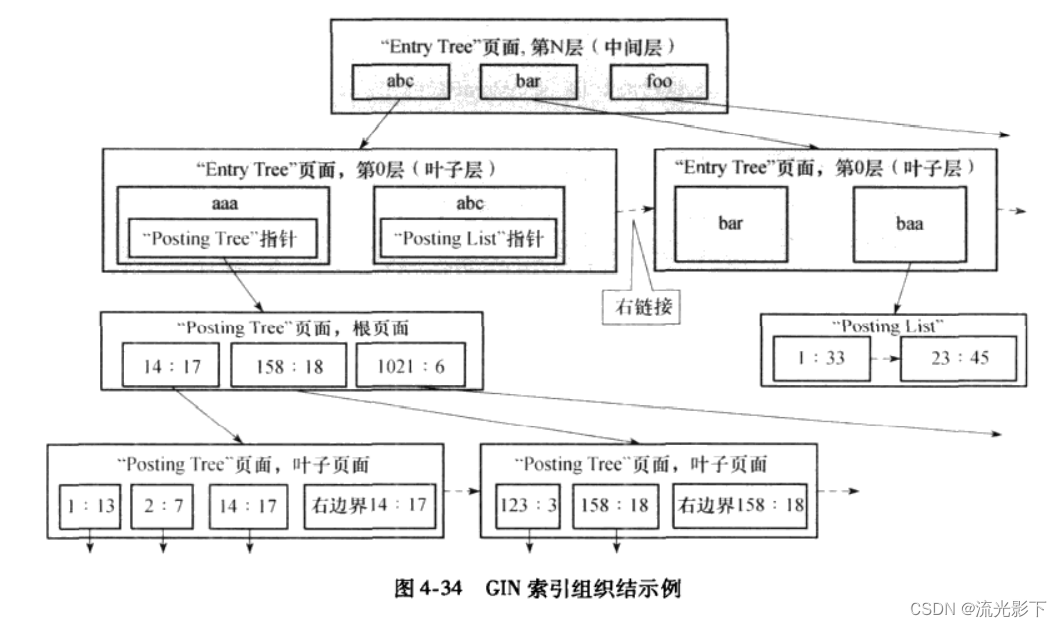
数据集踩的坑及解决方案汇总
数据集各种格式
ssd支持的训练格式为VOC和Coco
Yolo支持的训练格式:VOC或COCO
Faster R-CNN支持的训练格式:VOC或COCO
Mask R-CNN支持的训练格式:Coco
Transformer支持的训练格式:BPE。
Voc格式长这样

- JPEGImages:存放的是训练与测试的所有图片。
- Annotations(注释):数据集标签的存储路径,通过XML文件格式,为图像数据存储各类任务的标签。其中部分标签为目标检测的标签。里面存放的是每张图片打完标签所对应的XML文件。
- ImageSets:ImageSets文件夹下本次讨论的只有Main文件夹,此文件夹中存放的主要又有四个文本文件test.txt、train.txt、trainval.txt、val.txt,
其中分别存放的是测试集图片的文件名、训练集图片的文件名、训练验证集图片的文件名、验证集图片的文件名。- SegmentationClass与SegmentationObject:存放的都是图片,且都是图像分割结果图,对目标检测任务来说没有用。class
- segmentation 标注出每一个像素的类别 object segmentation 标注出每一个像素属于哪一个物体。目录如下所示
voc数据集的标签主要以xml文件形式进行存放
Coco格式长这样

- 与VOC一个文件一个xml标准不同的是,COCO所有的目标框标注都是在同一个json里。json解析出来是字典格式。
- COCO格式数据集的目录结构的train2017和val2017成为set_name,annotations文件夹中的json格式的标准文件名要与之对应并以instances_开头。
Yolo格式长这样
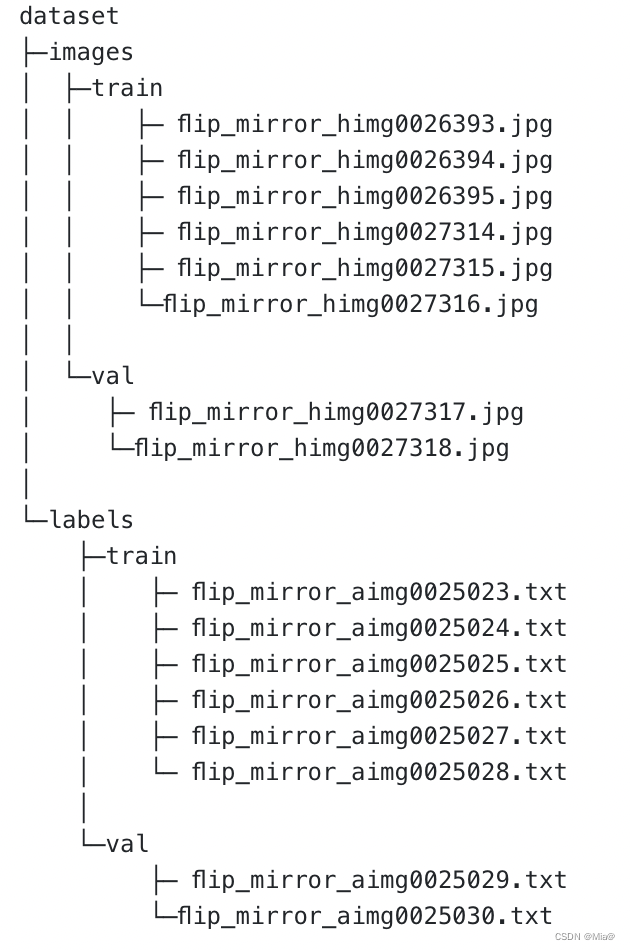
标签用txt存
更多详细介绍http://www.bryh.cn/a/330849.html
OK,接下来总结各种数据格式直接的转换方法
构建并训练自己的数据集汇总
将近期实验中数据集制作及训练的经验做如下汇总:
- Yolo系列 主要是5和7,大差不差
- Mask R-CNN 踩坑最多,最头疼
- Faster R-CNN 功;
- SSD 语法;
- ;
- 增加了 多屏幕编辑 Markdown文章功能;
- 增加了 焦点写作模式、预览模式、简洁写作模式、左右区域同步滚轮设置 等功能,功能按钮位于编辑区域与预览区域中间;
- 增加了 检查列表 功能。
Yolo系列
1、数据集标注:LabelImg
注意最终的数据集文件长这样:
2、训练
在训练过程中遇到的坑及解决方案
1>出现AssertionError:Label class 1 exceeds nc=1 in yolo/dataset.ymal Possible class labels are 0-0
注释掉train.py中下面的代码
assert mlc < nc, f'Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc - 1}'
批量将label中txt中的标签转为0的代码
mport os
txt_folder = "/Volumes/开着UU撞彗星/Git/yolov5-7.0/data-Voc-2007-1000/labels/val" # txt文件所在的文件夹路径
# 遍历txt文件列表
for txt_file in os.listdir(txt_folder):
if txt_file.endswith(".txt"):
txt_path = os.path.join(txt_folder, txt_file)
with open(txt_path, "r") as f:
lines = f.readlines()
# 修改类别索引为0
modified_lines = []
for line in lines:
line = line.strip().split()
line[0] = "0" # 将类别索引修改为0
modified_lines.append(" ".join(line))
# 将修改后的内容写回txt文件
with open(txt_path, "w") as f:
f.write("\n".join(modified_lines))
查找:Ctrl/Command + F
替换:Ctrl/Command + G
SSD
1、生成自己的数据集
参考
2、训练预测
以此类推,我们支持6级标题。有助于使用TOC语法后生成一个完美的目录。
Mask R-CNN
Mask R-CNN 需要的数据集格式长这样

加粗文本 加粗文本
1、实现labelme批量json_to_dataset方法
参考1
参考2
调试好的代码如下:
Note:需要将图片与json文件全部放在同一个文件夹My-data下
# 增加yaml文件
import argparse
import base64
import json
import os
import os.path as osp
import imgviz
import PIL.Image
from labelme.logger import logger
from labelme import utils
import glob
# 最前面加入导包
import yaml
def main():
logger.warning(
"This script is aimed to demonstrate how to convert the "
"JSON file to a single image dataset."
)
logger.warning(
"It won't handle multiple JSON files to generate a "
"real-use dataset."
)
parser = argparse.ArgumentParser()
###############################################增加的语句##############################
# parser.add_argument("json_file")
parser.add_argument("--json_dir",default="/Users/mia/Desktop/P-Clean/mask-RCNN/PennFudanPed/My-data")
###############################################end###################################
parser.add_argument("-o", "--out", default=None)
args = parser.parse_args()
###############################################增加的语句##############################
assert args.json_dir is not None and len(args.json_dir) > 0
# json_file = args.json_file
json_dir = args.json_dir
if osp.isfile(json_dir):
json_list = [json_dir] if json_dir.endswith('.json') else []
else:
json_list = glob.glob(os.path.join(json_dir, '*.json'))
###############################################end###################################
for json_file in json_list:
json_name = osp.basename(json_file).split('.')[0]
out_dir = args.out if (args.out is not None) else osp.join(osp.dirname(json_file), json_name)
###############################################end###################################
if not osp.exists(out_dir):
os.makedirs(out_dir)
data = json.load(open(json_file))
imageData = data.get("imageData")
if not imageData:
imagePath = os.path.join(os.path.dirname(json_file), data["imagePath"])
with open(imagePath, "rb") as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode("utf-8")
img = utils.img_b64_to_arr(imageData)
label_name_to_value = {"_background_": 0}
for shape in sorted(data["shapes"], key=lambda x: x["label"]):
label_name = shape["label"]
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
lbl, _ = utils.shapes_to_label(
img.shape, data["shapes"], label_name_to_value
)
label_names = [None] * (max(label_name_to_value.values()) + 1)
for name, value in label_name_to_value.items():
label_names[value] = name
lbl_viz = imgviz.label2rgb(
lbl, imgviz.asgray(img), label_names=label_names, loc="rb"
)
PIL.Image.fromarray(img).save(osp.join(out_dir, "img.png"))
utils.lblsave(osp.join(out_dir, "label.png"), lbl)
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, "label_viz.png"))
with open(osp.join(out_dir, "label_names.txt"), "w") as f:
for lbl_name in label_names:
f.write(lbl_name + "\n")
logger.info("Saved to: {}".format(out_dir))
#######
#增加了yaml生成部分
logger.warning('info.yaml is being replaced by label_names.txt')
info = dict(label_names=label_names)
with open(osp.join(out_dir, 'info.yaml'), 'w') as f:
yaml.safe_dump(info, f, default_flow_style=False)
logger.info('Saved to: {}'.format(out_dir))
if __name__ == "__main__":
main()
最后得到了这样的文件
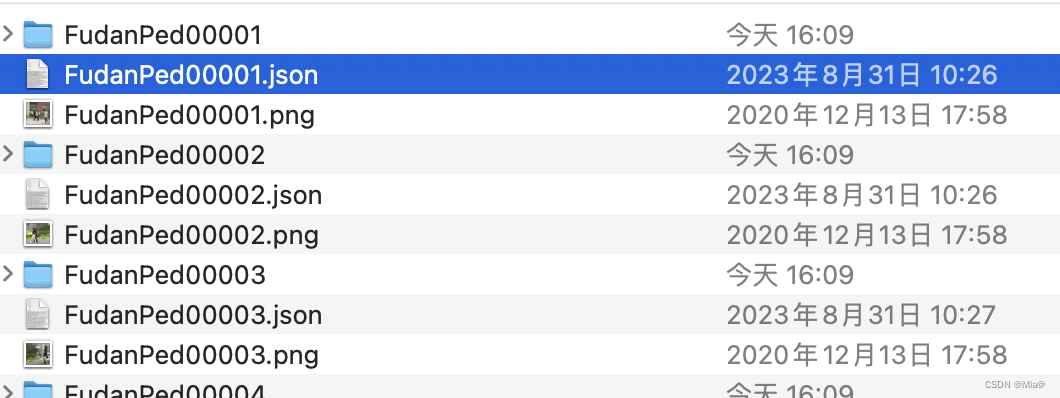
现在需要将里面的文件夹分离出来,放入名为labelme_json的文件夹下,可以将My Data文件中以.json和.png结尾的文件删除,删除代码如下:
# Python程序删除具有特定扩展名的所有文件
import os
from os import listdir
my_path = '/Users/mia/Desktop/P-Clean/mask-RCNN/PennFudanPed/labelme_json/'
for file_name in listdir(my_path):
if file_name.endswith('.json'):
os.remove(my_path + file_name)
2、生成cv2_mask内的黑图(掩码数据)
首先,将label_json文件夹中的label.png(黑图)改为原图名.png
import os
for root, dirs, names in os.walk("/Users/mia/Desktop/P-Clean/mask-RCNN/PennFudanPed/labelme_json"): # 改成你自己的labelme_json文件夹所在的目录
for dr in dirs:
file_dir = os.path.join(root, dr)
# print(dr)
file = os.path.join(file_dir, 'label.png')
# print(file)
new_name = dr.split('_')[0] + '.png'
new_file_name = os.path.join(file_dir, new_name)
os.rename(file, new_file_name)
然后,
import os
path='labelme_json'
files=os.listdir(path)
for file in files:
jpath=os.listdir(os.path.join(path,file))
# print(file[:-5])
new=file[:-5]
# print(jpath[0])
# newname=os.path.join(path,file,new)
newnames=os.path.join('cv2_mask的文件位置',new)
filename=os.path.join(path,file,jpath[0])
print(filename)
print(newnames)
os.rename(filename,newnames+'.png')
报错 NotADirectoryError: [Errno 20] Not a directory: ‘/Users/mia/Desktop/P-Clean/mask-RCNN/PennFudanPed2/labelme_json/.DS_Store’
原因:M1芯片系统设置
删除文本
引用文本
H2O is是液体。
210 运算结果是 1024.
Faster R-CNN
链接: link.
图片:
带尺寸的图片:
居中的图片:
居中并且带尺寸的图片:
当然,我们为了让用户更加便捷,我们增加了图片拖拽功能。
数据的格式转换
- txt转xml(Voc)
- 项目2
- 项目3
去博客设置页面,选择一款你喜欢的代码片高亮样式,下面展示同样高亮的代码片.
// An highlighted block
var foo = 'bar';
- 项目
- 项目
- 项目
- 项目
- 项目1
- 项目2
- 项目3
- 计划任务
- 完成任务
划分数据集
一个简单的表格是这么创建的:
| 项目 | Value |
|---|---|
| 电脑 | $1600 |
| 手机 | $12 |
| 导管 | $1 |
设定内容居中、居左、居右
使用:---------:居中
使用:----------居左
使用----------:居右
| 第一列 | 第二列 | 第三列 |
|---|---|---|
| 第一列文本居中 | 第二列文本居右 | 第三列文本居左 |
SmartyPants
SmartyPants将ASCII标点字符转换为“智能”印刷标点HTML实体。例如:
| TYPE | ASCII | HTML |
|---|---|---|
| Single backticks | 'Isn't this fun?' |
‘Isn’t this fun?’ |
| Quotes | "Isn't this fun?" |
“Isn’t this fun?” |
| Dashes | -- is en-dash, --- is em-dash |
– is en-dash, — is em-dash |
关于连接远程服务器的坑
参考1
Authors
: John
: Luke
如何创建一个注脚
一个具有注脚的文本。1
注释也是必不可少的
Markdown将文本转换为 HTML。
KaTeX数学公式
您可以使用渲染LaTeX数学表达式 KaTeX:
Gamma公式展示 Γ ( n ) = ( n − 1 ) ! ∀ n ∈ N \Gamma(n) = (n-1)!\quad\forall n\in\mathbb N Γ(n)=(n−1)!∀n∈N 是通过欧拉积分
Γ ( z ) = ∫ 0 ∞ t z − 1 e − t d t . \Gamma(z) = \int_0^\infty t^{z-1}e^{-t}dt\,. Γ(z)=∫0∞tz−1e−tdt.
你可以找到更多关于的信息 LaTeX 数学表达式here.
新的甘特图功能,丰富你的文章
- 关于 甘特图 语法,参考 这儿,
UML 图表
可以使用UML图表进行渲染。 Mermaid. 例如下面产生的一个序列图:
这将产生一个流程图。:
- 关于 Mermaid 语法,参考 这儿,
FLowchart流程图
我们依旧会支持flowchart的流程图:
- 关于 Flowchart流程图 语法,参考 这儿.
导出与导入
导出
如果你想尝试使用此编辑器, 你可以在此篇文章任意编辑。当你完成了一篇文章的写作, 在上方工具栏找到 文章导出 ,生成一个.md文件或者.html文件进行本地保存。
导入
如果你想加载一篇你写过的.md文件,在上方工具栏可以选择导入功能进行对应扩展名的文件导入,
继续你的创作。
注脚的解释 ↩︎