Siamese和Chinese有点像。Siam是古时候泰国的称呼,中文译作暹罗。Siamese也就是“暹罗”人或“泰国”人。Siamese在英语中是“孪生”、“连体”的意思,这是为什么呢?十九世纪泰国出生了一对连体婴儿,当时的医学技术无法使两人分离出来,于是两人顽强地生活了一生,1829年被英国商人发现,进入马戏团,在全世界各地表演,1839年他们访问美国北卡罗莱那州后来成为“玲玲马戏团” 的台柱,最后成为美国公民。1843年4月13日跟英国一对姐妹结婚,恩生了10个小孩,昌生了12个,姐妹吵架时,兄弟就要轮流到每个老婆家住三天。1874年恩因肺病去世,另一位不久也去世,两人均于63岁离开人间。两人的肝至今仍保存在费城的马特博物馆内。从此之后“暹罗双胞胎”(Siamesetwins)就成了连体人的代名词,也因为这对双胞胎让全世界都重视到这项特殊疾病。
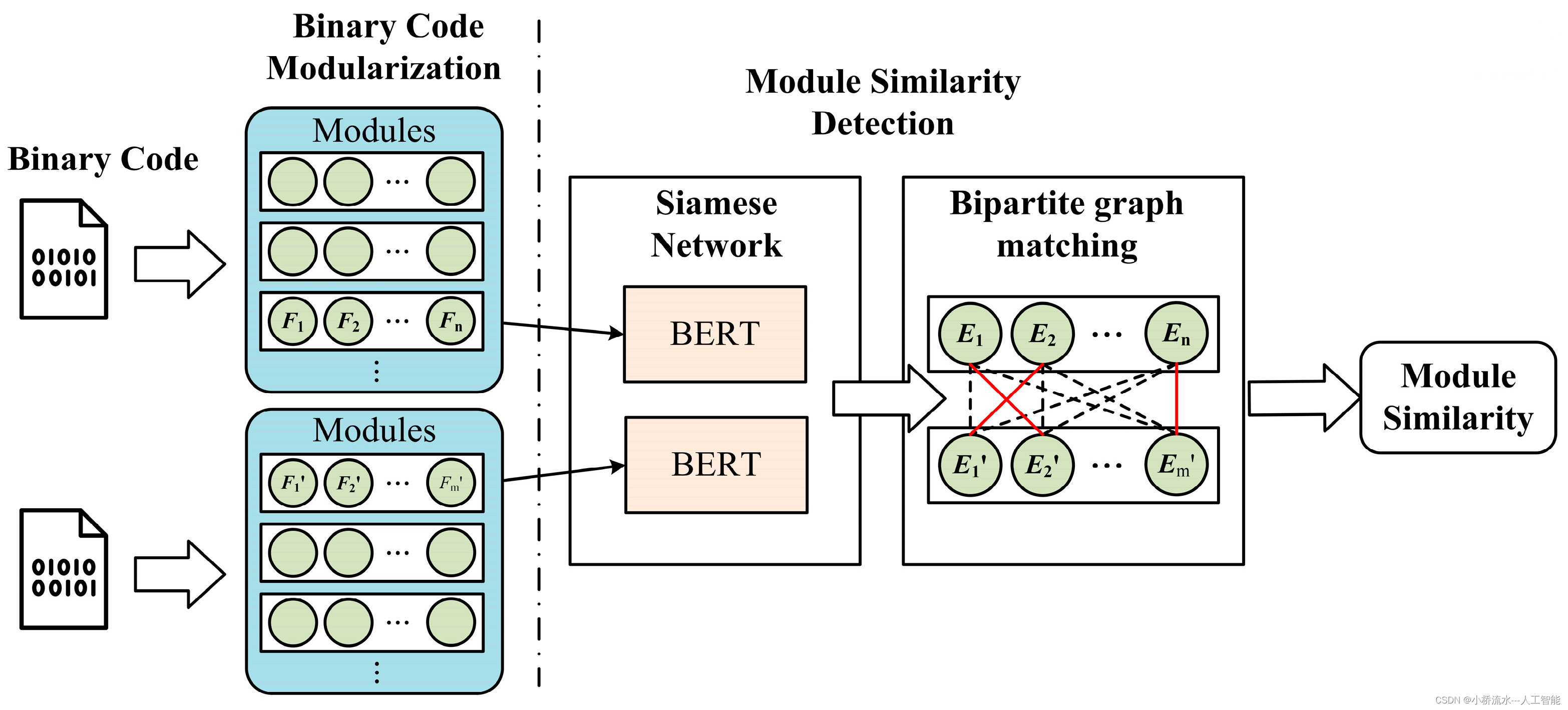
简单来说,孪生神经网络(Siamese network)就是“连体的神经网络”,神经网络的“连体”是通过共享权值来实现的。所谓权值共享就是当神经网络有两个输入的时候,这两个输入使用的神经网络的权值是共享的(可以理解为使用了同一个神经网络)。很多时候,我们需要去评判两张图片的相似性,比如比较两张人脸的相似性,我们可以很自然的想到去提取这个图片的特征再进行比较,自然而然的,我们又可以想到利用神经网络进行特征提取。
如果使用两个神经网络分别对图片进行特征提取,提取到的特征很有可能不在一个域中,此时我们可以考虑使用一个神经网络进行特征提取再进行比较。这个时候我们就可以理解孪生神经网络为什么要进行权值共享了。
孪生神经网络有两个输入(Input1 and Input2),利用神经网络将输入映射到新的空间,形成输入在新的空间中的表示。通过Loss的计算,评价两个输入的相似度。
一、背景
在人脸识别中,存在所谓的one-shot问题。举例来说,就是对公司员工进行人脸识别,每个员工只给你一张照片(训练集样本少),并且员工会离职、入职(每次变动都要重新训练模型)。有这样的问题存在,就没办法直接训练模型来解决这样的分类问题了。为了解决one-shot问题,我们会训练一个模型来输出给定两张图像的相似度,所以模型学习得到的是similarity函数。哪些模型能通过学习得到similarity函数呢?Siamese网络就是这样的一种模型。
二、问题类型
主要解决以下两类分类问题:
第一类,分类数量较少,每一类的数据量较多,比如ImageNet、VOC等。这种分类问题可以使用神经网络或者SVM解决,只要事先知道了所有的类。
第二类,分类数量较多(或者说无法确认具体数量),每一类的数据量较少,比如人脸识别、人脸验证任务。
三、解决方法
将输入映射为一个特征向量,使用两个向量之间的“距离”(L1 Norm)来表示输入之间的差异(图像语义上的差距)。据此设计了Siamese Network。每次需要输入两个样本作为一个样本对计算损失函数。
1)用的softmax只需要输入一个样本。
2)FaceNet中的Triplet Loss需要输入三个样本。
提出了Contrastive Loss用于训练。
四、网络介绍
1、主干网络
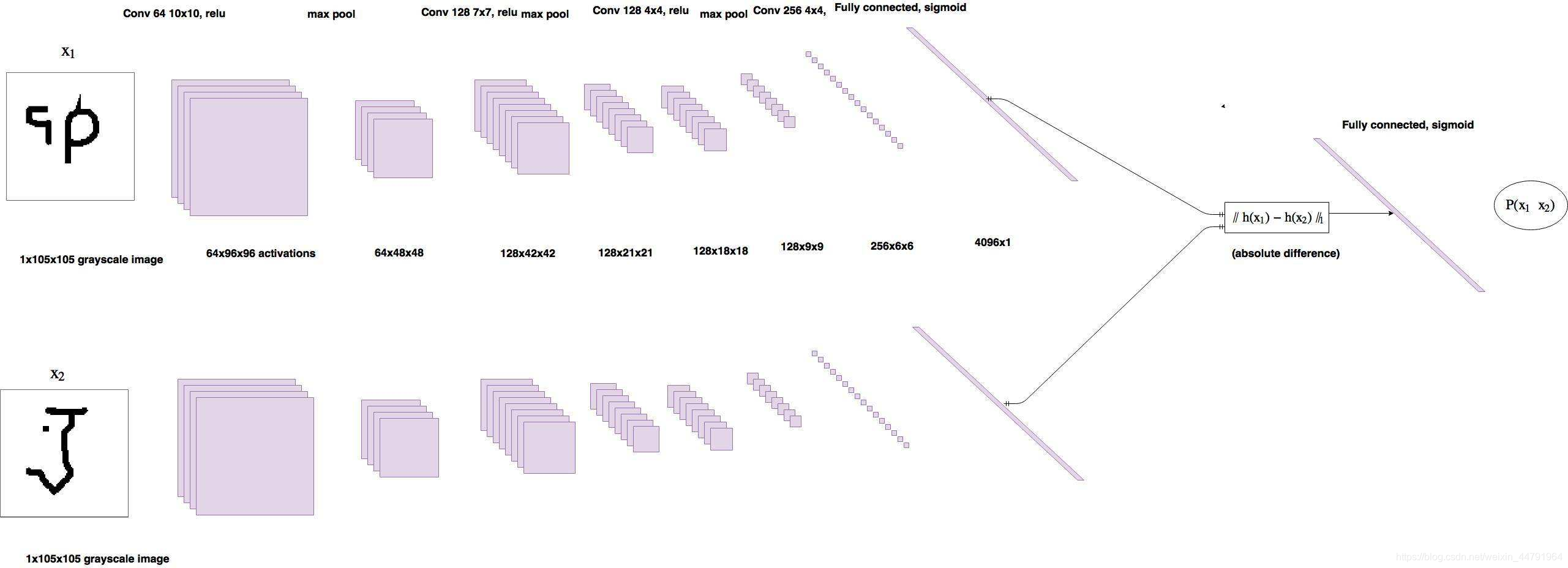
孪生神经网络的主干特征提取网络的功能是进行特征提取,各种神经网络都可以适用,eg:VGG16 ,下图能反映VGG16结构特征:

1、一张原始图片被resize到指定大小,本文使用105x105。
2、conv1包括两次[3,3]卷积网络,一次2X2最大池化,输出的特征层为64通道。
3、conv2包括两次[3,3]卷积网络,一次2X2最大池化,输出的特征层为128通道。
4、conv3包括三次[3,3]卷积网络,一次2X2最大池化,输出的特征层为256通道。
5、conv4包括三次[3,3]卷积网络,一次2X2最大池化,输出的特征层为512通道。
6、conv5包括三次[3,3]卷积网络,一次2X2最大池化,输出的特征层为512通道。
实现代码:
import keras
from keras.layers import Input,Dense,Conv2D
from keras.layers import MaxPooling2D,Flatten
from keras.models import Model
import os
import numpy as np
from PIL import Image
from keras.optimizers import SGD
class VGG16:
def __init__(self):
self.block1_conv1 = Conv2D(64,(3,3),activation = 'relu',padding = 'same',name = 'block1_conv1')
self.block1_conv2 = Conv2D(64,(3,3),activation = 'relu',padding = 'same', name = 'block1_conv2')
self.block1_pool = MaxPooling2D((2,2), strides = (2,2), name = 'block1_pool')
self.block2_conv1 = Conv2D(128,(3,3),activation = 'relu',padding = 'same',name = 'block2_conv1')
self.block2_conv2 = Conv2D(128,(3,3),activation = 'relu',padding = 'same',name = 'block2_conv2')
self.block2_pool = MaxPooling2D((2,2),strides = (2,2),name = 'block2_pool')
self.block3_conv1 = Conv2D(256,(3,3),activation = 'relu',padding = 'same',name = 'block3_conv1')
self.block3_conv2 = Conv2D(256,(3,3),activation = 'relu',padding = 'same',name = 'block3_conv2')
self.block3_conv3 = Conv2D(256,(3,3),activation = 'relu',padding = 'same',name = 'block3_conv3')
self.block3_pool = MaxPooling2D((2,2),strides = (2,2),name = 'block3_pool')
self.block4_conv1 = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block4_conv1')
self.block4_conv2 = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block4_conv2')
self.block4_conv3 = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block4_conv3')
self.block4_pool = MaxPooling2D((2,2),strides = (2,2),name = 'block4_pool')
# 第五个卷积部分
self.block5_conv1 = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block5_conv1')
self.block5_conv2 = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block5_conv2')
self.block5_conv3 = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block5_conv3')
self.block5_pool = MaxPooling2D((2,2),strides = (2,2),name = 'block5_pool')
self.flatten = Flatten(name = 'flatten')
def call(self, inputs):
x = inputs
x = self.block1_conv1(x)
x = self.block1_conv2(x)
x = self.block1_pool(x)
x = self.block2_conv1(x)
x = self.block2_conv2(x)
x = self.block2_pool(x)
x = self.block3_conv1(x)
x = self.block3_conv2(x)
x = self.block3_conv3(x)
x = self.block3_pool(x)
x = self.block4_conv1(x)
x = self.block4_conv2(x)
x = self.block4_conv3(x)
x = self.block4_pool(x)
x = self.block5_conv1(x)
x = self.block5_conv2(x)
x = self.block5_conv3(x)
x = self.block5_pool(x)
outputs = self.flatten(x)
return outputs
2、比较网络
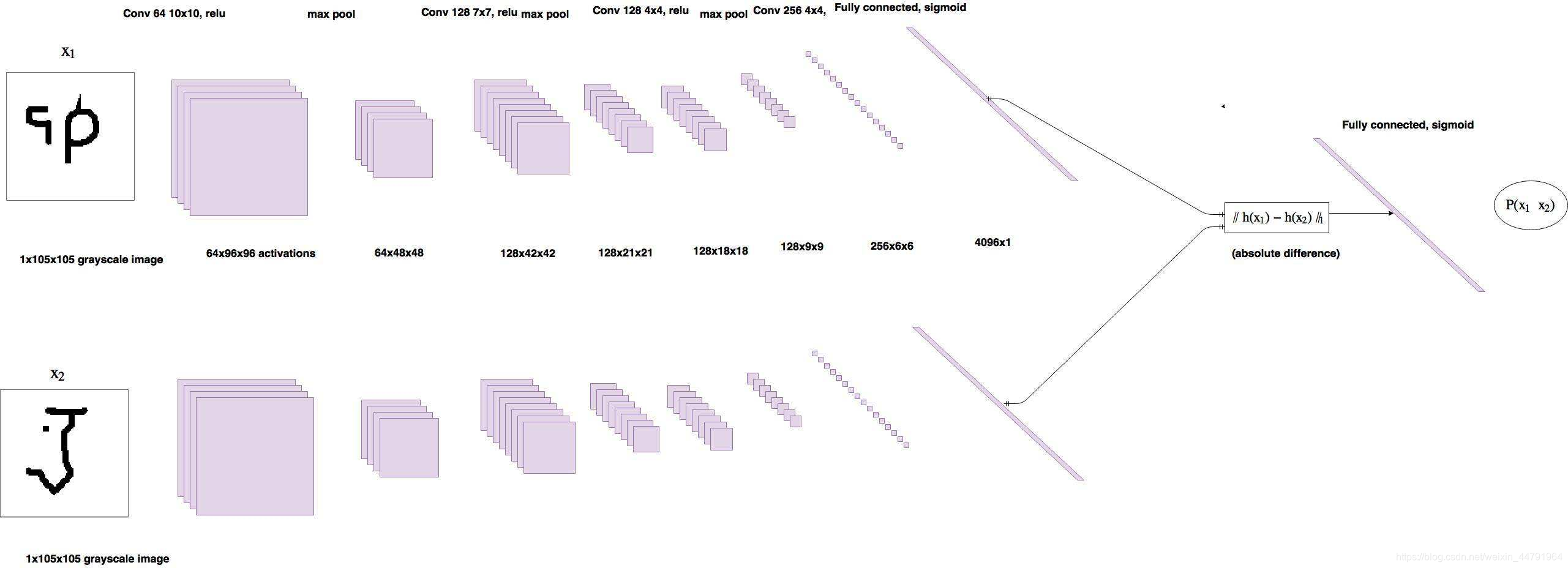
在获得主干特征提取网络之后,我们可以获取到一个多维特征,我们可以使用flatten的方式将其平铺到一维上,这个时候我们就可以获得两个输入的一维向量了,再将这两个一维向量进行相减,再进行绝对值求和,相当于求取了两个特征向量插值的L1范数。也就相当于求取了两个一维向量的距离。对这个距离再进行两次全连接,第二次全连接到一个神经元上,对这个神经元的结果取sigmoid,使其值在0-1之间,代表两个输入图片的相似程度。
实现代码如下:
import keras
from keras.layers import Input,Dense,Conv2D
from keras.layers import MaxPooling2D,Flatten,Lambda
from keras.models import Model
import keras.backend as K
import os
import numpy as np
from PIL import Image
from keras.optimizers import SGD
from nets.vgg import VGG16
def siamese(input_shape):
vgg_model = VGG16()
input_image_1 = Input(shape=input_shape)
input_image_2 = Input(shape=input_shape)
encoded_image_1 = vgg_model.call(input_image_1)
encoded_image_2 = vgg_model.call(input_image_2)
l1_distance_layer = Lambda(
lambda tensors: K.abs(tensors[0] - tensors[1]))
l1_distance = l1_distance_layer([encoded_image_1, encoded_image_2])
out = Dense(512,activation='relu')(l1_distance)
out = Dense(1,activation='sigmoid')(out)
model = Model([input_image_1,input_image_2],out)
return model
五、网络结构

六、Contrastive Loss损失函数
在孪生神经网络(siamese network)中,其采用的损失函数是contrastive loss,这种损失函数可以有效的处理孪生神经网络中的paired data的关系。contrastive loss的表达式如下:
其中![]()
代表两个样本特征和
的欧氏距离(二范数)P 表示样本的特征维数,Y 为两个样本是否匹配的标签,Y=1 代表两个样本相似或者匹配,Y=0 则代表不匹配,m 为设定的阈值,N 为样本个数。
观察上述的contrastive loss的表达式可以发现,这种损失函数可以很好的表达成对样本的匹配程度,也能够很好用于训练提取特征的模型。
①当 Y=1(即样本相似时),损失函数只剩下
![]()
即当样本不相似时,其特征空间的欧式距离反而小的话,损失值会变大,这也正好符号我们的要求。
②当 Y=0 (即样本不相似时),损失函数为
![]()
即当样本不相似时,其特征空间的欧式距离反而小的话,损失值会变大,这也正好符号我们的要求。
注意这里设置了一个阈值margin,表示我们只考虑不相似特征欧式距离在0~margin之间的,当距离超过margin的,则把其loss看做为0(即不相似的特征离的很远,其loss应该是很低的;而对于相似的特征反而离的很远,我们就需要增加其loss,从而不断更新成对样本的匹配程度)]
七、延伸
triplet loss 是深度学习的一种损失函数,主要是用于训练差异性小的样本,比如人脸等;其次在训练目标是得到样本的embedding任务中,triplet loss 也经常使用,比如文本、图片的embedding。
Siamese network是双胞胎连体,三胞胎连体叫Triplet network,论文是《Deep metric learning using Triplet network》,输入是三个,一个正例+两个负例,或者一个负例+两个正例,训练的目标是让相同类别间的距离尽可能的小,让不同类别间的距离尽可能的大。如果能把四胞胎整出来就好了。下图为三胞胎的图解:

参考文章链接:
孪生神经网络(Siamese Network)详解-CSDN博客
详解Siamese网络-CSDN博客
Siamese network 孪生神经网络--一个简单神奇的结构 - 知乎 (zhihu.com)
![<span style='color:red;'>孪生</span><span style='color:red;'>神经</span><span style='color:red;'>网络</span>MATLAB实战[含源码]](https://img-blog.csdnimg.cn/img_convert/ae8a153272f4d5c7f8661809d6d1ba61.png)
![<span style='color:red;'>孪生</span><span style='color:red;'>神经</span><span style='color:red;'>网络</span>MATLAB实战[含源码]](https://img-blog.csdnimg.cn/img_convert/91db17b58ddf8dc508971b3f054b48a9.png)