONNX 模型。def extract_debug_model(self, input_path, output_path): model = onnx.load(input_path) inputs = [input.name for input in model.graph.input] outputs = [] for node in model.graph.node: if node.op_type == 'Debug': # 记录调试张量名 debug_name = node.attribute[0].s.decode('ASCII') self.output_debug_name.append(debug_name) # 添加输入 output_name = node.output[0] outputs.append(output_name) # 转换 Debug 节点为 Indentity 节点 node.op_type = 'Identity' node.domain = '' del node.attribute[:] e = onnx.utils.Extractor(model) extracted = e.extract_model(inputs, outputs) onnx.save(extracted, output_path)
run_debug_model会使用 ONNX Runtime 运行模型,得到 ONNX 调试张量值。def run_debug_model(self, input, debug_model): sess = onnxruntime.InferenceSession(debug_model, providers=['CPUExecutionProvider']) onnx_outputs = sess.run(None, input) for name, value in zip(self.output_debug_name, onnx_outputs): self.onnx_value[name] = value在运行调试模型前,我们要给出模型输入、模型名这两个参数。根据这些参数,
run_debug_model会调用 ONNX Runtime 的 API,对 ONNX 模型进行推理。在得到了 ONNX 模型的输出后,我们要使用上一步得到的output_debug_name信息,填写onnx_value,把 ONNX 的中间运算结果绑定到调试名上。完成了这些步骤之后,我们就有足够的信息做精度对齐了。
print_debug_result会比较 PyTorch 和 ONNX 的调试张量值,输出比较的结果。def print_debug_result(self): for name in self.torch_value.keys(): if name in self.onnx_value: mse = np.mean(self.torch_value[name] - self.onnx_value[name])**2) print(f"{name} MSE: {mse}")
debug完成了两件事:记录 PyTorch 模型中调试张量的值、添加 Debug 节点。我们使用self.torch_value[name] = x.detach().cpu().numpy()把调试张量转成 numpy 格式并保存进torch_value词典里。之后,我们调用之前编写的debug_apply算子。在 PyTorch 模型中插入
debug方法后,我们可以得到一个包含了若干 Debug 节点的 ONNX 模型。但是,这个 ONNX 模型不是我们最终拿来执行的模型。为了得到 Debug 节点的输出(即调试张量的值),我们需要做三项处理以提取出一个可运行的调试模型:- 记录每个调试张量的调试名,为之后对齐 PyTorch、ONNX 调试张量值做准备。
- 把所有 Debug 节点的输出加入到整个模型的输出中,这样在运行模型后就能得到这些中间节点的输出了。
- 自定义的 Debug 节点在推理引擎中是没有实现的,
为了让处理后的 ONNX 模型运行起来,需要把 Debug 节点转化成可运行的 Identity (恒等)节点。
完成了这三项处理后,我们才能进行模型提取。下面,我们来看看模型提取和这几项处理是怎么实现的。首先,看一下和模型提取有关的代码:
model = onnx.load(input_path) inputs = [input.name for input in model.graph.input] outputs = [] # 获取 outputs ... # 调用提取模型 API e = onnx.utils.Extractor(model) extracted = e.extract_model(inputs, outputs) # 保存模型 onnx.save(extracted, output_path)为了获取和 Debug 节点相关的信息,我们需要遍历 ONNX 模型的所有节点,找出那些类型为
Debug的节点,并对这些节点执行操作。下面的代码实现了记录调试张量名:debug_name = node.attribute[0].s.decode('ASCII') self.output_debug_name.append(debug_name)从节点的第一个属性(即
name)中取出调试名信息,并存入output_debug_name中。节点第一个属性的值可以通过node.attribute[0]获得。由于name是属性是字符串,这里要用.s获取属性的字符串值。又由于 ONNX 是以二进制的形式保存所有数据的,这里要用.decode('ASCII')把二进制字符串转成一个文本字符串。接下来的代码用于填写新模型输出outputs:output_name = node.output[0] outputs.append(output_name)node.output[0]就是 Debug 节点的输出张量在 ONNX 里的名称。把这个名称加入新模型的输出后,只要运行新模型,就可以得到该输出张量的值了。最后这段代码用于更改 Debug 节点的类型:node.op_type = 'Identity' node.domain = '' del node.attribute[:]为了消除 ONNX 不支持的 Debug 节点,一种比较简单的方式是直接把 Debug 节点修改成不执行任何操作的
Indentity类型的节点。为了做这个转换,我们要先修改节点类型名node.op_type为Identity,再把节点的域(即命名空间)node.domain修改成空,最后删除节点的所有属性,保证节点符合 ONNX 的规范。
最后,我们同时遍历
self.torch_value和self.onnx_value这两个词典,比较同一个张量在 PyTorch 模型和 ONNX 模型里的输出。在循环体中,我们只需要使用 self.torch_value[name] 和 self.onnx_value[name] 就可以访问同一个张量在 PyTorch 里的值和在 ONNX 里的值。作为示例,这里我们可以计算二者的均方误差mse,以此为精度对齐的依据。整理一下,整个工具库的代码如下:import torch import onnx import onnxruntime import numpy as np class DebugOp(torch.autograd.Function): @staticmethod def forward(ctx, x, name): return x @staticmethod def symbolic(g, x, name): return g.op("my::Debug", x, name_s=name) debug_apply = DebugOp.apply class Debugger(): def __init__(self): super().__init__() self.torch_value = dict() self.onnx_value = dict() self.output_debug_name = [] def debug(self, x, name): self.torch_value[name] = x.detach().cpu().numpy() return debug_apply(x, name) def extract_debug_model(self, input_path, output_path): model = onnx.load(input_path) inputs = [input.name for input in model.graph.input] outputs = [] for node in model.graph.node: if node.op_type == 'Debug': debug_name = node.attribute[0].s.decode('ASCII') self.output_debug_name.append(debug_name) output_name = node.output[0] outputs.append(output_name) node.op_type = 'Identity' node.domain = '' del node.attribute[:] e = onnx.utils.Extractor(model) extracted = e.extract_model(inputs, outputs) onnx.save(extracted, output_path) def run_debug_model(self, input, debug_model): sess = onnxruntime.InferenceSession(debug_model, providers=['CPUExecutionProvider']) onnx_outputs = sess.run(None, input) for name, value in zip(self.output_debug_name, onnx_outputs): self.onnx_value[name] = value def print_debug_result(self): for name in self.torch_value.keys(): if name in self.onnx_value: mse = np.mean(self.torch_value[name] - self.onnx_value[name])**2) print(f"{name} MSE: {mse}")
现在,假设我们得到了一个这样的模型:
class Model(torch.nn.Module): def __init__(self): super().__init__() self.convs1 = torch.nn.Sequential(torch.nn.Conv2d(3, 3, 3, 1, 1), torch.nn.Conv2d(3, 3, 3, 1, 1), torch.nn.Conv2d(3, 3, 3, 1, 1)) self.convs2 = torch.nn.Sequential(torch.nn.Conv2d(3, 3, 3, 1, 1), torch.nn.Conv2d(3, 3, 3, 1, 1)) self.convs3 = torch.nn.Sequential(torch.nn.Conv2d(3, 3, 3, 1, 1), torch.nn.Conv2d(3, 3, 3, 1, 1)) self.convs4 = torch.nn.Sequential(torch.nn.Conv2d(3, 3, 3, 1, 1), torch.nn.Conv2d(3, 3, 3, 1, 1), torch.nn.Conv2d(3, 3, 3, 1, 1)) def forward(self, x): x = self.convs1(x) x = self.convs2(x) x = self.convs3(x) x = self.convs4(x) return x torch_model = Model()现在我们想对齐
convs1至convs4这每一个卷积块的输出精度,该怎么使用之前写好的精度对齐工具呢?首先,我们生成管理类Debugger的一个实例:debugger = Debugger()之后,我们要设法把 Debug 节点插入原模型:
from types import MethodType def new_forward(self, x): x = self.convs1(x) x = debugger.debug(x, 'x_0') x = self.convs2(x) x = debugger.debug(x, 'x_1') x = self.convs3(x) x = debugger.debug(x, 'x_2') x = self.convs4(x) x = debugger.debug(x, 'x_3') return x torch_model.forward = MethodType(new_forward, torch_model)我们可以为原模型新写一个
forward函数。在这个新的函数函数中,我们可以通过debugger.debug把每一个输出张量标记起来,并各取一个不重复的调试名。有了new_forward函数,我们需要使用MethodType这个 Python API 把这个函数变成模型实例torch_model的一个成员方法,确保torch_model的forward函数能够被正确替换。就可以使用 PyTorch API 导出一个带有 Debug 节点的 ONNX 模型了:dummy_input = torch.randn(1, 3, 10, 10) torch.onnx.export(torch_model, dummy_input, 'before_debug.onnx', input_names=['input'])由于
torch.onnx.export模型使用的是跟踪法,模型的forward函数会被执行一次,debugger.debug操作可以把 PyTorch 模型的调试张量输出记录在debugger.torch_value里。替换掉所有 Debug 节点,并记录每个 Debug 输出张量的 ONNX 名与调试名的对应关系:debugger.extract_debug_model('before_debug.onnx', 'after_debug.onnx')可以使用下面的代码运行这个模型:
debugger.run_debug_model({'input':dummy_input.numpy()}, 'after_debug.onnx')这样,ONNX 模型的调试张量输出会记录在
debugger.onnx_value里。可以轻轻松松地用一行代码输出精度对齐的结果:debugger.print_debug_result()
TensorRT 是由 NVIDIA 发布的深度学习框架,用于在其硬件上运行深度学习推理。TensorRT 提供量化感知训练和离线量化功能,用户可以选择 INT8 和 FP16 两种优化模式,将深度学习模型应用到不同任务的生产部署,如视频流、语音识别、推荐、欺诈检测、文本生成和自然语言处理。TensorRT 经过高度优化,可在 NVIDIA GPU 上运行, 并且可能是目前在 NVIDIA GPU 运行模型最快的推理引擎。
pytorch模型转onnx格式,编写符号函数实现torch算子接口和onnx算子的映射,新建简单算子--模型部署记录整理
2024-03-15 14:46:03 18 阅读