目录
⭐欢迎大家订阅我的专栏一起学习⭐
🚀🚀🚀订阅专栏,更新及时查看不迷路🚀🚀🚀
💡魔改网络、复现论文、优化创新💡
原理
尽管Ultralytics 推出了最新版本的 YOLOv8 模型。但YOLOv5作为一个经典的目标检测的算法,仍经常被提及。注意力机制是提高模型性能最热门的方法之一。本次将介绍几种常见的注意力机制,这些注意力机制在大多数的数据集上均能有效的提升目标检测的精度/召回率/准确率。
CBAM注意力机制原理及代码实现
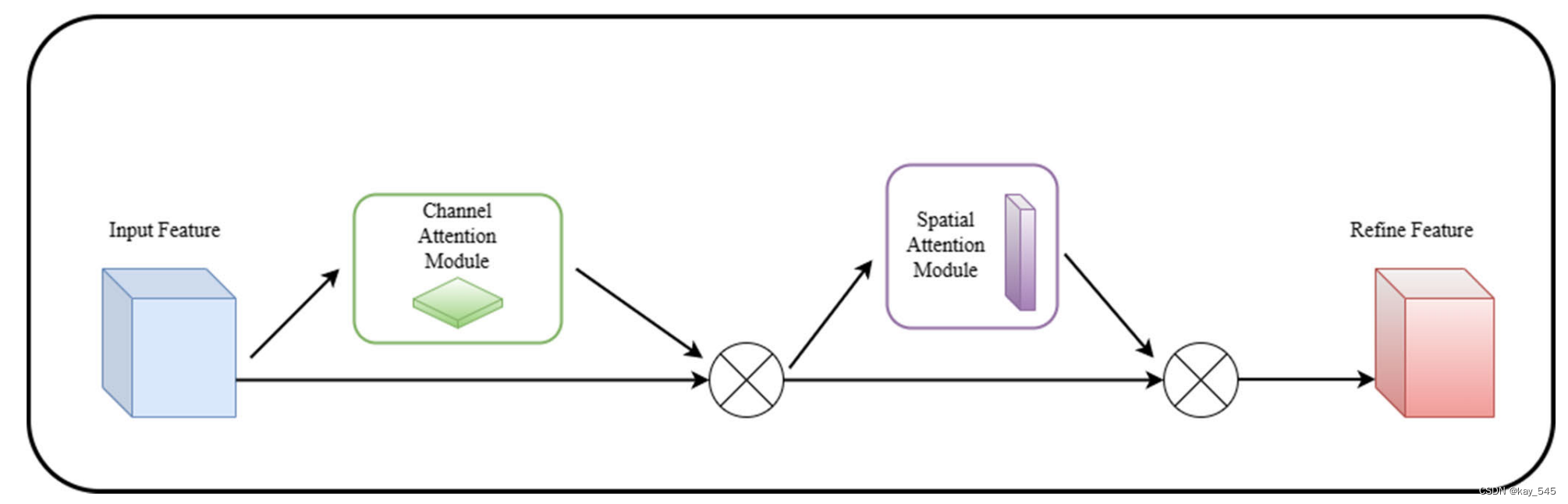
CBAM(Convolutional Block Attention Module)是一种用于卷积神经网络(CNN)的注意力机制,它能够增强网络对输入特征的关注度,提高网络性能。CBAM 主要包含两个子模块:通道注意力模块(Channel Attention Module)和空间注意力模块(Spatial Attention Module)。
以下是CBAM注意力机制的基本原理:
1. 通道注意力模块(Channel Attention Module):
输入:经过卷积层的特征图。
处理步骤:
对每个通道进行全局平均池化,得到通道的全局平均值。
通过两个全连接层,将全局平均值映射为两个权重向量(一个用于缩放,一个用于偏置)。
将这两个权重向量与原始特征图相乘,以加权调整每个通道的重要性。
2. 空间注意力模块(Spatial Attention Module):**
输入:通道注意力模块的输出。
处理步骤:
对每个通道的特征图进行分别的最大池化和平均池化,得到两个空间特征图。
将这两个空间特征图相加,通过一个卷积层产生一个权重图。
将原始特征图与权重图相乘,以加权调整每个空间位置的重要性。
3. 整合:
将通道注意力模块和空间注意力模块的输出相乘,得到最终的注意力增强特征图。
将这个注意力增强的特征图传递给网络的下一层进行进一步处理。
CBAM的关键优势在于它能够同时考虑通道和空间信息,有助于网络更好地理解和利用输入特征。这种注意力机制有助于提高网络在视觉任务上的性能,使其能够更有针对性地关注重要的特征。
代码实现
class ChannelAttention(nn.Module):
"""Channel-attention module https://github.com/open-mmlab/mmdetection/tree/v3.0.0rc1/configs/rtmdet."""
def __init__(self, channels: int) -> None:
super().__init__()
self.pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Conv2d(channels, channels, 1, 1, 0, bias=True)
self.act = nn.Sigmoid()
def forward(self, x: torch.Tensor) -> torch.Tensor:
return x * self.act(self.fc(self.pool(x)))
class SpatialAttention(nn.Module):
"""Spatial-attention module."""
def __init__(self, kernel_size=7):
"""Initialize Spatial-attention module with kernel size argument."""
super().__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.cv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.act = nn.Sigmoid()
def forward(self, x):
"""Apply channel and spatial attention on input for feature recalibration."""
return x * self.act(self.cv1(torch.cat([torch.mean(x, 1, keepdim=True), torch.max(x, 1, keepdim=True)[0]], 1)))
class CBAM(nn.Module):
"""Convolutional Block Attention Module."""
def __init__(self, c1, kernel_size=7): # ch_in, kernels
super().__init__()
self.channel_attention = ChannelAttention(c1)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
"""Applies the forward pass through C1 module."""
return self.spatial_attention(self.channel_attention(x))yaml文件
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, CBAM, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
修改后的结构图

SE注意力机制
卷积神经网络建立在卷积运算的基础上,它通过在局部感受野内将空间和通道信息融合在一起来提取信息特征。为了提高网络的表示能力,最近的几种方法已经显示了增强空间编码的好处。在这项工作中,我们专注于通道关系,并提出了一种新颖的架构单元,我们将其称为“挤压和激励”(SE)块,它通过显式建模通道之间的相互依赖性来自适应地重新校准通道方面的特征响应。我们证明,通过将这些块堆叠在一起,我们可以构建在具有挑战性的数据集上具有极好的泛化能力的 SENet 架构。至关重要的是,我们发现 SE 模块能够以最小的额外计算成本为现有最先进的深度架构带来显着的性能改进。 SENets 构成了我们 ILSVRC 2017 分类提交的基础,该分类提交赢得了第一名,并将 top-5 错误率显着降低至 2.251%,与 2016 年获胜条目相比相对提高了约 25%。
我们通过引入一个新的架构单元(我们将其称为“挤压和激励”(SE)块)来研究架构设计的另一个方面 - 通道关系。我们的目标是通过显式建模网络卷积特征通道之间的相互依赖性来提高网络的表示能力。为了实现这一目标,我们提出了一种允许网络执行特征重新校准的机制,通过该机制它可以学习使用全局信息来选择性地强调信息丰富的特征并抑制不太有用的特征。
SE结构图

SE 构建块的基本结构如图所示。对于任何给定的变换 Ftr : X → U, X ∈ RH′×W ′×C′ , U ∈ RH×W ×C ,,我们可以构建相应的 SE 块来执行特征重新校准。特征 U 首先通过挤压操作,该操作聚合跨空间维度 H × W 的特征图以生成通道描述符。该描述符嵌入了通道特征响应的全局分布,使得来自网络的全局感受野的信息能够被其较低层利用。接下来是激励操作,其中通过基于通道依赖性的自门机制为每个通道学习特定于样本的激活,控制每个通道的激励。然后对特征图 U 进行重新加权以生成 SE 块的输出,然后可以将其直接馈送到后续层中。
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
class SEConv(nn.Module):
# channel attentive convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True, reduction=16): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
self.se = SELayer(c2, reduction)
def forward(self, x):
residual = x
out = self.bn(self.conv(x))
out = self.se(out)
out += residual
return self.act(out)
class SEBottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = SEConv(c1, c_, 1, 1)
self.cv2 = SEConv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))其他注意力机制未完待续...
完整代码实现
链接: https://pan.baidu.com/s/1LYdIwI71ZLCo4GqM6L5PBg?pwd=4yr5 提取码: 4yr5
yaml文件记得选择对应的注意力机制
报错
如果报错,查看