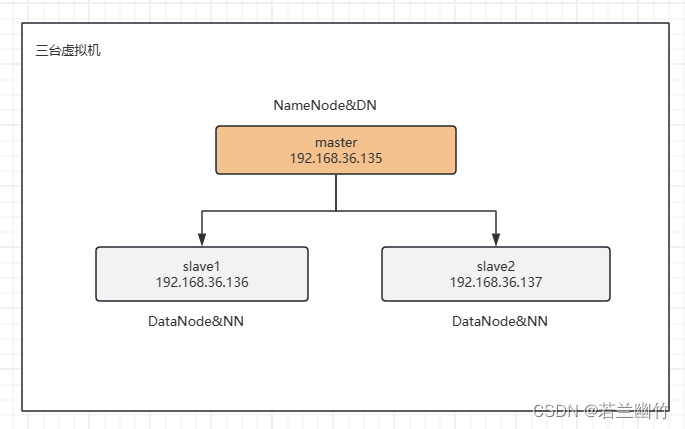
(操作系统是centos7)
1.更改主机名,设置与ip 的映射关系
hostname //查看主机名
vim /etc/hostname //将里面的主机名更改为master
vim /etc/hosts //将127.0.0.1后面的主机名更改为master,在后面加入一行IP地址与主机名之间的映射
reboot //重启服务器
2.关闭防火墙
systemctl stop firewalld //关闭防火墙
systemctl disable firewalld //禁用防火墙服务(永久关闭)
firewall-cmd --state //查看防火墙状态
3.创建/usr/data,/usr/apps,将hadoop、jdk上传至/usr/data/
(hadoop、jdk文件链接:https://pan.baidu.com/s/1wal1CSF1oO2h4dkSbceODg 提取码:4zra)
mkdir /usr/data //创建data文件
mkdir /usr/apps //创建apps文件

4.在/usr/data目录下将jdk解压到/usr/apps/
tar -zxf jdk-8u201-linux-x64.tar.gz -C /usr/apps/
5.设置jdk的环境变量
[root@master apps]# cd ./jdk1.8.0_201/
[root@master jdk1.8.0_201]# pwd
/usr/apps/jdk1.8.0_201 //拿到jdk的路径
[root@master jdk1.8.0_201]# vim 编辑/etc/profile文件
添加下列语句(赋值时不要有空格,图中有空格)
export JAVA_HOME=/usr/apps/jdk1.8.0_201
export PATH=$PATH:$JAVA_HOME/bin
保存退出。
source /etc/profile //重新加载该文件
java -version //查看jdk版本,检查环境是否设置成功
6.将Hadoop解压到apps下
tar -zxvf hadoop-2.7.1.tar.gz -C /usr/apps/ //-zxvf可以打印解压的东西7.进入Hadoop主目录下,编辑/etc/hadoop/hadoop-env.sh文件,将jdk路径导入
[root@master data]# cd /usr/apps/hadoop-2.7.1/
[root@master hadoop-2.7.1]# cd /etc/hadoop
[root@master hadoop]# vim hadoop-env.sh
8.配置4个Hadoop文件
(四个文件全部在hadoop-2.7.1/etc/hadoop/目录下,vim编辑即可 )
①core-site.xml
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 --> <property> <name>fs.defaultFS</name> <!-- 指定了客户端访问的主机名“master”,则该主机的hadoop就是namenode节点了--> <value>hdfs://master:9000</value> </property> <!-- 指定hadoop运行时产生文件的存储目录,在Hadoop目录下新建一个data目录 --> <property> <name>hadoop.tmp.dir</name> <value> /usr/apps/ hadoop-2.7.1 /data</value> </property>

②hdfs-site.xml
<!-- 指定HDFS副本的数量 --> <property> <name>dfs.replication</name> <value>1</value> </property>

③mapred-site.xml
先将mapred-site.xml.template复制到 mapred-site.xml中
再进入mapred-site.xml编辑
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml [root@master hadoop]# vim mapred-site.xml <!-- 指定mr运行在yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>

④yarn-site.xml
<!-- 指定YARN的老大(ResourceManager)的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <!-- reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>

9.进入/etc/profile,导入Hadoop的路径

(更改/etc/profile后,需重新加载,source /etc/profile)
10.格式化namenode
[root@master hadoop-2.7.1]# hadoop namenode -format
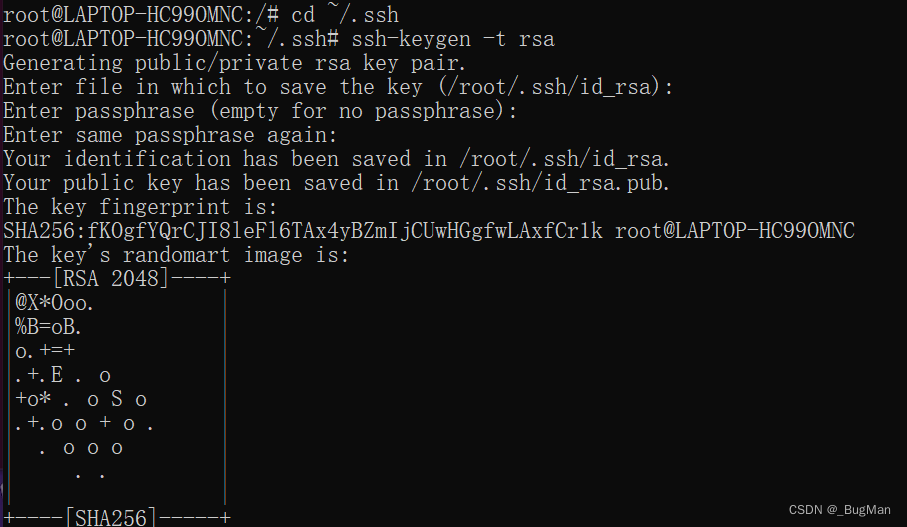
11.启动hdfs、yarn
[root@master hadoop-2.7.1]# sbin/start-dfs.sh
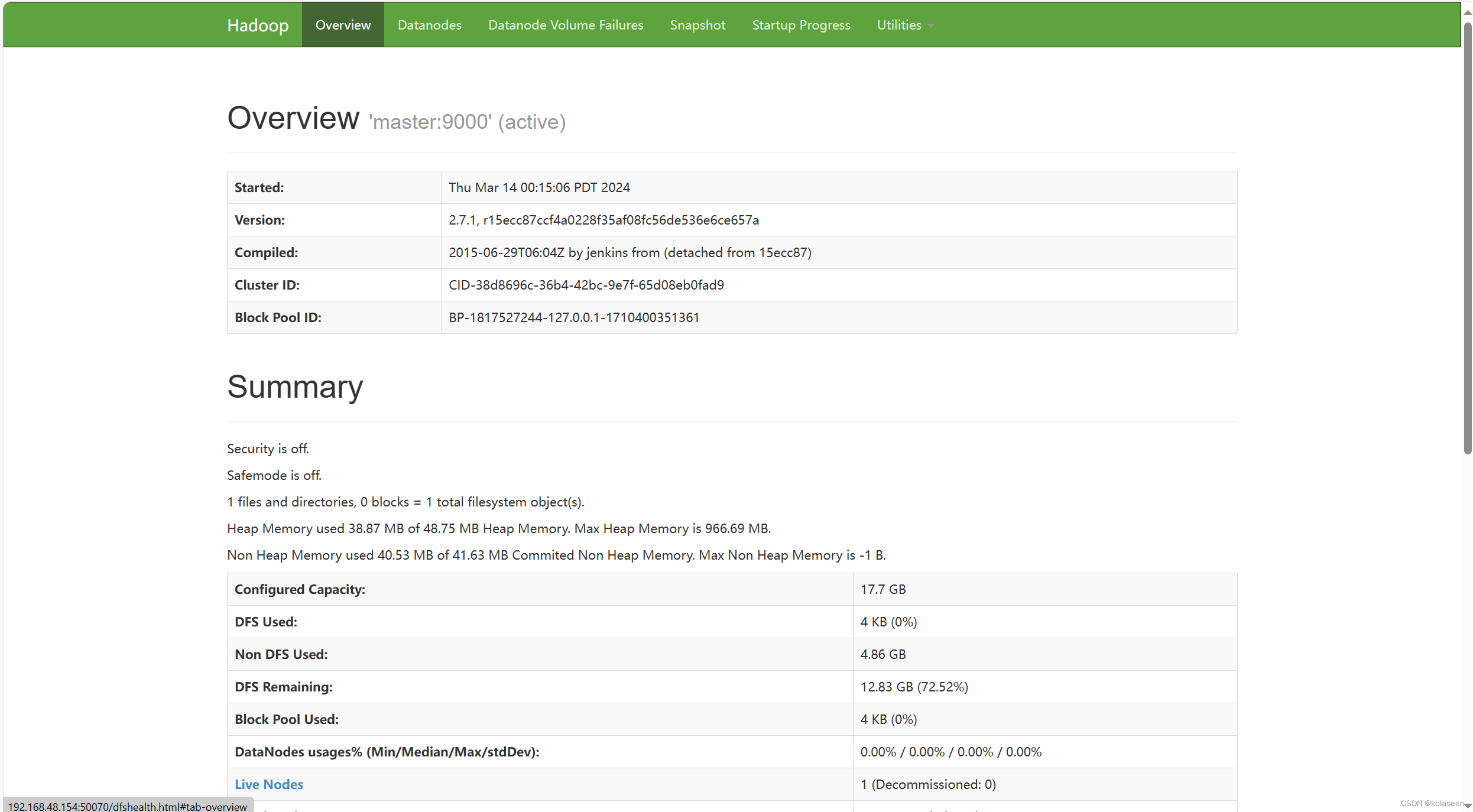
12.网页端即可访问主机ip,端口50070:






















![[论文笔记]LLaMA: Open and Efficient Foundation Language Models](https://img-blog.csdnimg.cn/img_convert/6ac0c31a03b5fcc1b636eab283af3e8e.png)