题目
通过自我标记进行自我监督的上下文关键字和关键词短语检索

论文地址:https://www.preprints.org/manuscript/201908.0073/v1
项目地址:https://github.com/naister/Keyword-OpenSource-Data
摘要
在本文中,我们提出了一种通过端到端深度学习方法进行关键字和关键短语检索和提取的新型自监督方法,该方法由上下文自标记语料库进行训练。我们提出的方法是新颖的,它使用上下文和语义特征来提取关键词,并且优于现有技术。通过实验证明该方法在语义和质量上均优于现有流行的关键词提取算法。此外,我们建议使用Transform的上下文特征来自动用关键字和关键短语标记短句语料库以构建基本事实。这个过程避免了人工标记关键字的时间,并且不需要任何先验知识。据我们所知,我们在本文中发布的数据集是 NLP 社区中一个良好的、独立于领域的短句语料库,其中带有标记的关键字和关键短语。
关键词是能够简洁、准确地描述文档中全部或部分主题的词[5]。关键字是一元语法,而关键短语是 N 元语法,即多个单词,例如“家庭”是一个关键字,“家庭度假”是一个关键字短语。在可理解性方面,人们更喜欢关键短语而不是关键字,因为与关键字相比,关键短语包含上下文更多的信息和含义,而关键字的上下文含义在不同的文本环境中可能会有所不同。例如,“银行”一词可能意味着银行组织,也可能意味着河岸。因此,背景是一个重要的方面。在本文中,我们通过变压器架构利用文本语料库的上下文特征,并使用它们来开发关键字提取模型。
虽然从长语料库中提取关键词和关键短语很容易,但从较短的句子中提取相同的关键词和关键短语却有点困难。有几种提出的算法可以成功地从长句子语料库中提取关键词,但是,它们对于短句子的性能相对较差。我们将在接下来的章节中讨论一些方法。在本文中,提出的方法 SCKKRS(带有自标签的自监督上下文关键字和关键短语检索)适用于长句和短句语料库,以在语义和上下文上检索关键字和关键短语。我们提出的方法在提取关键词的同时关注上下文特征,因此优于一些现有方法。
方法
关键词和关键短语提取概述关键词和关键短语检索方法大致可分为以下几种:统计方法、基于图的方法、语言学方法、机器学习方法和混合方法。在本节中,我们将讨论每种方法及其背后的概念。
统计方法在关键词和关键短语提取的统计方法中,统计特征的频率测量用于基于语言语料库选择前n个候选者。大多数统计方法都是独立于语言的,因此如果有大型语料库,它们可以应用于每种语言。Gerard Salton 和 Christopher Buckley [3] 讨论了适当的术语权重系统对于有效的信息检索系统的重要性。使用维基百科等外部资源来确定候选短语 [4] 的重要性也是另一种可能性。此外,候选关键短语之间的统计关联可以用作语义一致性的可能代理。 M.W.Berry 等人提出的快速自动关键词提取 (RAKE) [11] 是一种流行的针对单个文档的关键词提取算法,可以扩展到多个文档。 Yutaka Matsuo 和 Mitsuru Ishizuka [5] 提出了另一种统计算法,用于从单个文档中提取关键字,而不依赖于语料库和 TF-IDF 测量。在他们提出的算法中,首先确定频繁出现的术语,然后根据一些相似性度量对它们进行聚类。研究任何术语与这些簇共现的概率分布的偏差程度。如果存在偏差,则该术语很可能是关键字。然而,我们应该注意到,大多数统计方法都是基于语料库中单词的频率度量,并且算法的输出很容易出现语料库中存在的噪声单词。
基于图的方法[18]使用具有共现度量的词袋,并为每个文档提供 N 维向量,其中 N 是语料库中所有可能单词的数量。文档可以由N维向量的余弦相似度矩阵来表示。因此,当我们建立单词和文档之间的图关系时,语料库中的单词成为顶点,而边代表计算出的相似度。最后,可以选择多种中心性算法来提取顶部节点作为关键词和关键短语,例如纯度中心性、特征向量中心性[12]和Pagerank[13]。在 PageRank [13] 中,节点的重要性由代表相关性投票的相邻节点的边决定。通过考虑这些边的权重和相邻节点的排名来递归计算排名分数。同时,textrank [14] 可以应用于文本摘要和关键词提取。 Textrank 使用网络中的声望和 Pagerank 的概念对图的节点进行排名。图中前n个关键词或句子是排名最高的节点。这样,就从句子中提取了关键字列表。
语言方法利用单词的语言特征来进行关键词检测,因此语言方法是依赖于语言的。语言学方法中使用的流行算法包括 POS 模式、n-gram、NP 块等。语言学方法广泛用于领域相关语料库 [15] [16] [17]。语言学方法流行使用规则来决定关键短语的提取。例如,形容词+名词,例如线性代数,以及名词+名词,例如电脑病毒。
关键词提取的机器学习方法与其他机器学习方法一样,都是监督学习方法,需要先验知识——训练数据来学习并输出训练好的模型。训练数据是语料库及其对应的预先标记的关键词和关键短语。
混合方法结合了上述所有方法的优点。使用启发式的方法,例如位置和围绕单词的 HTML 标签属于混合方法 [23]。
数据集
现有的数据集并不适合我们,原因如下:1)它们是特定领域的,因此不能用于通用数据集; 2)它们通常是长段落,而不是短句子长度的语料库; 3)这些数据集就体积而言不够大; 4)关键词和关键短语的标记是基于频率的方法,而不是上下文相关性,因此不太接近真实情况。为了收集数据,我们使用维基百科作为来源。维基百科 [26] 是研究界流行的文本语料库来源。由于我们需要建立一个与领域无关的语料库,我们从维基百科网页中随机收集句子,以确保收集数据的通用性,这确保了语料库不属于特定领域(例如,体育、政治)。
数据清理由于维基百科文章的句子包含特殊字符和停用词,因此上一步的数据集包含大量特殊字符和停用词。因此,我们利用传统的正则表达式和现有的工具包来预处理和清理数据。

我们对句子长度段落进行关键字和关键短语标记的新颖方法使用了一种新颖的自我监督标记关键字和关键短语的方法。该方法是根据关键字与句子的上下文相关性来提取关键字。与基于频率的统计方法(严重依赖共现和术语频率来提取关键词)不同,我们提出的方法考虑了单词与句子的上下文相关性。因此,它在提取单词和短语时利用它们的语义和上下文特征。
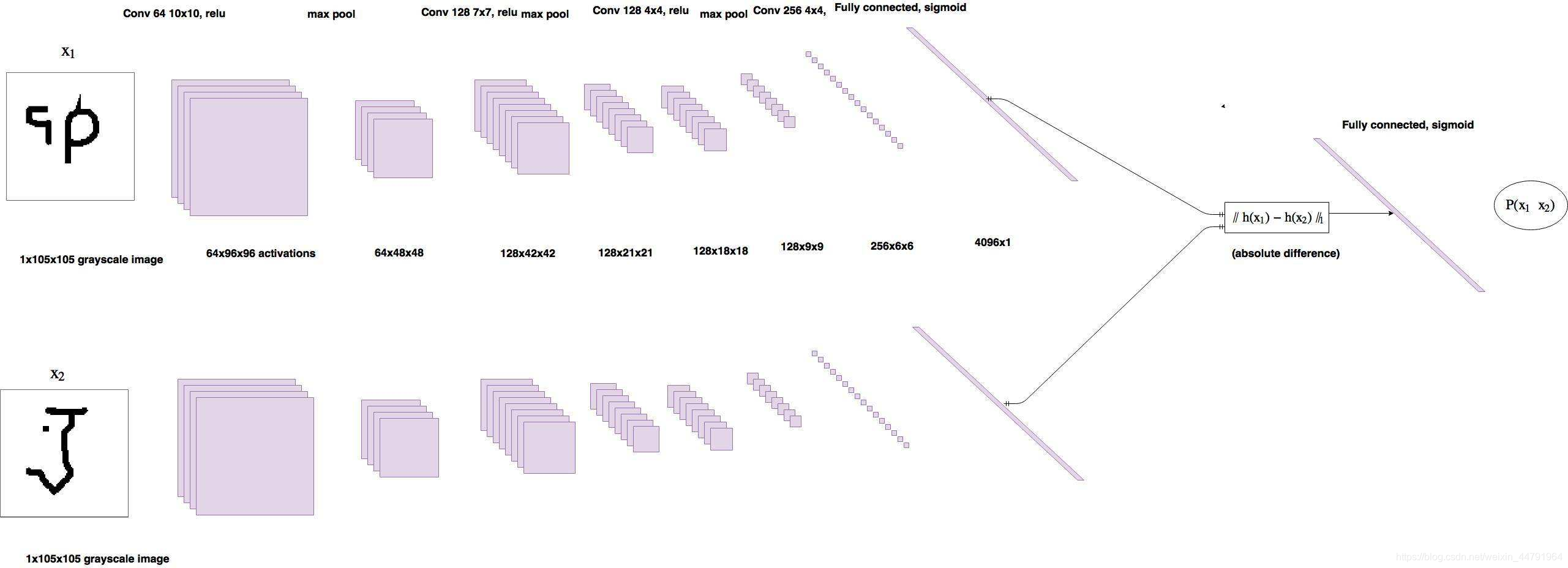
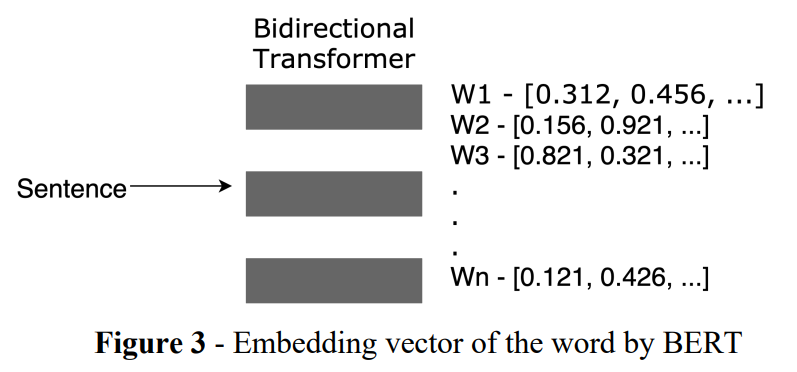
句子中单词的上下文特征是使用双向Transformers[10]提取的,它完全基于注意力机制,完全不需要递归和卷积。对两个机器翻译任务的实验表明,与序列模型相比,这些模型的质量更高。我们将句子输入 BERT,获得每个单词的上下文特征向量,如图 3 所示。对句子中单词的向量进行平均,以获得其句子嵌入向量。然后我们选择接近句子嵌入向量的单词。这个想法是关键字应该捕获句子的含义,因此应该更接近句子嵌入。嵌入与句子嵌入的相似度是使用余弦相似度度量(公式 1)获得的。
S i m i i = c o s ( w i , W ) Simi_i=cos(w_i,W) Simii=cos(wi,W)是单词𝑖 的词嵌入向量𝑤i与句子嵌入向量之间的余弦相似度。一旦提取了候选关键词,我们就可以通过相邻关键词的规则获得关键词。
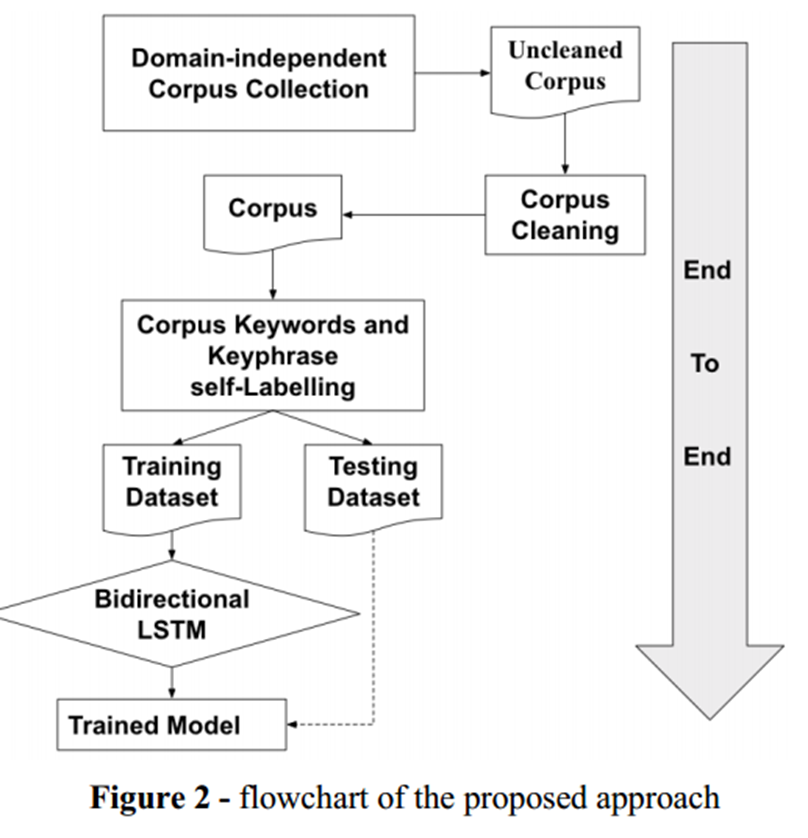
无需人工干预的自标记语料库减少了对手动构建标记良好的语料库以进行关键字和关键短语提取的主要依赖。关键词提取模型在自标记阶段之后,将标记的语料库分为训练集和验证集,然后将其输入基于深度学习的关键词提取模型。如图 2 所示,我们将关键词提取问题视为分类问题,即给定句子的上下文特征,句子中的哪些单词可以被分类为关键词的候选者。因此,将问题视为二元分类器。
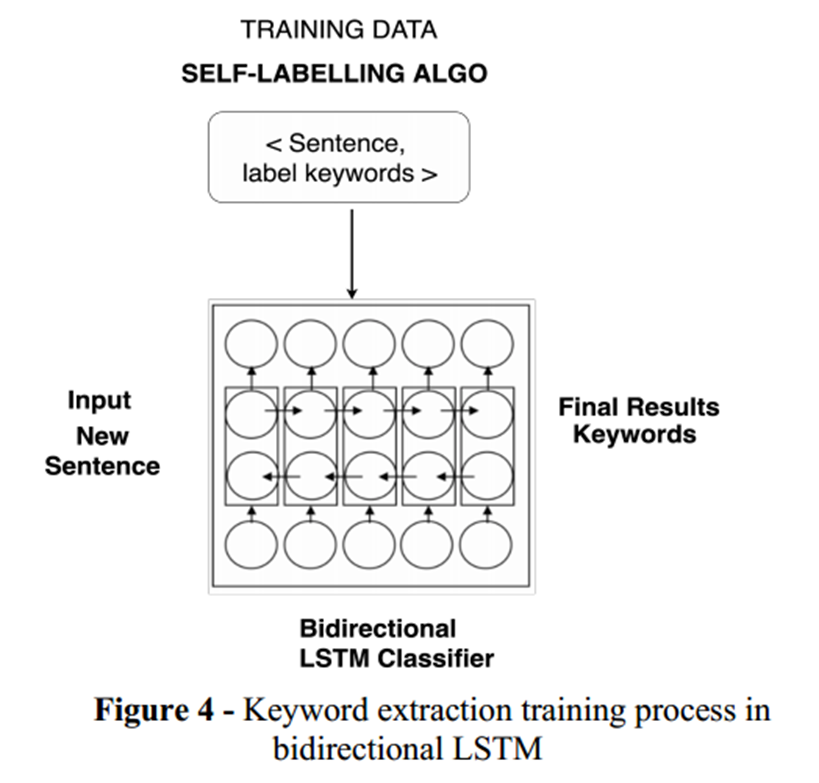
双向 LSTM [6] [7] 将句子作为序列,以及来自自标签的关键字和关键短语标签。标签是按以下方式进行one-hot编码的: 1 - 单词是关键字、0 - 单词不是关键字。然后将此 <sentence, label> 对传递给模型进行训练。采用dropout等正则化方法来避免高方差和低偏差。应该注意的是,标签是根据上下文特征提取的。我们使用图 4 来说明双向 LSTM 的训练过程。
实验
在社区中,大多数开源和公共语料库都是特定领域的,除此之外,带有标签的关键词和关键短语的语料库更是凤毛麟角。此外,它们大多数都是句子较长的语料库,有时甚至长达一个段落,因此这些困难使得它们不适合构建深度学习模型。因此,我们将部分句子长度的语料库开源给社区,可在此处获取:https://github.com/naister/Keyword-OpenSource-Data。据我们所知,这是社区中第一个带有标签关键词和关键短语的公共句子长度语料库。
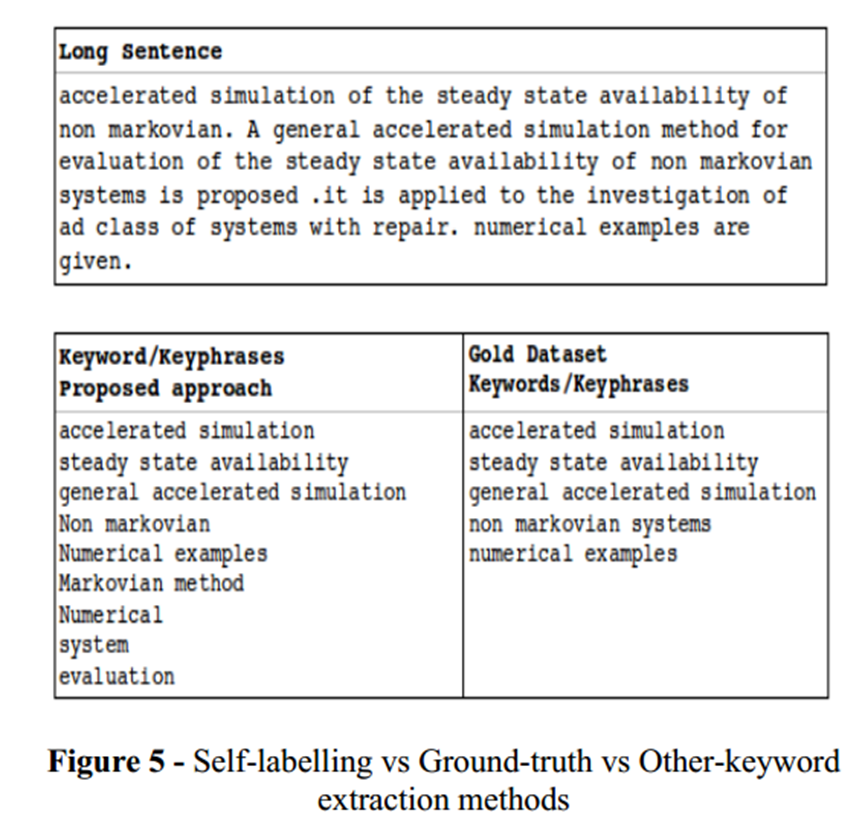
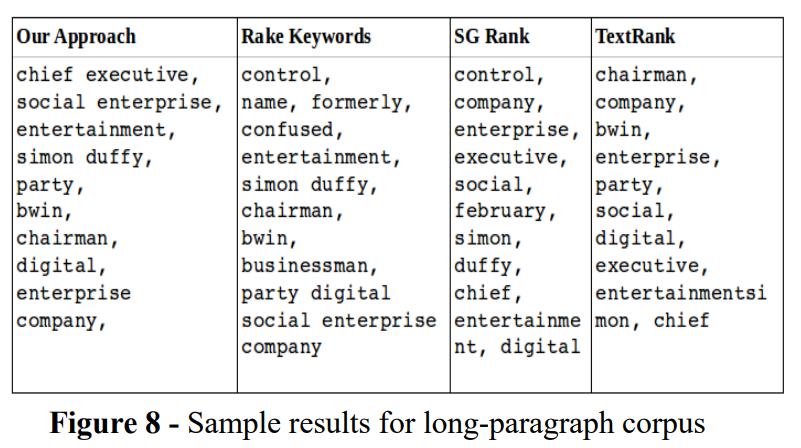
为了进行性能评估,我们使用著名的 INSPEC 数据集 [29] 和 DUC 数据集 [30] 的语料库。图 5 显示了我们提出的方法中的关键字/关键短语以及基本事实的关键字。我们可以看到我们的方法检索了所有关键词/关键短语,甚至给出了比真实情况更有用的关键词和关键短语。
结果如图 6 所示。在图 6 中,g 表示真实关键字,r 表示 RAKE 生成的关键字,t 表示 TextRank 生成的关键字,p 表示建议的自标记关键字。

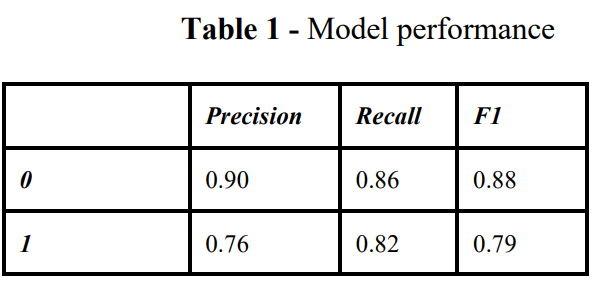
我们将自标记语料库中的训练数据输入到模型训练中并获得模型性能,即准确率、召回率、F1 分数和支持度如表 1 所示。

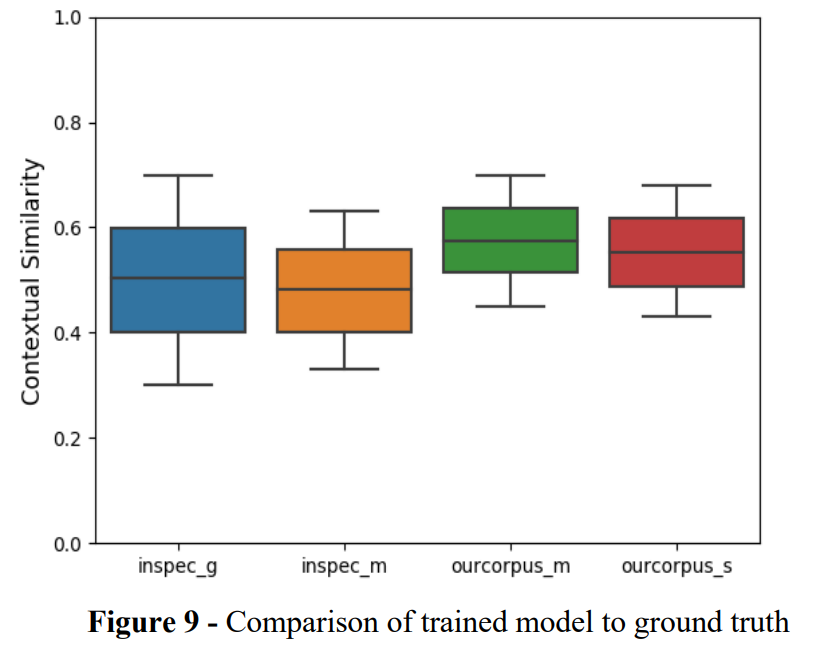
结果如图 9 所示。我们可以看到,在这两个数据集中,所提出的方法都取得了非常接近真实情况的结果,并且当我们考虑图 6 时,也获得了比其他方法更好的统计数据。我们的结果相似性也优于 INSPEC 和 DUC 的真实值,这证明了 INSPEC 和 DUC 的语义和上下文关键字提取比黄金标准更好。
在图 9 中,g 是真实值,m 表示来自我们训练模型的关键字或关键短语,s 是来自我们方法的自标记关键字或关键短语。