import torch
from torch import nn
"""
个代码实现了一个名为"TalkingHeadAttn"的自注意力模块(Self-Attention),主要用于增强神经网络在输入序列上的特征表示和建模。以下是这个自注意力模块的关键部分和特点:
多头自注意力:这个模块使用了多头自注意力机制,通过将输入数据进行不同方式的投影来构建多个注意力头。num_heads参数指定了注意力头的数量,每个头将学习捕捉输入序列中不同的特征关系。
查询-键-值(QKV)投影:模块使用线性变换(nn.Linear)将输入 x 投影到查询(Q),键(K),和值(V)的空间。这个投影操作是通过self.qkv完成的。注意,为了提高计算效率,一次性生成了三个部分的投影结果。
注意力计算:通过计算 Q 和 K 的点积,然后应用 Softmax 操作,得到了注意力矩阵,表示了输入序列中各个位置之间的关联程度。这个计算是通过 attn = q @ k.transpose(-2, -1) 和 attn = attn.softmax(dim=-1) 完成的。
多头特征整合:多头注意力的输出被整合在一起,通过乘以值(V)矩阵,并进行线性变换,将多个头的结果整合到一起。这个整合过程包括了投影 self.proj_l 和 self.proj_w 操作。
Dropout正则化:在注意力计算和投影操作之后,使用 Dropout 来进行正则化,减少过拟合风险。
输出:最终的输出是通过 self.proj 和 self.proj_drop 完成的。
总的来说,TalkingHeadAttn模块通过多头自注意力机制,能够同时考虑输入序列中不同位置之间的关系,以及不同的特征关系。这有助于提高模型在序列数据上的特征提取和建模能力,使其在自然语言处理和其他序列数据任务中表现出色。这个模块通常作为大型神经网络模型的子模块,用于处理序列数据。
"""
class TalkingHeadAttn(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_l = nn.Linear(num_heads, num_heads)
self.proj_w = nn.Linear(num_heads, num_heads)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0] * self.scale, qkv[1], qkv[2]
attn = q @ k.transpose(-2, -1)
attn = self.proj_l(attn.permute(0, 2, 3, 1)).permute(0, 3, 1, 2)
attn = attn.softmax(dim=-1)
attn = self.proj_w(attn.permute(0, 2, 3, 1)).permute(0, 3, 1, 2)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
if __name__ == '__main__':
block = TalkingHeadAttn(dim=128)
input = torch.rand(32, 784, 128)
output = block(input)
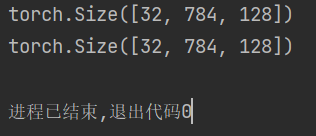
print(input.size())
print(output.size())