使用RPA工具,实现针对于原创力中不可下载文档的抓取,可延用于其他类似文库
1 使用工具、环境
影刀RPA、WPS Office、谷歌浏览器(非指定)
2 代码流程

3 关键点
此方案只适合抓取非VIP即可预览全文的文档,抓取下来的数据是图片
打开网址后,需要鼠标向下滚动一段距离才能触发“下一页”按钮:

在节点路径:“//*[@id=“main”]/div[1]/div[3]/div[2]//img”下,抓取链接(src属性),注意有些是文档中间的广告图片,有效的文档其实是“//view-cache.book118.com”开头的链接,需要过滤掉非此开头的广告链接,如下:

文档图片刷新很玄学,需要上下滑动网页才能刷新出来,代码中用了无限循环滚动鼠标+等距离上下移动来解决,检测到没有刷新时打转的“待刷新”才抓取图片链接:

判断是否抓取到最后一页,是对“继续预览”文字的检测,如果不出现就说明已经是最后一页,即可退出程序:

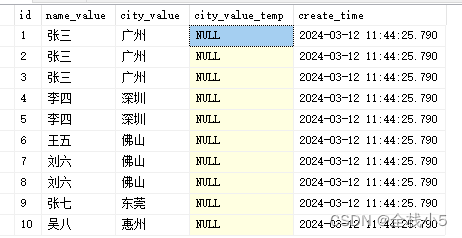
按照原文档排序命名图片,依次再插入word文档。因为影刀中列表的排序是要等字节的才能判断,所以代码中将图片的名字和对应路径,分别构造成字典的键和值,再循环1到最大值,依次取出字典的对应值,插入word文档中,实现和原文档一样的排序效果
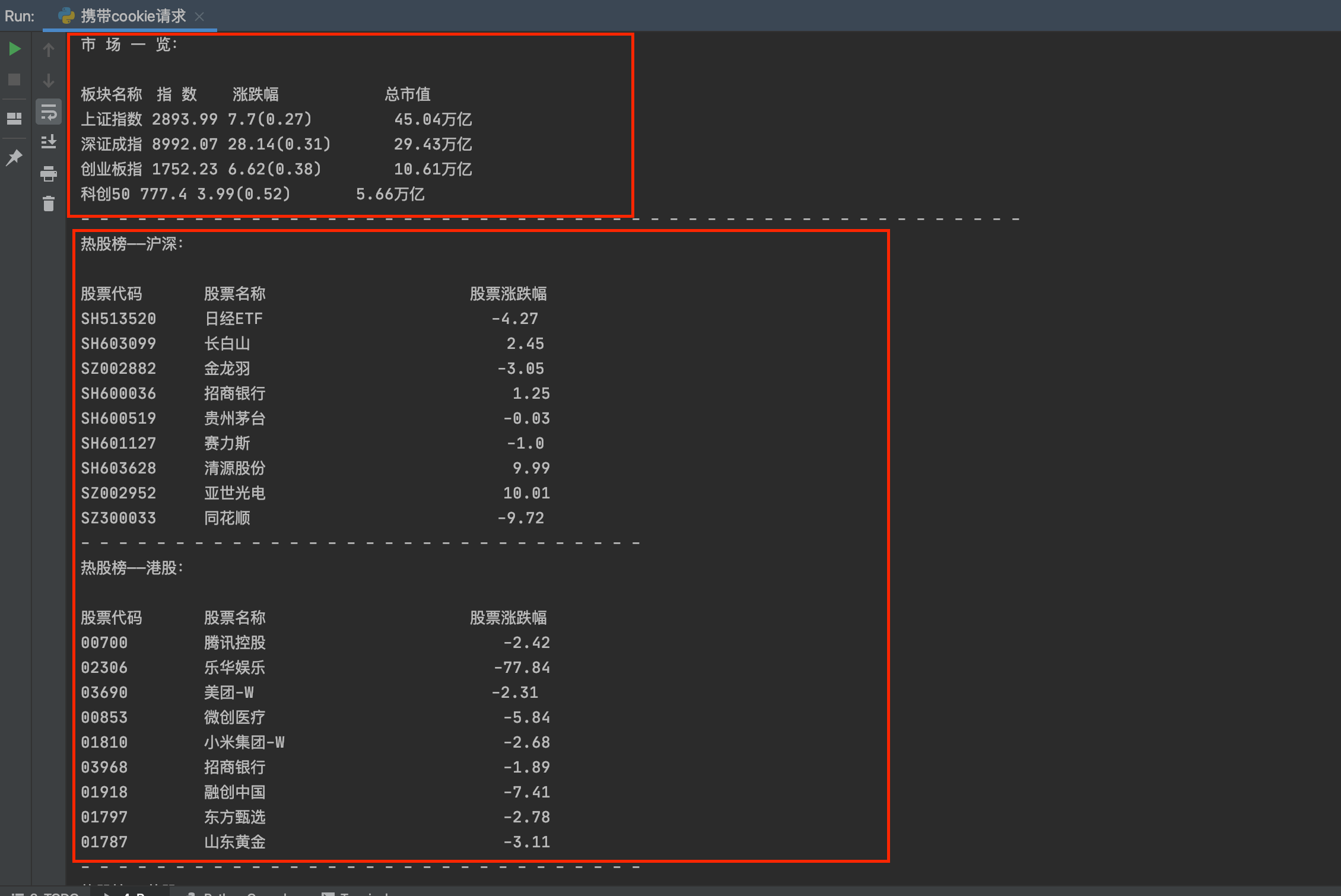
4 执行结果图

5 完整程序